Kana
Kana (仮名, Japanese pronunciation: [kana]) are the syllabaries that form parts of the Japanese writing system, contrasted with the logographic Chinese characters known in Japan as kanji (漢字). The modern Japanese writing system makes use of two syllabaries: cursive hiragana (ひらがな)[2] and angular katakana (カタカナ). Also classified as kana is the ancient syllabic use of kanji known as man'yōgana (万葉仮名), which was ancestral to both hiragana and katakana. Hentaigana (変体仮名, "variant kana") are historical variants of modern standard hiragana. In modern Japanese, hiragana and katakana have directly corresponding sets of characters representing the same series of sounds.
| Kana | |
|---|---|
| Type | |
| Languages | Japanese, Ryukyuan languages, Ainu, Palauan[1] |
Time period | c. 800 CE to the present |
Parent systems | |
| Direction | Varies |
| ISO 15924 | Hrkt, 412 |
Unicode alias | Katakana or Hiragana |
Unicode range | U+30A0 – U+30FF |
 |
| Japanese writing |
|---|
| Components |
| Uses |
| Romanization |
|
Rōmaji
|
Katakana, with a few additions, are also used to write Ainu. Taiwanese kana were used in Taiwanese Hokkien as glosses (furigana) for Chinese characters in Taiwan under Japanese rule.
Each kana character (syllabogram) corresponds to one sound in the Japanese language, unlike kanji regular script corresponding to meaning (logogram). That is why the character system is named kana, literally "false name". Apart from the five vowels, this is always CV (consonant onset with vowel nucleus), such as ka, ki, etc., or V (vowel), such as a, i, etc., with the sole exception of the C grapheme for nasal codas usually romanised as n. This structure has led some scholars to label the system moraic instead of syllabic, because it requires the combination of two syllabograms to represent a CVC syllable with coda (i.e. CVn, CVm, CVng), a CVV syllable with complex nucleus (i.e. multiple or expressively long vowels), or a CCV syllable with complex onset (i.e. including a glide, CyV, CwV).
Due to the limited number of phonemes in Japanese, as well as the relatively rigid syllable structure, the kana system is a very accurate representation of spoken Japanese.
Hiragana and katakana
The following table reads, in gojūon order, as a, i, u, e, o (down first column), then ka, ki, ku, ke, ko (down second column), and so on. n appears on its own at the end. Asterisks mark unused combinations.
|
|
- There are presently no kana for ye, yi or wu, as corresponding syllables do not occur natively in modern Japanese.
- The [jɛ] (ye) sound is believed to have existed in pre-Classical Japanese, mostly before the advent of kana, and can be represented by the man'yōgana kanji 江.[3][4] There was an archaic Hiragana (

- The modern Katakana e, エ, derives from the man'yōgana 江, originally pronounced ye;[5] a "Katakana letter Archaic E" (

- Some gojūon tables published during the 19th century list additional Katakana in the ye (



- The [jɛ] (ye) sound is believed to have existed in pre-Classical Japanese, mostly before the advent of kana, and can be represented by the man'yōgana kanji 江.[3][4] There was an archaic Hiragana (
- While no longer part of standard Japanese orthography, wi and we are sometimes used stylistically, as in ウヰスキー for whisky and ヱビス or ゑびす for Japanese kami Ebisu, and Yebisu, a brand of beer named after Ebisu. Hiragana wi and we are still used in certain Okinawan scripts, while katakana wi and we are still used in Ainu.
- wo is preserved only in a single use, as a grammatical particle, normally written in hiragana.
- si, ti, tu, hu, wi, we and wo are often romanized respectively as shi, chi, tsu, fu, i, e and o instead, according to contemporary pronunciation.
Diacritics
Syllables beginning with the voiced consonants [g], [z], [d] and [b] are spelled with kana from the corresponding unvoiced columns (k, s, t and h) and the voicing mark, dakuten. Syllables beginning with [p] are spelled with kana from the h column and the half-voicing mark, handakuten.
| g | z | d | b | p | ng | |
|---|---|---|---|---|---|---|
| a | が ガ | ざ ザ | だ ダ | ば バ | ぱ パ | か゚ カ゚ |
| i | ぎ ギ | じ ジ | ぢ ヂ | び ビ | ぴ ピ | き゚ キ゚ |
| u | ぐ グ | ず ズ | づ ヅ | ぶ ブ | ぷ プ | く゚ ク゚ |
| e | げ ゲ | ぜ ゼ | で デ | べ ベ | ぺ ペ | け゚ ケ゚ |
| o | ご ゴ | ぞ ゾ | ど ド | ぼ ボ | ぽ ポ | こ゚ コ゚ |
- Note that the か゚, カ゚ and remaining entries in the rightmost column, though they exist, are not used in standard Japanese orthography.
- zi, di, and du are often transcribed into English as ji, ji, and zu instead, respectively, according to contemporary pronunciation.
- Usually, [va], [vi], [vu], [ve], [vo] are represented respectively by バ[ba], ビ[bi], ブ[bu], ベ[be], and ボ[bo], for example, in loanwords such as バイオリン (baiorin "violin"), but (less usually) the distinction can be preserved by using ヴァ(ヷ), ヴィ(ヸ), ヴ, ヴェ(ヹ), and ヴォ(ヺ). Note that ヴ did not have a JIS-encoded Hiragana form (ゔ) until JIS X 0213, meaning that many Shift JIS flavours (including the Windows and HTML5 version) can only represent it as a katakana, although Unicode supports both.
Digraphs
Syllables beginning with palatalized consonants are spelled with one of the seven consonantal kana from the i row followed by small ya, yu or yo. These digraphs are called yōon.
| k | s | t | n | h | m | r | |
|---|---|---|---|---|---|---|---|
| ya | きゃ | しゃ | ちゃ | にゃ | ひゃ | みゃ | りゃ |
| yu | きゅ | しゅ | ちゅ | にゅ | ひゅ | みゅ | りゅ |
| yo | きょ | しょ | ちょ | にょ | ひょ | みょ | りょ |
- There are no digraphs for the semivowel y and w columns.
- The digraphs are usually transcribed with three letters, leaving out the i: CyV. For example, きゃ is transcribed as kya.
- si+y* and ti+y* are often transcribed sh* and ch* instead of sy* and ty*. For example, しゃ is transcribed as sha.
- In earlier Japanese, digraphs could also be formed with w-kana. Although obsolete in modern Japanese, the digraphs くゎ (/kʷa/) and くゐ/くうぃ(/kʷi/), are still used in certain Okinawan orthographies. In addition, the kana え can be used in Okinawan to form the digraph くぇ, which represents the /kʷe/ sound.
| g | j | b | p | ng | |
|---|---|---|---|---|---|
| ya | ぎゃ | じゃ | びゃ | ぴゃ | き゚ゃ |
| yu | ぎゅ | じゅ | びゅ | ぴゅ | き゚ゅ |
| yo | ぎょ | じょ | びょ | ぴょ | き゚ょ |
- Note that the き゚ゃ, き゚ゅ and remaining entries in the rightmost column, though they exist, are not used in standard Japanese orthography.
- jya, jyu, and jyo are often transcribed into English as ja, ju, and jo instead, respectively, according to contemporary pronunciation.
Modern usage
The difference in usage between hiragana and katakana is stylistic. Usually, hiragana is the default syllabary, and katakana is used in certain special cases.
Hiragana is used to write native Japanese words with no kanji representation (or whose kanji is thought obscure or difficult), as well as grammatical elements such as particles and inflections (okurigana).
Today katakana is most commonly used to write words of foreign origin that do not have kanji representations, as well as foreign personal and place names. Katakana is also used to represent onomatopoeia and interjections, emphasis, technical and scientific terms, transcriptions of the Sino-Japanese readings of kanji, and some corporate branding.
Kana can be written in small form above or next to lesser-known kanji in order to show pronunciation; this is called furigana. Furigana is used most widely in children's or learners' books. Literature for young children who do not yet know kanji may dispense with it altogether and instead use hiragana combined with spaces.
History
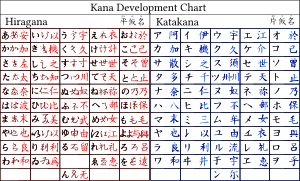
The first kana was a system called man'yōgana, a set of kanji used solely for their phonetic values, much as Chinese uses characters for their phonetic values in foreign loanwords (especially proper nouns) today. Man'yōshū, a poetry anthology assembled in 759, is written in this early script. Hiragana developed as a distinct script from cursive man'yōgana, whereas katakana developed from abbreviated parts of regular script man'yōgana as a glossing system to add readings or explanations to Buddhist sutras.
Kana is traditionally said to have been invented by the Buddhist priest Kūkai in the ninth century. Kūkai certainly brought the Siddhaṃ script of India home on his return from China in 806; his interest in the sacred aspects of speech and writing led him to the conclusion that Japanese would be better represented by a phonetic alphabet than by the kanji which had been used up to that point. The modern arrangement of kana reflects that of Siddhaṃ, but the traditional iroha arrangement follows a poem which uses each kana once.
The present set of kana was codified in 1900, and rules for their usage in 1946.[12]
| a | i | u | e | o | =:≠ | |
|---|---|---|---|---|---|---|
| - | ≠ | ≠ | = | ≠ | = | 2:3 |
| k | = | = | = | ≠ | = | 4:1 |
| s | ≠ | = | ≠ | = | = | 3:2 |
| t | ≠ | ≠ | = | = | = | 3:2 |
| n | = | = | = | = | = | 5:0 |
| h | ≠ | = | = | = | = | 4:1 |
| m | = | ≠ | ≠ | = | = | 3:2 |
| y | = | = | = | 3:0 | ||
| r | = | = | ≠ | = | = | 4:1 |
| w | = | ≠ | = | ≠ | 2:2 | |
| n | ≠ | 0:1 | ||||
| =:≠ | 6:4 | 5:4 | 6:4 | 7:2 | 9:1 | 33:15 |
Collation
Kana are the basis for collation in Japanese. They are taken in the order given by the gojūon (あ い う え お ... わ を ん), though iroha (い ろ は に ほ へ と ... せ す (ん)) ordering is used for enumeration in some circumstances. Dictionaries differ in the sequence order for long/short vowel distinction, small tsu and diacritics. As Japanese does not use word spaces (except as a tool for children), there can be no word-by-word collation; all collation is kana-by-kana.
In Unicode
The hiragana range in Unicode is U+3040 ... U+309F, and the katakana range is U+30A0 ... U+30FF. The obsolete and rare characters (wi and we) also have their proper code points.
| Hiragana[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+304x | ぁ | あ | ぃ | い | ぅ | う | ぇ | え | ぉ | お | か | が | き | ぎ | く | |
| U+305x | ぐ | け | げ | こ | ご | さ | ざ | し | じ | す | ず | せ | ぜ | そ | ぞ | た |
| U+306x | だ | ち | ぢ | っ | つ | づ | て | で | と | ど | な | に | ぬ | ね | の | は |
| U+307x | ば | ぱ | ひ | び | ぴ | ふ | ぶ | ぷ | へ | べ | ぺ | ほ | ぼ | ぽ | ま | み |
| U+308x | む | め | も | ゃ | や | ゅ | ゆ | ょ | よ | ら | り | る | れ | ろ | ゎ | わ |
| U+309x | ゐ | ゑ | を | ん | ゔ | ゕ | ゖ | ゙ | ゚ | ゛ | ゜ | ゝ | ゞ | ゟ | ||
| Notes | ||||||||||||||||
| Katakana[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+30Ax | ゠ | ァ | ア | ィ | イ | ゥ | ウ | ェ | エ | ォ | オ | カ | ガ | キ | ギ | ク |
| U+30Bx | グ | ケ | ゲ | コ | ゴ | サ | ザ | シ | ジ | ス | ズ | セ | ゼ | ソ | ゾ | タ |
| U+30Cx | ダ | チ | ヂ | ッ | ツ | ヅ | テ | デ | ト | ド | ナ | ニ | ヌ | ネ | ノ | ハ |
| U+30Dx | バ | パ | ヒ | ビ | ピ | フ | ブ | プ | ヘ | ベ | ペ | ホ | ボ | ポ | マ | ミ |
| U+30Ex | ム | メ | モ | ャ | ヤ | ュ | ユ | ョ | ヨ | ラ | リ | ル | レ | ロ | ヮ | ワ |
| U+30Fx | ヰ | ヱ | ヲ | ン | ヴ | ヵ | ヶ | ヷ | ヸ | ヹ | ヺ | ・ | ー | ヽ | ヾ | ヿ |
Notes
| ||||||||||||||||
Characters U+3095 and U+3096 are hiragana small ka and small ke, respectively. U+30F5 and U+30F6 are their katakana equivalents. Characters U+3099 and U+309A are combining dakuten and handakuten, which correspond to the spacing characters U+309B and U+309C. U+309D is the hiragana iteration mark, used to repeat a previous hiragana. U+309E is the voiced hiragana iteration mark, which stands in for the previous hiragana but with the consonant voiced (k becomes g, h becomes b, etc.). U+30FD and U+30FE are the katakana iteration marks. U+309F is a ligature of yori (より) sometimes used in vertical writing. U+30FF is a ligature of koto (コト), also found in vertical writing.
Additionally, there are halfwidth equivalents to the standard fullwidth katakana. These are encoded within the Halfwidth and Fullwidth Forms block (U+FF00–U+FFEF), starting at U+FF65 and ending at U+FF9F (characters U+FF61–U+FF64 are halfwidth punctuation marks):
| Katakana subset of Halfwidth and Fullwidth Forms[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| ... | (U+FF00–U+FF64 omitted) | |||||||||||||||
| U+FF6x | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |||||
| U+FF7x | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| U+FF8x | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| U+FF9x | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
| ... | (U+FFA0–U+FFEF omitted) | |||||||||||||||
Notes
| ||||||||||||||||
There is also a small "Katakana Phonetic Extensions" range (U+31F0 ... U+31FF), which includes some additional small kana characters for writing the Ainu language. Further small kana characters are present in the "Small Kana Extension" block.
| Katakana Phonetic Extensions[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+31Fx | ㇰ | ㇱ | ㇲ | ㇳ | ㇴ | ㇵ | ㇶ | ㇷ | ㇸ | ㇹ | ㇺ | ㇻ | ㇼ | ㇽ | ㇾ | ㇿ |
Notes
| ||||||||||||||||
| Small Kana Extension[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1B13x | ||||||||||||||||
| U+1B14x | ||||||||||||||||
| U+1B15x | 𛅐 | 𛅑 | 𛅒 | |||||||||||||
| U+1B16x | 𛅤 | 𛅥 | 𛅦 | 𛅧 | ||||||||||||
| Notes | ||||||||||||||||
Unicode also includes "Katakana letter archaic E" (U+1B000), as well as 255 archaic Hiragana, in the Kana Supplement block.[13] It also includes a further 31 archaic Hiragana in the Kana Extended-A block.[14]
| Kana Supplement[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1B00x | 𛀀 | 𛀁 | 𛀂 | 𛀃 | 𛀄 | 𛀅 | 𛀆 | 𛀇 | 𛀈 | 𛀉 | 𛀊 | 𛀋 | 𛀌 | 𛀍 | 𛀎 | 𛀏 |
| U+1B01x | 𛀐 | 𛀑 | 𛀒 | 𛀓 | 𛀔 | 𛀕 | 𛀖 | 𛀗 | 𛀘 | 𛀙 | 𛀚 | 𛀛 | 𛀜 | 𛀝 | 𛀞 | 𛀟 |
| U+1B02x | 𛀠 | 𛀡 | 𛀢 | 𛀣 | 𛀤 | 𛀥 | 𛀦 | 𛀧 | 𛀨 | 𛀩 | 𛀪 | 𛀫 | 𛀬 | 𛀭 | 𛀮 | 𛀯 |
| U+1B03x | 𛀰 | 𛀱 | 𛀲 | 𛀳 | 𛀴 | 𛀵 | 𛀶 | 𛀷 | 𛀸 | 𛀹 | 𛀺 | 𛀻 | 𛀼 | 𛀽 | 𛀾 | 𛀿 |
| U+1B04x | 𛁀 | 𛁁 | 𛁂 | 𛁃 | 𛁄 | 𛁅 | 𛁆 | 𛁇 | 𛁈 | 𛁉 | 𛁊 | 𛁋 | 𛁌 | 𛁍 | 𛁎 | 𛁏 |
| U+1B05x | 𛁐 | 𛁑 | 𛁒 | 𛁓 | 𛁔 | 𛁕 | 𛁖 | 𛁗 | 𛁘 | 𛁙 | 𛁚 | 𛁛 | 𛁜 | 𛁝 | 𛁞 | 𛁟 |
| U+1B06x | 𛁠 | 𛁡 | 𛁢 | 𛁣 | 𛁤 | 𛁥 | 𛁦 | 𛁧 | 𛁨 | 𛁩 | 𛁪 | 𛁫 | 𛁬 | 𛁭 | 𛁮 | 𛁯 |
| U+1B07x | 𛁰 | 𛁱 | 𛁲 | 𛁳 | 𛁴 | 𛁵 | 𛁶 | 𛁷 | 𛁸 | 𛁹 | 𛁺 | 𛁻 | 𛁼 | 𛁽 | 𛁾 | 𛁿 |
| U+1B08x | 𛂀 | 𛂁 | 𛂂 | 𛂃 | 𛂄 | 𛂅 | 𛂆 | 𛂇 | 𛂈 | 𛂉 | 𛂊 | 𛂋 | 𛂌 | 𛂍 | 𛂎 | 𛂏 |
| U+1B09x | 𛂐 | 𛂑 | 𛂒 | 𛂓 | 𛂔 | 𛂕 | 𛂖 | 𛂗 | 𛂘 | 𛂙 | 𛂚 | 𛂛 | 𛂜 | 𛂝 | 𛂞 | 𛂟 |
| U+1B0Ax | 𛂠 | 𛂡 | 𛂢 | 𛂣 | 𛂤 | 𛂥 | 𛂦 | 𛂧 | 𛂨 | 𛂩 | 𛂪 | 𛂫 | 𛂬 | 𛂭 | 𛂮 | 𛂯 |
| U+1B0Bx | 𛂰 | 𛂱 | 𛂲 | 𛂳 | 𛂴 | 𛂵 | 𛂶 | 𛂷 | 𛂸 | 𛂹 | 𛂺 | 𛂻 | 𛂼 | 𛂽 | 𛂾 | 𛂿 |
| U+1B0Cx | 𛃀 | 𛃁 | 𛃂 | 𛃃 | 𛃄 | 𛃅 | 𛃆 | 𛃇 | 𛃈 | 𛃉 | 𛃊 | 𛃋 | 𛃌 | 𛃍 | 𛃎 | 𛃏 |
| U+1B0Dx | 𛃐 | 𛃑 | 𛃒 | 𛃓 | 𛃔 | 𛃕 | 𛃖 | 𛃗 | 𛃘 | 𛃙 | 𛃚 | 𛃛 | 𛃜 | 𛃝 | 𛃞 | 𛃟 |
| U+1B0Ex | 𛃠 | 𛃡 | 𛃢 | 𛃣 | 𛃤 | 𛃥 | 𛃦 | 𛃧 | 𛃨 | 𛃩 | 𛃪 | 𛃫 | 𛃬 | 𛃭 | 𛃮 | 𛃯 |
| U+1B0Fx | 𛃰 | 𛃱 | 𛃲 | 𛃳 | 𛃴 | 𛃵 | 𛃶 | 𛃷 | 𛃸 | 𛃹 | 𛃺 | 𛃻 | 𛃼 | 𛃽 | 𛃾 | 𛃿 |
Notes
| ||||||||||||||||
| Kana Extended-A[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1B10x | 𛄀 | 𛄁 | 𛄂 | 𛄃 | 𛄄 | 𛄅 | 𛄆 | 𛄇 | 𛄈 | 𛄉 | 𛄊 | 𛄋 | 𛄌 | 𛄍 | 𛄎 | 𛄏 |
| U+1B11x | 𛄐 | 𛄑 | 𛄒 | 𛄓 | 𛄔 | 𛄕 | 𛄖 | 𛄗 | 𛄘 | 𛄙 | 𛄚 | 𛄛 | 𛄜 | 𛄝 | 𛄞 | |
| U+1B12x | ||||||||||||||||
| Notes | ||||||||||||||||
See also
References
- Thomas E. McAuley, Language change in East Asia, 2001:90
- Hatasa, Yukiko Abe; Kazumi Hatasa; Seiichi Makino (2010). Nakama 1: Introductory Japanese: Communication, Culture, Context 2nd ed. Heinle. p. 2. ISBN 0495798185.
- Seeley, Christopher (1991). A History of Writing in Japan. pp. 109 (footnote 18). ISBN 90 04 09081 9.
- "Is there a kana symbol for ye or yi?". SLJ FAQ. Retrieved 4 August 2016.
- Katō, Nozomu (2008-01-14). "JTC1/SC2/WG2 N3388: Proposal to encode two Kana characters concerning YE" (PDF). Retrieved 4 August 2016.
- "Kana Supplement" (PDF). Unicode 6.0. Unicode. 2010. Retrieved 22 June 2016.
- More information is available at ja:ヤ行エ on the Japanese Wikipedia.
- "Japanese Kana Chart from the Netherlands". www.raccoonbend.com.
- Katō, Nozomu. "L2/08-359: About WG2 N3528" (PDF).
- "伊豆での収穫" (in Japanese). Archived from the original on 2008-03-03.
- More information is available at ja:わ行う, ja:ヤ行イ and ja:五十音#51全てが異なる字・音: 江戸後期から明治 on the Japanese Wikipedia.
- "Writing reforms in modern Japan".
- https://www.unicode.org/charts/PDF/U1B000.pdf
- https://www.unicode.org/charts/PDF/U1B100.pdf
External links
- Hiragana & katakana chart and writing practice sheet
- Origin of Hiragana
- Origin of Katakana
- Kana web translator - Transliterate Kana to Rōmaji
- Kana Copybook (PDF)
| Authority control |
|
|---|