Tsu (kana)
つ, in hiragana, or ツ in katakana, is one of the Japanese kana, each of which represents one mora. Both are phonemically /tu͍/ although for phonological reasons, the actual pronunciation is [tsɯ] (![]()
| tsu | ||||
|---|---|---|---|---|
| ||||
| transliteration | tsu, tu | |||
| translit. with dakuten | zu, dzu, du | |||
| hiragana origin | 川 | |||
| katakana origin | 川 | |||
| spelling kana | つるかめのツ (Tsurukame no "tsu") | |||
| unicode | U+3064, U+30C4 | |||
| braille | ||||


| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
The small kana っ/ッ, known as sokuon, are identical but somewhat smaller. They are mainly used to indicate consonant gemination and commonly used at the end of lines of dialogue in fictional works as a symbol for a glottal stop.
The dakuten forms づ, ヅ, pronounced the same as the dakuten forms of the su kana in most dialects (see yotsugana), are uncommon. They are primarily used for indicating a voiced consonant in the middle of a compound word (see rendaku), and they can never begin a word.
In the Ainu language, it can be written with a handakuten (which can be entered into a computer as either one character (ツ゚) or two combined characters (ツ゜) to represent the sound [tu͍], which is interchangeable with the katakana ト゚.
The katakana form has become popular as an emoticon in the Western world due to its resemblance to a smiling face and as part of the "shrug" emoji, rendered as: ¯\_(ツ)_/¯ .[1][2]
| Forms | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal ts- (た行 ta-gyō) |
tsu | つ | ツ |
| tsuu tsū |
つう, つぅ つー |
ツウ, ツゥ ツー | |
| Addition dakuten d/z- (だ行 da-gyō) |
du, zu, dzu |
づ | ヅ |
| duu, zuu dzuu, dū zū, dzū |
づう, づぅ づー |
ヅウ, ヅゥ ヅー |
| Other additional forms | ||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||||||||||||||||||||||||
- ヅァ, ヅェ and ヅォ are used in gairaigos, these pronunciations are not same as ズァ (zwa), ズェ (zwe) and ズォ (zwo).
Stroke order
 Stroke order in writing つ |
 Stroke order in writing ツ |
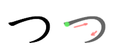

Other communicative representations
| Japanese radiotelephony alphabet | Wabun code |
| つるかめのツ Tsurukame no "Tsu" |
 |
|
 |
 |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-1345 Japanese Braille |
- Full Braille representation
| つ / ツ in Japanese Braille | ||||||||
|---|---|---|---|---|---|---|---|---|
| っ / ッ sokuon | つ / ツ tsu | づ / ヅ zu/du | つう / ツー tsū | づう / ヅー zū/dū | Other kana based on Braille つ | |||
| ちゅ / チュ chu | ぢゅ / ヂュ ju/dyu | ちゅう / チュー chū | ぢゅう / ヂュー jū/dyū | |||||
| Preview | つ | ツ | ツ | っ | ッ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER TU | KATAKANA LETTER TU | HALFWIDTH KATAKANA LETTER TU | HIRAGANA LETTER SMALL TU | KATAKANA LETTER SMALL TU | |||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12388 | U+3064 | 12484 | U+30C4 | 65410 | U+FF82 | 12387 | U+3063 | 12483 | U+30C3 |
| UTF-8 | 227 129 164 | E3 81 A4 | 227 131 132 | E3 83 84 | 239 190 130 | EF BE 82 | 227 129 163 | E3 81 A3 | 227 131 131 | E3 83 83 |
| Numeric character reference | つ | つ | ツ | ツ | ツ | ツ | っ | っ | ッ | ッ |
| Shift JIS[3] | 130 194 | 82 C2 | 131 99 | 83 63 | 194 | C2 | 130 193 | 82 C1 | 131 98 | 83 62 |
| EUC-JP[4] | 164 196 | A4 C4 | 165 196 | A5 C4 | 142 194 | 8E C2 | 164 195 | A4 C3 | 165 195 | A5 C3 |
| GB 18030[5] | 164 196 | A4 C4 | 165 196 | A5 C4 | 132 49 153 48 | 84 31 99 30 | 164 195 | A4 C3 | 165 195 | A5 C3 |
| EUC-KR[6] / UHC[7] | 170 196 | AA C4 | 171 196 | AB C4 | 170 195 | AA C3 | 171 195 | AB C3 | ||
| Big5 (non-ETEN kana)[8] | 198 200 | C6 C8 | 199 92 | C7 5C | 198 199 | C6 C7 | 199 91 | C7 5B | ||
| Big5 (ETEN / HKSCS)[9] | 199 75 | C7 4B | 199 192 | C7 C0 | 199 74 | C7 4A | 199 191 | C7 BF | ||
| Preview | ッ | づ | ヅ | ツ゚ | ㋡ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | HALFWIDTH KATAKANA LETTER SMALL TU | HIRAGANA LETTER DU | KATAKANA LETTER DU | KATAKANA LETTER AINU TU[10] | CIRCLED KATAKANA TU | |||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 65391 | U+FF6F | 12389 | U+3065 | 12485 | U+30C5 | 12484 12442 | U+30C4+309A | 13025 | U+32E1 |
| UTF-8 | 239 189 175 | EF BD AF | 227 129 165 | E3 81 A5 | 227 131 133 | E3 83 85 | 227 131 132 227 130 154 | E3 83 84 E3 82 9A | 227 139 161 | E3 8B A1 |
| Numeric character reference | ッ | ッ | づ | づ | ヅ | ヅ | ツ | ツ | ㋡ | ㋡ |
| Shift JIS (plain)[3] | 175 | AF | 130 195 | 82 C3 | 131 100 | 83 64 | ||||
| Shift JIS-2004[11] | 175 | AF | 130 195 | 82 C3 | 131 100 | 83 64 | 131 157 | 83 9D | ||
| EUC-JP (plain)[4] | 142 175 | 8E AF | 164 197 | A4 C5 | 165 197 | A5 C5 | ||||
| EUC-JIS-2004[12] | 142 175 | 8E AF | 164 197 | A4 C5 | 165 197 | A5 C5 | 165 253 | A5 FD | ||
| GB 18030[5] | 132 49 151 49 | 84 31 97 31 | 164 197 | A4 C5 | 165 197 | A5 C5 | ||||
| EUC-KR[6] / UHC[7] | 170 197 | AA C5 | 171 197 | AB C5 | ||||||
| Big5 (non-ETEN kana)[8] | 198 201 | C6 C9 | 199 93 | C7 5D | ||||||
| Big5 (ETEN / HKSCS)[9] | 199 76 | C7 4C | 199 193 | C7 C1 | ||||||
See also
| Look up つ, づ, ツ, or ヅ in Wiktionary, the free dictionary. |
| Wikimedia Commons has media related to つ. |
| Wikimedia Commons has media related to ツ. |
References
- "🤷 Shrug ¯\_(ツ)_/¯ Emoji". emojipedia.org.
- "The Best Way to Type ¯\_(ツ)_/¯". The Atlantic. 2014-05-21. Retrieved 2019-06-17.
- Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- Unicode Consortium. "Unicode Named Character Sequences". Unicode Character Database.
- Project X0213 (2009-05-03). "Shift_JIS-2004 (JIS X 0213:2004 Appendix 1) vs Unicode mapping table".
- Project X0213 (2009-05-03). "EUC-JIS-2004 (JIS X 0213:2004 Appendix 3) vs Unicode mapping table".