Katakana
Katakana (片仮名、カタカナ, Japanese pronunciation: [katakaꜜna][note 1]) is a Japanese syllabary, one component of the Japanese writing system along with hiragana,[2] kanji and in some cases the Latin script (known as rōmaji). The word katakana means "fragmentary kana", as the katakana characters are derived from components or fragments of more complex kanji. Katakana and hiragana are both kana systems. With one or two minor exceptions, each syllable (strictly mora) in the Japanese language is represented by one character or kana, in each system. Each kana represents either a vowel such as "a" (katakana ア); a consonant followed by a vowel such as "ka" (katakana カ) or "n" (katakana ン), a nasal sonorant which, depending on the context, sounds either like English m, n or ng ([ŋ]) or like the nasal vowels of Portuguese or Galician.
| Katakana 片仮名 カタカナ | |
|---|---|
 | |
| Type | |
| Languages | Japanese, Okinawan, Ainu, Palauan[1] Taiwanese Hokkien (formerly) |
Time period | ~800 AD to the present |
Parent systems | Oracle Bone Script
|
Sister systems | Hiragana |
| Direction | Left-to-right |
| ISO 15924 | Kana, 411 |
Unicode alias | Katakana |
Unicode range |
|
 |
| Japanese writing |
|---|
| Components |
| Uses |
| Romanization |
|
Rōmaji
|
In contrast to the hiragana syllabary, which is used for Japanese words not covered by kanji and for grammatical inflections, the katakana syllabary usage is quite similar to italics in English; specifically, it is used for transcription of foreign-language words into Japanese and the writing of loan words (collectively gairaigo); for emphasis; to represent onomatopoeia; for technical and scientific terms; and for names of plants, animals, minerals and often Japanese companies.
Katakana are characterized by short, straight strokes and sharp corners. There are two main systems of ordering katakana: the old-fashioned iroha ordering and the more prevalent gojūon ordering.
Writing system
Overview
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The complete katakana script consists of 48 characters, not counting functional and diacritic marks:
- 5 nucleus vowels
- 42 core or body (onset-nucleus) syllabograms, consisting of nine consonants in combination with each of the five vowels, of which three possible combinations (yi, ye, wu) are not canonical
- 1 coda consonant
These are conceived as a 5×10 grid (gojūon, 五十音, literally "fifty sounds"), as shown in the adjacent table, read ア (a), イ (i), ウ (u), エ (e), オ (o), カ (ka), キ (ki), ク (ku), ケ (ke), コ (ko) and so on. The gojūon inherits its vowel and consonant order from Sanskrit practice. In vertical text contexts, which used to be the default case, the grid is usually presented as 10 columns by 5 rows, with vowels on the right hand side and ア (a) on top. Katakana glyphs in the same row or column do not share common graphic characteristics. Three of the syllabograms to be expected, yi, ye and wu, may have been used idiosyncratically with varying glyphs, but never became conventional in any language and are not present at all in modern Japanese.
The 50-sound table is often amended with an extra character, the nasal stop ン (n). This can appear in several positions, most often next to the N signs or, because it developed from one of many mu hentaigana, below the u column. It may also be appended to the vowel row or the a column. Here, it is shown in a table of its own.
The script includes two diacritic marks placed at the upper right of the base character that change the initial sound of a syllabogram. A double dot, called dakuten, indicates a primary alteration; most often it voices the consonant: k→g, s→z, t→d and h→b; for example, カ (ka) becomes ガ (ga). Secondary alteration, where possible, is shown by a circular handakuten: h→p; For example; ハ (ha) becomes パ (pa). Diacritics, though used for over a thousand years, only became mandatory in the Japanese writing system in the second half of the 20th century. Their application is strictly limited in proper writing systems, but may be more extensive in academic transcriptions.
Furthermore, some characters may have special semantics when used in smaller size after a normal one (see below), but this does not make the script truly bicameral.
The layout of the gojūon table promotes a systematic view of kana syllabograms as being always pronounced with the same single consonant followed by a vowel, but this is not exactly the case (and never has been). Existing schemes for the romanization of Japanese either are based on the systematic nature of the script, e.g. nihon-siki チ ti, or they apply some Western graphotactics, usually the English one, to the common Japanese pronunciation of the kana signs, e.g. Hepburn-shiki チ chi. Both approaches conceal the fact, though, that many consonant-based katakana signs, especially those canonically ending in u, can be used in coda position, too, where the vowel is unvoiced and therefore barely perceptible.
Japanese
Syllabary and orthography
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Unused or obsolete | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Of the 48 katakana syllabograms described above, only 46 are used in modern Japanese, and one of these is preserved for only a single use:
- wi and we are pronounced as vowels in modern Japanese and are therefore obsolete, having been supplanted by i and e, respectively.
- wo is now used only as a particle, and is normally pronounced the same as vowel オ o. As a particle, it is usually written in hiragana (を) and the katakana form, ヲ, is uncommon.
A small version of the katakana for ya, yu or yo (ャ, ュ or ョ, respectively) may be added to katakana ending in i. This changes the i vowel sound to a glide (palatalization) to a, u or o, e.g. キャ (ki + ya) /kja/. Addition of the small y kana is called yōon.
Small versions of the five vowel kana are sometimes used to represent trailing off sounds (ハァ haa, ネェ nee), but in katakana they are more often used in yōon-like extended digraphs designed to represent phonemes not present in Japanese; examples include チェ (che) in チェンジ chenji ("change"), ファ (fa) in ファミリー famirī ("family") and ウィ (wi) and ディ (di) in ウィキペディア Wikipedia.
A character called a sokuon, which is visually identical to a small tsu ッ, indicates that the following consonant is geminated (doubled); this is represented in rōmaji by doubling the consonant that follows the sokuon. In Japanese this is an important distinction in pronunciation; for example, compare サカ saka "hill" with サッカ sakka "author". Geminated consonants are common in transliterations of foreign loanwords; for example English "bed" is represented as ベッド (beddo). The sokuon also sometimes appears at the end of utterances, where it denotes a glottal stop. However, it cannot be used to double the na, ni, nu, ne, no syllables' consonants; to double these, the singular n (ン) is added in front of the syllable. The sokuon may also be used to approximate a non-native sound: Bach is written バッハ (Bahha); Mach as マッハ (Mahha).
Both katakana and hiragana usually spell native long vowels with the addition of a second vowel kana. However, in foreign loanwords katakana instead uses a vowel extender mark, called a chōonpu ("long vowel mark"). This is a short line (ー) following the direction of the text, horizontal for yokogaki (horizontal text), and vertical for tategaki (vertical text). For example, メール mēru is the gairaigo for e-mail taken from the English word "mail"; the ー lengthens the e. There are some exceptions, such as ローソク (rōsoku (蝋燭, "candle")) or ケータイ(kētai (携帯, "mobile phone")), where Japanese words written in katakana use the elongation mark, too.
Standard and voiced iteration marks are written in katakana as ヽ and ヾ, respectively.
Usage

In modern Japanese, katakana is most often used for transcription of words from foreign languages (other than words historically imported from Chinese), called gairaigo.[3] For example, "television" is written テレビ (terebi). Similarly, katakana is usually used for country names, foreign places, and foreign personal names. For example, the United States is usually referred to as アメリカ Amerika, rather than in its ateji kanji spelling of 亜米利加 Amerika.
Katakana are also used for onomatopoeia,[3] words used to represent sounds – for example, ピンポン (pinpon), the "ding-dong" sound of a doorbell.
Technical and scientific terms, such as the names of animal and plant species and minerals, are also commonly written in katakana.[4] Homo sapiens, as a species, is written ヒト (hito), rather than its kanji 人.
Katakana are also often (but not always) used for transcription of Japanese company names. For example, Suzuki is written スズキ, and Toyota is written トヨタ. As these are common family names, Suzuki being the second most common in Japan,[5] it helps distinguish company names from surnames in writing. Katakana are commonly used on signs, advertisements, and hoardings (i.e., billboards), for example, ココ koko ("here"), ゴミ gomi ("trash"), or メガネ megane ("glasses"). Words the writer wishes to emphasize in a sentence are also sometimes written in katakana, mirroring the European usage of italics.[3]
Pre–World War II official documents mix katakana and kanji in the same way that hiragana and kanji are mixed in modern Japanese texts, that is, katakana were used for okurigana and particles such as wa or o.
Katakana were also used for telegrams in Japan before 1988, and for computer systems – before the introduction of multibyte characters – in the 1980s. Most computers of that era used katakana instead of kanji or hiragana for output.
Although words borrowed from ancient Chinese are usually written in kanji, loanwords from modern Chinese dialects which are borrowed directly use katakana instead.
| Japanese | Rōmaji | Meaning | Chinese | Romanization | Source language |
|---|---|---|---|---|---|
| マージャン | mājan | mahjong | 麻將 | májiàng | Mandarin |
| ウーロン茶 | ūroncha | Oolong tea | 烏龍茶 | wūlóngchá | |
| チャーハン | chāhan | fried rice | 炒飯 | chǎofàn | |
| チャーシュー | chāshū | barbecued pork | 叉燒 | chā sīu | Cantonese |
| シューマイ | shūmai | shumai | 燒賣 | sīu máai |
The very common Chinese loanword rāmen, written in katakana as ラーメン, is rarely written with its kanji (拉麺).
There are rare instances where the opposite has occurred, with kanji forms created from words originally written in katakana. An example of this is コーヒー kōhī, ("coffee"), which can alternatively be written as 珈琲. This kanji usage is occasionally employed by coffee manufacturers or coffee shops for novelty.
Katakana are used to indicate the on'yomi (Chinese-derived readings) of a kanji in a kanji dictionary. For instance, the kanji 人 has a Japanese pronunciation, written in hiragana as ひと hito (person), as well as a Chinese derived pronunciation, written in katakana as ジン jin (used to denote groups of people). Katakana are sometimes used instead of hiragana as furigana to give the pronunciation of a word written in Roman characters, or for a foreign word, which is written as kanji for the meaning, but intended to be pronounced as the original.
.jpg)
Katakana are also sometimes used to indicate words being spoken in a foreign or otherwise unusual accent. For example, in a manga, the speech of a foreign character or a robot may be represented by コンニチワ konnichiwa ("hello") instead of the more typical hiragana こんにちは. Some Japanese personal names are written in katakana. This was more common in the past, hence elderly women often have katakana names. This was particularly common among women in the Meiji and Taishō periods, when many poor, illiterate parents were unwilling to pay a scholar to give their daughters names in kanji.[6] Katakana is also used to denote the fact that a character is speaking a foreign language, and what is displayed in katakana is only the Japanese "translation" of his or her words.
Some frequently used words may also be written in katakana in dialogs to convey an informal, conversational tone. Some examples include マンガ ("manga"), アイツ aitsu ("that guy or girl; he/him; her"), バカ baka ("fool"), etc.
Words with difficult-to-read kanji are sometimes written in katakana (hiragana is also used for this purpose). This phenomenon is often seen with medical terminology. For example, in the word 皮膚科 hifuka ("dermatology"), the second kanji, 膚, is considered difficult to read, and thus the word hifuka is commonly written 皮フ科 or ヒフ科, mixing kanji and katakana. Similarly, difficult-to-read kanji such as 癌 gan ("cancer") are often written in katakana or hiragana.
Katakana is also used for traditional musical notations, as in the Tozan-ryū of shakuhachi, and in sankyoku ensembles with koto, shamisen and shakuhachi.
Some instructors teaching Japanese as a foreign language "introduce katakana after the students have learned to read and write sentences in hiragana without difficulty and know the rules."[7] Most students who have learned hiragana "do not have great difficulty in memorizing" katakana as well.[8] Other instructors introduce katakana first, because these are used with loanwords. This gives students a chance to practice reading and writing kana with meaningful words. This was the approach taken by the influential American linguistics scholar Eleanor Harz Jorden in Japanese: The Written Language (parallel to Japanese: The Spoken Language).[9]
Ainu
Katakana is commonly used by Japanese linguists to write the Ainu language. In Ainu katakana usage, the consonant that comes at the end of a syllable is represented by a small version of a katakana that corresponds to that final consonant followed by an arbitrary vowel. For instance "up" is represented by ウㇷ゚ (ウプ [u followed by small pu]). Ainu also uses three handakuten modified katakana, セ゚ ([tse]), and ツ゚ or ト゚ ([tu̜]). In Unicode, the Katakana Phonetic Extensions block (U+31F0–U+31FF) exists for Ainu language support. These characters are used for the Ainu language only.
Taiwanese
Taiwanese kana (タイ![]()
![]()
![]()
![]()
![]()
Unlike Japanese or Ainu, Taiwanese kana are used similarly to the Zhùyīn fúhào characters, with kana serving as initials, vowel medials and consonant finals, marked with tonal marks. A dot below the initial kana represents aspirated consonants, and チ, ツ, サ, セ, ソ, ウ and オ with a superpositional bar represent sounds found only in Taiwanese.
Okinawan
Katakana is used as a phonetic guide for the Okinawan language, unlike the various other systems to represent Okinawan, which use hiragana with extensions. The system was devised by the Okinawa Center of Language Study of the University of the Ryukyus. It uses many extensions and yōon to show the many non-Japanese sounds of Okinawan.
Table of katakana
This is a table of katakana together with their Hepburn romanization and rough IPA transcription for their use in Japanese. Katakana with dakuten or handakuten follow the gojūon kana without them.
Characters shi シ and tsu ツ, and so ソ and n(g) ン, look very similar in print except for the slant and stroke shape. These differences in slant and shape are more prominent when written with an ink brush.
Grey background indicates obsolete characters.
| Monographs (gojūon) | Digraphs (yōon) | |||||||
|---|---|---|---|---|---|---|---|---|
| a | i | u | e | o | ya | yu | yo | |
| ∅ | ア a [a] |
イ i [i] |
ウ u [ɯ] |
エ e [e] |
オ o [o] |
|||
| K | カ ka [ka] |
キ ki [ki] |
ク ku [kɯ] |
ケ ke [ke] |
コ ko [ko] |
キャ kya [kʲa] |
キュ kyu [kʲɯ] |
キョ kyo [kʲo] |
| S | サ sa [sa] |
シ shi [ɕi] |
ス su [sɯ] |
セ se [se] |
ソ so [so] |
シャ sha [ɕa] |
シュ shu [ɕɯ] |
ショ sho [ɕo] |
| T | タ ta [ta] |
チ chi [t͡ɕi] |
ツ tsu [t͡sɯ] |
テ te [te] |
ト to [to] |
チャ cha [t͡ɕa] |
チュ chu [t͡ɕɯ] |
チョ cho [t͡ɕo] |
| N | ナ na [na] |
ニ ni [ɲi] |
ヌ nu [nɯ] |
ネ ne [ne] |
ノ no [no] |
ニャ nya [ɲa] |
ニュ nyu [ɲɯ] |
ニョ nyo [ɲo] |
| H | ハ ha [ha] |
ヒ hi [çi] |
フ fu [ɸɯ] |
ヘ he [he] |
ホ ho [ho] |
ヒャ hya [ça] |
ヒュ hyu [çɯ] |
ヒョ hyo [ço] |
| M | マ ma [ma] |
ミ mi [mi] |
ム mu [mɯ] |
メ me [me] |
モ mo [mo] |
ミャ mya [mʲa] |
ミュ myu [mʲɯ] |
ミョ myo [mʲo] |
| Y | ヤ ya [ja] |
[n 1] | ユ yu [jɯ] |
[n 1] | ヨ yo [jo] |
|||
| R | ラ ra [ɾa] |
リ ri [ɾi] |
ル ru [ɾɯ] |
レ re [ɾe] |
ロ ro [ɾo] |
リャ rya [ɾʲa] |
リュ ryu [ɾʲɯ] |
リョ ryo [ɾʲo] |
| W | ワ wa [ɰa] |
ヰ wi [i][n 2] |
[n 1] | ヱ we [e][n 2] |
ヲ wo [o][n 2] |
|||
| Final nasal monograph | Functional graphemes | |||||||
| ン n [n m ŋ] before stop consonants; [ɴ ɰ̃] elsewhere |
ッ (before geminate consonant) |
ー (after long vowel) |
ヽ (reduplicates and unvoices syllable) |
ヾ (reduplicates and voices syllable) | ||||
| Monographs with diacritics: gojūon with (han)dakuten | Digraphs with diacritics: yōon with (han)dakuten | |||||||
| a | i | u | e | o | ya | yu | yo | |
| G | ガ ga [ɡa] |
ギ gi [ɡi] |
グ gu [ɡɯ] |
ゲ ge [ɡe] |
ゴ go [ɡo] |
ギャ gya [ɡʲa] |
ギュ gyu [ɡʲɯ] |
ギョ gyo [ɡʲo] |
| Z | ザ za [za] |
ジ ji [(d)ʑi] |
ズ zu [(d)zɯ] |
ゼ ze [ze] |
ゾ zo [zo] |
ジャ ja [(d)ʑa] |
ジュ ju [(d)ʑɯ] |
ジョ jo [(d)ʑo] |
| D | ダ da [da] |
ヂ ji [(d)ʑi][n 3] |
ヅ zu [(d)zɯ][n 3] |
デ de [de] |
ド do [do] |
ヂャ ja [(d)ʑa][n 3] |
ヂュ ju [(d)ʑɯ][n 3] |
ヂョ jo [(d)ʑo][n 3] |
| B | バ ba [ba] |
ビ bi [bi] |
ブ bu [bɯ] |
ベ be [be] |
ボ bo [bo] |
ビャ bya [bʲa] |
ビュ byu [bʲɯ] |
ビョ byo [bʲo] |
| P | パ pa [pa] |
ピ pi [pi] |
プ pu [pɯ] |
ペ pe [pe] |
ポ po [po] |
ピャ pya [pʲa] |
ピュ pyu [pʲɯ] |
ピョ pyo [pʲo] |
Notes
- Theoretical combinations yi, ye and wu are unused .
- The characters in positions wi and we are obsolete in modern Japanese, and have been replaced by イ (i) and エ (e). The character wo, in practice normally pronounced o, is preserved in only one use: as a particle. This is normally written in hiragana (を), so katakana ヲ sees only limited use. See Gojūon and the articles on each character for details.
- The ヂ (di) and ヅ (du) kana (often romanised as ji and zu) are primarily used for etymologic spelling , when the unvoiced equivalents チ (ti) and ツ (tu) (often romanised as chi and tsu) undergo a sound change (rendaku) and become voiced when they occur in the middle of a compound word. In other cases, the identically-pronounced ジ (ji) and ズ (zu) are used instead. ヂ (di) and ヅ (du) can never begin a word, and they are not common in katakana, since the concept of rendaku does not apply to transcribed foreign words, one of the major uses of katakana.
History
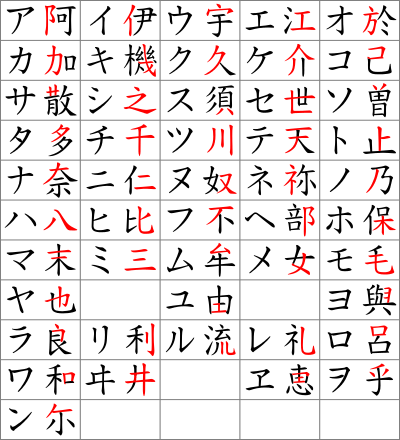
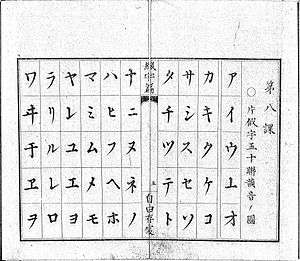

Katakana was developed in the 9th century (during the early Heian period) by Buddhist monks by taking parts of man'yōgana characters as a form of shorthand, hence this kana is so-called kata (片, "partial, fragmented").
For example, ka (カ) comes from the left side of ka (加, lit. "increase", but the original meaning is no longer applicable to kana). The adjacent table shows the origins of each katakana: the red markings of the original Chinese character (used as man'yōgana) eventually became each corresponding symbol.[10]
Early on, katakana was almost exclusively used by men for official text and text imported from China.[11]
Official documents of the Empire of Japan were written exclusively with kyūjitai and katakana.
Recent findings by Yoshinori Kobayashi, professor of Japanese at Tokushima Bunri University, suggest the possibility that the katakana-like annotations used in reading guide marks (乎古止点 / ヲコト点, okototen) may have originated in 8th-century Korea – possibly Silla – and then introduced to Japan through Buddhist texts.[12][13]
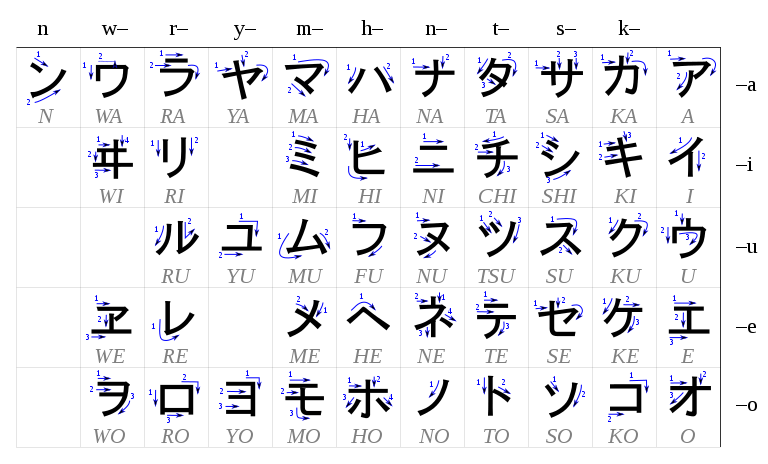
Stroke order
The following table shows the method for writing each katakana character. It is arranged in the traditional way, beginning top right and reading columns down. The numbers and arrows indicate the stroke order and direction, respectively.
Computer encoding
In addition to fonts intended for Japanese text and Unicode catch-all fonts (like Arial Unicode MS), many fonts intended for Chinese (such as MS Song) and Korean (such as Batang) also include katakana.
Half-width kana
In addition to the usual full-width (全角, zenkaku) display forms of characters, katakana has a second form, half-width (半角, hankaku) (there are no kanji). The half-width forms were originally associated with the JIS X 0201 encoding. Although their display form is not specified in the standard, in practice they were designed to fit into the same rectangle of pixels as Roman letters to enable easy implementation on the computer equipment of the day. This space is narrower than the square space traditionally occupied by Japanese characters, hence the name "half-width". In this scheme, diacritics (dakuten and handakuten) are separate characters. When originally devised, the half-width katakana were represented by a single byte each, as in JIS X 0201, again in line with the capabilities of contemporary computer technology.
In the late 1970s, two-byte character sets such as JIS X 0208 were introduced to support the full range of Japanese characters, including katakana, hiragana and kanji. Their display forms were designed to fit into an approximately square array of pixels, hence the name "full-width". For backwards compatibility, separate support for half-width katakana has continued to be available in modern multi-byte encoding schemes such as Unicode, by having two separate blocks of characters – one displayed as usual (full-width) katakana, the other displayed as half-width katakana.
Although often said to be obsolete, the half-width katakana are still used in many systems and encodings. For example, the titles of mini discs can only be entered in ASCII or half-width katakana, and half-width katakana are commonly used in computerized cash register displays, on shop receipts, and Japanese digital television and DVD subtitles. Several popular Japanese encodings such as EUC-JP, Unicode and Shift JIS have half-width katakana code as well as full-width. By contrast, ISO-2022-JP has no half-width katakana, and is mainly used over SMTP and NNTP.
Unicode
Katakana was added to the Unicode Standard in October, 1991 with the release of version 1.0.
The Unicode block for (full-width) katakana is U+30A0–U+30FF.
Encoded in this block along with the katakana are the nakaguro word-separation middle dot, the chōon vowel extender, the katakana iteration marks, and a ligature of コト sometimes used in vertical writing.
| Katakana[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+30Ax | ゠ | ァ | ア | ィ | イ | ゥ | ウ | ェ | エ | ォ | オ | カ | ガ | キ | ギ | ク |
| U+30Bx | グ | ケ | ゲ | コ | ゴ | サ | ザ | シ | ジ | ス | ズ | セ | ゼ | ソ | ゾ | タ |
| U+30Cx | ダ | チ | ヂ | ッ | ツ | ヅ | テ | デ | ト | ド | ナ | ニ | ヌ | ネ | ノ | ハ |
| U+30Dx | バ | パ | ヒ | ビ | ピ | フ | ブ | プ | ヘ | ベ | ペ | ホ | ボ | ポ | マ | ミ |
| U+30Ex | ム | メ | モ | ャ | ヤ | ュ | ユ | ョ | ヨ | ラ | リ | ル | レ | ロ | ヮ | ワ |
| U+30Fx | ヰ | ヱ | ヲ | ン | ヴ | ヵ | ヶ | ヷ | ヸ | ヹ | ヺ | ・ | ー | ヽ | ヾ | ヿ |
Notes
| ||||||||||||||||
Half-width equivalents to the usual full-width katakana also exist in Unicode. These are encoded within the Halfwidth and Fullwidth Forms block (U+FF00–U+FFEF) (which also includes full-width forms of Latin characters, for instance), starting at U+FF65 and ending at U+FF9F (characters U+FF61–U+FF64 are half-width punctuation marks). This block also includes the half-width dakuten and handakuten. The full-width versions of these characters are found in the Hiragana block.
| Katakana subset of Halfwidth and Fullwidth Forms[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| ... | (U+FF00–U+FF64 omitted) | |||||||||||||||
| U+FF6x | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |||||
| U+FF7x | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| U+FF8x | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| U+FF9x | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
| ... | (U+FFA0–U+FFEF omitted) | |||||||||||||||
Notes
| ||||||||||||||||
Circled katakana are code points U+32D0–U+32FE in the Enclosed CJK Letters and Months block (U+3200–U+32FF). A circled ン (n) is not included.
| Katakana subset of Enclosed CJK Letters and Months[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| ... | (U+3200–U+32CF omitted) | |||||||||||||||
| U+32Dx | ㋐ | ㋑ | ㋒ | ㋓ | ㋔ | ㋕ | ㋖ | ㋗ | ㋘ | ㋙ | ㋚ | ㋛ | ㋜ | ㋝ | ㋞ | ㋟ |
| U+32Ex | ㋠ | ㋡ | ㋢ | ㋣ | ㋤ | ㋥ | ㋦ | ㋧ | ㋨ | ㋩ | ㋪ | ㋫ | ㋬ | ㋭ | ㋮ | ㋯ |
| U+32Fx | ㋰ | ㋱ | ㋲ | ㋳ | ㋴ | ㋵ | ㋶ | ㋷ | ㋸ | ㋹ | ㋺ | ㋻ | ㋼ | ㋽ | ㋾ | ㋿ |
Notes
| ||||||||||||||||
Extensions to Katakana for phonetic transcription of Ainu and other languages were added to the Unicode standard in March 2002 with the release of version 3.2.
The Unicode block for Katakana Phonetic Extensions is U+31F0–U+31FF:
| Katakana Phonetic Extensions[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+31Fx | ㇰ | ㇱ | ㇲ | ㇳ | ㇴ | ㇵ | ㇶ | ㇷ | ㇸ | ㇹ | ㇺ | ㇻ | ㇼ | ㇽ | ㇾ | ㇿ |
Notes
| ||||||||||||||||
Historic and variant forms of Japanese kana characters were added to the Unicode standard in October 2010 with the release of version 6.0.
The Unicode block for Kana Supplement is U+1B000–U+1B0FF:
| Kana Supplement[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1B00x | 𛀀 | 𛀁 | 𛀂 | 𛀃 | 𛀄 | 𛀅 | 𛀆 | 𛀇 | 𛀈 | 𛀉 | 𛀊 | 𛀋 | 𛀌 | 𛀍 | 𛀎 | 𛀏 |
| U+1B01x | 𛀐 | 𛀑 | 𛀒 | 𛀓 | 𛀔 | 𛀕 | 𛀖 | 𛀗 | 𛀘 | 𛀙 | 𛀚 | 𛀛 | 𛀜 | 𛀝 | 𛀞 | 𛀟 |
| U+1B02x | 𛀠 | 𛀡 | 𛀢 | 𛀣 | 𛀤 | 𛀥 | 𛀦 | 𛀧 | 𛀨 | 𛀩 | 𛀪 | 𛀫 | 𛀬 | 𛀭 | 𛀮 | 𛀯 |
| U+1B03x | 𛀰 | 𛀱 | 𛀲 | 𛀳 | 𛀴 | 𛀵 | 𛀶 | 𛀷 | 𛀸 | 𛀹 | 𛀺 | 𛀻 | 𛀼 | 𛀽 | 𛀾 | 𛀿 |
| U+1B04x | 𛁀 | 𛁁 | 𛁂 | 𛁃 | 𛁄 | 𛁅 | 𛁆 | 𛁇 | 𛁈 | 𛁉 | 𛁊 | 𛁋 | 𛁌 | 𛁍 | 𛁎 | 𛁏 |
| U+1B05x | 𛁐 | 𛁑 | 𛁒 | 𛁓 | 𛁔 | 𛁕 | 𛁖 | 𛁗 | 𛁘 | 𛁙 | 𛁚 | 𛁛 | 𛁜 | 𛁝 | 𛁞 | 𛁟 |
| U+1B06x | 𛁠 | 𛁡 | 𛁢 | 𛁣 | 𛁤 | 𛁥 | 𛁦 | 𛁧 | 𛁨 | 𛁩 | 𛁪 | 𛁫 | 𛁬 | 𛁭 | 𛁮 | 𛁯 |
| U+1B07x | 𛁰 | 𛁱 | 𛁲 | 𛁳 | 𛁴 | 𛁵 | 𛁶 | 𛁷 | 𛁸 | 𛁹 | 𛁺 | 𛁻 | 𛁼 | 𛁽 | 𛁾 | 𛁿 |
| U+1B08x | 𛂀 | 𛂁 | 𛂂 | 𛂃 | 𛂄 | 𛂅 | 𛂆 | 𛂇 | 𛂈 | 𛂉 | 𛂊 | 𛂋 | 𛂌 | 𛂍 | 𛂎 | 𛂏 |
| U+1B09x | 𛂐 | 𛂑 | 𛂒 | 𛂓 | 𛂔 | 𛂕 | 𛂖 | 𛂗 | 𛂘 | 𛂙 | 𛂚 | 𛂛 | 𛂜 | 𛂝 | 𛂞 | 𛂟 |
| U+1B0Ax | 𛂠 | 𛂡 | 𛂢 | 𛂣 | 𛂤 | 𛂥 | 𛂦 | 𛂧 | 𛂨 | 𛂩 | 𛂪 | 𛂫 | 𛂬 | 𛂭 | 𛂮 | 𛂯 |
| U+1B0Bx | 𛂰 | 𛂱 | 𛂲 | 𛂳 | 𛂴 | 𛂵 | 𛂶 | 𛂷 | 𛂸 | 𛂹 | 𛂺 | 𛂻 | 𛂼 | 𛂽 | 𛂾 | 𛂿 |
| U+1B0Cx | 𛃀 | 𛃁 | 𛃂 | 𛃃 | 𛃄 | 𛃅 | 𛃆 | 𛃇 | 𛃈 | 𛃉 | 𛃊 | 𛃋 | 𛃌 | 𛃍 | 𛃎 | 𛃏 |
| U+1B0Dx | 𛃐 | 𛃑 | 𛃒 | 𛃓 | 𛃔 | 𛃕 | 𛃖 | 𛃗 | 𛃘 | 𛃙 | 𛃚 | 𛃛 | 𛃜 | 𛃝 | 𛃞 | 𛃟 |
| U+1B0Ex | 𛃠 | 𛃡 | 𛃢 | 𛃣 | 𛃤 | 𛃥 | 𛃦 | 𛃧 | 𛃨 | 𛃩 | 𛃪 | 𛃫 | 𛃬 | 𛃭 | 𛃮 | 𛃯 |
| U+1B0Fx | 𛃰 | 𛃱 | 𛃲 | 𛃳 | 𛃴 | 𛃵 | 𛃶 | 𛃷 | 𛃸 | 𛃹 | 𛃺 | 𛃻 | 𛃼 | 𛃽 | 𛃾 | 𛃿 |
Notes
| ||||||||||||||||
The Unicode block for Small Kana Extension is U+1B130–U+1B16F:
| Small Kana Extension[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1B13x | ||||||||||||||||
| U+1B14x | ||||||||||||||||
| U+1B15x | 𛅐 | 𛅑 | 𛅒 | |||||||||||||
| U+1B16x | 𛅤 | 𛅥 | 𛅦 | 𛅧 | ||||||||||||
| Notes | ||||||||||||||||
Katakana in other Unicode blocks:
- Dakuten and handakuten diacritics are located in the Hiragana block:
- U+3099 COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK (non-spacing dakuten): ゙
- U+309A COMBINING KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK (non-spacing handakuten): ゚
- U+309B KATAKANA-HIRAGANA VOICED SOUND MARK (spacing dakuten): ゛
- U+309C KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK (spacing handakuten): ゜
- Two katakana-based emoji are in the Enclosed Ideographic Supplement block:
- U+1F201 SQUARED KATAKANA KOKO ('here' sign): 🈁
- U+1F202 SQUARED KATAKANA SA ('service' sign): 🈂
- A katakana-based Japanese TV symbol from the ARIB STD-B24 standard is in the Enclosed Ideographic Supplement block:
- U+1F213 SQUARED KATAKANA DE ('data broadcasting service linked with a main program' symbol): 🈓
Furthermore, as of Unicode 13.0, the following combinatory sequences have been explicitly named, despite having no precomposed symbols in the katakana block. Font designers may want to optimize the display of these composed glyphs. Some of them are mostly used for writing the Ainu language, the others are called bidakuon in Japanese. Other, arbitrary combinations with U+309A handakuten are also possible.
| Katakana named sequences Unicode Named Character Sequences Database | ||||||||||||||||
| Sequence name | Codepoints | Glyph | ||||||||||||||
| KATAKANA LETTER BIDAKUON NGA | U+30AB | U+309A | カ゚ | |||||||||||||
| KATAKANA LETTER BIDAKUON NGI | U+30AD | U+309A | キ゚ | |||||||||||||
| KATAKANA LETTER BIDAKUON NGU | U+30AF | U+309A | ク゚ | |||||||||||||
| KATAKANA LETTER BIDAKUON NGE | U+30B1 | U+309A | ケ゚ | |||||||||||||
| KATAKANA LETTER BIDAKUON NGO | U+30B3 | U+309A | コ゚ | |||||||||||||
| KATAKANA LETTER AINU CE | U+30BB | U+309A | セ゚ | |||||||||||||
| KATAKANA LETTER AINU TU | U+30C4 | U+309A | ツ゚ | |||||||||||||
| KATAKANA LETTER AINU TO | U+30C8 | U+309A | ト゚ | |||||||||||||
| KATAKANA LETTER AINU P | U+31F7 | U+309A | ㇷ゚ | |||||||||||||
See also
- Japanese phonology
- Hiragana
- Historical kana usage
- Rōmaji
- Gugyeol
- Tōdaiji Fujumonkō, oldest example of kanji text with katakana annotations
- File:Beschrijving van Japan - ABC (cropped).jpg for the kana as described by Engelbert Kaempfer in 1727
Notes
- Also [kataꜜkana].
References
- Thomas E. McAuley (2001) Language change in East Asia. Routledge. ISBN 0700713778. p. 90
- Roy Andrew Miller (1966) A Japanese Reader: Graded Lessons in the Modern Language, Rutland, Vermont: Charles E. Tuttle Company, Tokyo, Japan, p. 28, Lesson 7 : Katakana : a—no. "Side by side with hiragana, modern Japanese writing makes use of another complete set of similar symbols called the katakana."
- "The Japanese Writing System (2) Katakana", p. 29 in Yookoso! An Invitation to Contemporary Japanese. McGraw-Hill, 1993, ISBN 0070722935
- "Hiragana, Katakana & Kanji". Japanese Word Characters. 8 September 2010. Retrieved 15 October 2011.
- "明治安田生命 全国同姓調査 [Meiji Yasuda Life Insurance Company - National same family name investigation]" (PDF) (Press release). Meiji Yasuda Life Insurance Company. 24 September 2008. Archived from the original (PDF) on 17 January 2012. Retrieved 24 May 2018.
- Tackett, Rachel. "Why old Japanese women have names in katakana". RocketNews24. Retrieved 19 September 2015.
- Mutsuko Endo Simon (1984) Section 3.3 "Katakana", p. 36 in A Practical Guide for Teachers of Elementary Japanese, Center for Japanese Studies, the University of Michigan. ISBN 0939512165
- Simon, p. 36
- Reading Japanese, Lesson 1. joyo96.org
- Japanese katakana. Omniglot.com
- Taku Sugimoto; James A. Levin (2000). "Global Literacies and the World-Wide Web". London: Routledge. p. 137. Missing or empty
|url=(help) - Japan Times, "Katakana system may be Korean, professor says"
- Yoshinori Kobayashi, 日本のヲコト点の起源と古代韓国語の点吐との関係 ("Relationship between tento in Ancient Korean and the origin of Japan's okoto point)
External links
| Wikimedia Commons has media related to: |
| Look up katakana in Wiktionary, the free dictionary. |