Diaeresis (diacritic)
The diaeresis[lower-alpha 1] (/daɪˈɛriːsɪs/ dy-ERR-ee-sis; also known as the tréma[lower-alpha 2]) and the umlaut are two different homoglyphic diacritical marks. They both consist of two dots ( ¨ ) placed over a letter, usually a vowel. When that letter is an i or a j, the diacritic replaces the tittle: ï.[1]
¨ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Diaeresis | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Latin | |
|---|---|
| Ä | ä |
| Ǟ | ǟ |
| Ą̈ | ą̈ |
| B̈ | b̈ |
| C̈ | c̈ |
| Ë | ë |
| Ḧ | ḧ |
| Ï | ï |
| Ḯ | ḯ |
| J̈ | j̈ |
| K̈ | k̈ |
| L̈ | l̈ |
| M̈ | m̈ |
| N̈ | n̈ |
| Ö | ö |
| Ȫ | ȫ |
| Ǫ̈ | ǫ̈ |
| Ṏ | ṏ |
| P̈ | p̈ |
| Q̈ | q̈ |
| Q̣̈ | q̣̈ |
| R̈ | r̈ |
| S̈ | s̈ |
| T̈ | ẗ |
| Ü | ü |
| Ǖ | ǖ |
| Ǘ | ǘ |
| Ǚ | ǚ |
| Ǜ | ǜ |
| Ṳ | ṳ |
| Ṻ | ṻ |
| Ṳ̄ | ṳ̄ |
| ᴞ | |
| V̈ | v̈ |
| Ẅ | ẅ |
| Ẍ | ẍ |
| Ÿ | ÿ |
| Z̈ | z̈ |
| Greek | |
| Ϊ | ϊ |
ῒ ΐ ῗ | |
| Ϋ | ϋ |
ῢ ΰ ῧ | |
| ϔ | |
| Cyrillic | |
| Ӓ | ӓ |
| Ё | ё |
| Ӛ | ӛ |
| Ӝ | ӝ |
| Ӟ | ӟ |
| Ӥ | ӥ |
| Ї | ї |
| Ӧ | ӧ |
| Ӫ | ӫ |
| Ӱ | ӱ |
| Ӵ | ӵ |
| Ӹ | ӹ |
| Ӭ | ӭ |
The diaeresis and the umlaut are diacritics marking two distinct phonological phenomena. The diaeresis represents the phenomenon also known as diaeresis or hiatus in which a vowel letter is pronounced separately from an adjacent vowel and not as part of a digraph or diphthong. The umlaut (/ˈʊmlaʊt/), in contrast, indicates a sound shift.
These two diacritics originated separately; the diaeresis is considerably older.
Nevertheless, in modern computer systems using Unicode, the umlaut and diaeresis diacritics are identically encoded, e.g. U+00E4 ä LATIN SMALL LETTER A WITH DIAERESIS (HTML ä · ä) represents both a-umlaut and a-diaeresis (much like the hyphen-minus code point represents both a hyphen and often a minus sign).
The same symbol is also used as a diacritic in other cases, distinct from both diaeresis and umlaut. For example, in Albanian and Tagalog ë represents a schwa.
Names
The word diaeresis is from Greek diaíresis (διαίρεσις), meaning "division", "separation", or "distinction".[2]
The word trema (plural: tremas or tremata), used in French linguistics and also classical scholarship, is from the Greek trē̂ma (τρῆμα) and means a "perforation", "orifice", or "pip" (as on dice),[3] thus describing the form of the diacritic rather than its function.
Umlaut is the German name of both the Germanic umlaut, a sound-law also known as i-mutation, and the corresponding diacritic.
Diaeresis
The diaeresis indicates that two adjoining letters that would normally form a digraph and be pronounced as one are instead to be read as separate vowels in two syllables. The diaeresis indicates that a vowel should be pronounced apart from the letter that precedes it. For example, in the spelling coöperate, the diaeresis reminds the reader that the word has four syllables co-op-er-ate, not three, *coop-er-ate. In British English this usage has been considered obsolete for many years, and in US English, although it persisted for longer, it is now considered archaic as well.[4] Nevertheless, it is still used by the US magazine The New Yorker.[5] In English language texts it is perhaps most familiar in the spellings naïve, Noël, and Chloë, and is also used officially in the name of the island Teän. Languages such as Dutch, Catalan, French, Galician and Spanish make regular use of the diaeresis.
History
Greek alphabet
Two dots, called a trema, were used in the Hellenistic period on the letters ι and υ, most often at the beginning of a word, as in ϊδων, ϋιος, and ϋβριν, to separate them from a preceding vowel, as writing was scriptio continua, where spacing was not yet used as a word divider (see Coptic alphabet, for example). However, it was also used to indicate that a vowel formed its own syllable (in phonological hiatus), as in ηϋ and Αϊδι.[6][7]
In Modern Greek, αϊ and οϊ represent the diphthongs /ai̯/ and /oi̯/, and εϊ the disyllabic sequence /e.i/, whereas αι, οι, and ει transcribe the simple vowels /e/, /i/, and /i/. The diacritic can be the only one on a vowel, as in ακαδημαϊκός (akadimaïkós, 'academic'), or in combination with an acute accent, as in πρωτεΐνη (proteïni, 'protein').
Ÿ is sometimes used in transcribed Greek, where it represents the Greek letter υ (upsilon) in hiatus with α. For example, it can be seen in the transcription Artaÿctes of the Persian name Ἀρταΰκτης (Artaüktēs) at the very end of Herodotus, or the name of Mount Taÿgetus on the southern Peloponnesus peninsula, which in modern Greek is spelled Ταΰγετος.
Latin alphabet
The diaeresis was borrowed for this purpose in several languages of western and southern Europe, among them Occitan, Catalan, French, Dutch, Welsh, and (rarely) English.
When a vowel in Greek was stressed, it did not assimilate to a preceding vowel but remained as a separate syllable. Such vowels were marked with an accent such as the acute, a tradition that has also been adopted by other languages, such as Spanish and Portuguese. For example, the Portuguese words saia [ˈsajɐ] "skirt" and the imperfect saía [saˈi.ɐ] "[I/he/she] used to leave" differ in that the sequence /ai/ forms a diphthong in the former (synaeresis), but is a hiatus in the latter (diaeresis).
Hiatus
In Catalan, the digraphs ai, ei, oi, au, eu, and iu are normally read as diphthongs. To indicate exceptions to this rule (hiatus), a diaeresis mark is placed on the second vowel: without this the words raïm [rəˈim] ("grape") and diürn [diˈurn] ("diurnal") would be read *[ˈrajm] and *[ˈdiwrn], respectively. The Occitan use of diaeresis is very similar to that of Catalan: ai, ei, oi, au, eu, ou are diphthongs consisting of one syllable but aï, eï, oï, aü, eü, oü are groups consisting of two distinct syllables.
In Welsh, where the diaeresis appears, it is usually on the stressed vowel, and this is most often on the first of the two adjacent vowels; a typical example is copïo [kɔ.ˈpi.ɔ] (to copy), cf. mopio [ˈmɔ.pjɔ] (to mop). It is also used on the first of two vowels that would otherwise form a diphthong (crëir [ˈkreː.ɪr] rather than creir [ˈkrəi̯r]) and on the first of three vowels to separate it from a following diphthong: crëwyd is pronounced [ˈkreː.ʊi̯d] rather than [ˈkrɛu̯.ɨd].
In Dutch, spellings such as coëfficiënt are necessary because the digraphs oe and ie normally represent the simple vowels [u] and [i], respectively. However, hyphenation is now preferred for compound words so that zeeëend (sea duck) is now spelled zee-eend.[8]
In German, diaeresis occurs in a few proper names, such as Ferdinand Piëch and Bernhard Hoëcker.
In Galician, diaeresis is employed to indicate hiatus in the first and second persons of the plural of the imperfect tense of verbs ended in -aer, -oer, -aír and -oír (saïamos, caïades). This stems from the fact that an unstressed -i- is left between vowels, but constituting its own syllable, which would end with a form identical in writing but different in pronunciation with those of the Present subjunctive (saiamos, caiades), as those have said i forming a diphthong with the following a.
Non-silent vowels
As a further extension, some languages began to use a diaeresis whenever a vowel letter was to be pronounced separately. This included vowels that would otherwise form digraphs with consonants or simply be silent.
In the orthographies of Spanish, Catalan, French, Galician, and Occitan, the graphemes gu and qu normally represent a single sound, [ɡ] or [k], before the front vowels e and i (or before nearly all vowels in Occitan). In the few exceptions where the u is pronounced, a diaeresis is added to it. Before the 1990 Orthographic Agreement, a diaeresis ("trema") was also used in (mainly Brazilian) Portuguese in this manner, in words like sangüíneo [sɐ̃ˈɡwiniu] “sanguineous”; after the implementation of the Orthographic Agreement, it was abolished altogether from all Portuguese words. In French, in the aforementioned cases the diaeresis is usually written over the following vowel.
Examples:
- Spanish pingüino [piŋˈɡwino] "penguin"
- Catalan aigües [ˈajɣwəs] "waters", qüestió [kwəstiˈo] "matter, question"
- Occitan lingüista [liŋˈɡwistɔ] "linguist", aqüatic [aˈkwatik] "aquatic"
- French aiguë or aigüe [eɡy] "acute (fem.)" (note that the e is silent; without the diacritic, both it and the u would be silent)
- Galician mingüei [miŋˈɡwej] "I shrank", saïamos "we went out/used to go out"
- Luxembourgish Chance [ˈʃɑ̃ːs] "opportunity", Chancë [ˈʃɑ̃ːsə] (before a consonant) "opportunities"
- English Brontë /ˈbrɒnti/ (see Brontë family)
This has been extended to Ganda, where a diaeresis separates y from n: anya [aɲa], anÿa [aɲja].
French
In French, some diphthongs that were written with pairs of vowel letters were later reduced to monophthongs, which led to an extension of the value of this diacritic. It often now indicates that the second vowel letter is to be pronounced separately from the first, rather than merge with it into a single sound. For example, the French words maïs [ma.is] and naïve [na.iv] would be pronounced *[mɛ] and *[nɛv], respectively, without the diaeresis mark, since the digraph ai is pronounced [ɛ]. The English spelling of Noël "Christmas" (French [nɔ.ɛl]) comes from this use. Ÿ occurs in French as a variant of ï in a few proper nouns, as in the name of the Parisian suburb of L'Haÿ-les-Roses [la.i le ʁoz].
The diaeresis is also used when a silent e is added to the sequence gu, to show that it is to be pronounced [ɡy] rather than as a digraph for [ɡ]. For example, when the feminine -e is added to aigu [eɡy] "sharp", the pronunciation does not change: aiguë [eɡy]. Similar is the feminine noun cigüe [siɡy] "hemlock"; compare figue [fiɡ] "fig". In the ongoing French spelling reform of 1990, this was moved to the u (aigüe, cigüe), though the earlier orthography continues to be widely used. (In canoë [kanɔ.e] the e is not silent, and so is not affected by the spelling reform.)
In some names, a diaeresis is used to show what used to be two vowels in hiatus, although the second vowel has since fallen silent, as in Saint-Saëns [sɛ̃sɑ̃s] and de Staël [də stal].
English
The grave accent and the diaeresis are the only diacritics native to Modern English (apart from diacritics used in loanwords, such as the acute accent, the cedilla, or the tilde). The use of both, however, is considered to be largely archaic.[9][10]
The diaeresis mark is sometimes used in English personal first and last names to indicate that two adjacent vowels should be pronounced separately, rather than as a diphthong. Examples include the given names Chloë and Zoë, which otherwise might be pronounced with a silent e. To discourage a similar mispronunciation, the mark is also used in the surname Brontë. It may be used optionally for words that do not have a morphological break at the diaeresis point, such as naïve, Boötes, and Noël. However, it is now far less commonly used in words such as coöperate and reënter except in a very few publications—notably The New Yorker[11][12][5] and MIT Technology Review under Jason Pontin.
Umlaut

Germanic umlaut is a specific historical phenomenon of vowel-fronting in German and other Germanic languages.[lower-alpha 3] In German it causes back vowels /a/, /o/ and /u/ to shift forward in the mouth to /ɛ/, /ø/ and /y/, respectively. In modern German orthography, the affected graphemes ⟨a⟩, ⟨o⟩ and ⟨u⟩ are written as ⟨ä⟩, ⟨ö⟩ and ⟨ü⟩, i.e. they are written with the diacritical mark "umlaut", which looks identical to the diaeresis mark.
History
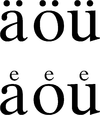
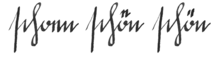
German phonological umlaut was present in the Old High German period and continued to develop in Middle High German. From the Middle High German period, it was sometimes denoted in written German by adding an e to the affected vowel, either after the vowel or, in small form, above it. This can still be seen in some names, e.g. Goethe, Goebbels, Staedtler.[lower-alpha 4] In medieval German manuscripts, other digraphs were also commonly written using superscripts. In bluome ('flower'), for example, the ⟨o⟩ was frequently placed above the ⟨u⟩ (blůme). This letter survives now only in Czech. Compare also ⟨ñ⟩ for the digraph nn, with the tilde as a superscript ⟨n⟩.
In blackletter handwriting as used in German manuscripts of the later Middle Ages, and also in many printed texts of the early modern period, the superscript ⟨e⟩ still had a form that would be recognisable to us as an ⟨e⟩, but in manuscript writing, umlauted vowels could be indicated by two dots since the late medieval period.
In the forms of handwriting that emerged in the early modern period (of which Sütterlin is the latest and best-known example) the letter ⟨e⟩ was composed of two short vertical lines very close together, and the superscript ⟨e⟩ looked like two tiny strokes. Even from the 16th century, the handwritten convention of indicating umlaut by two dots placed above the affected vowel is also found in printed texts.
Unusual umlaut designs are sometimes also created for graphic design purposes, such as to fit an umlaut into tightly-spaced lines of text.[13] This may include umlauts placed vertically or inside the body of the letter.[14][15][16]
Printing conventions in German
When typing German, if umlaut letters are not available, it is usual to replace them with the underlying vowel followed by an ⟨e⟩. So, for example, "Schröder" becomes "Schroeder". As the pronunciation differs greatly between the normal letter and the umlaut, simply omitting the dots is incorrect. The result might often be a different word, as in schon 'already', schön 'beautiful'; or a different grammatic form, e.g. Mutter 'mother', Mütter 'mothers'.
Despite this, the umlauted letters are not considered as separate letters of the alphabet proper in German, in contrast to other Germanic languages.
When alphabetically sorting German words, the umlaut is usually not distinguished from the underlying vowel, although if two words differ only by an umlaut, the umlauted one comes second, for example:
- Schon
- Schön
- Schonen
There is a second system in limited use, mostly for sorting names (colloquially called "telephone directory sorting"), which treats ü like ue, and so on.
- Schön
- Schon
- Schonen
Austrian telephone directories insert ö after oz.
- Schon
- Schonen
- Schön
In Switzerland, capital umlauts are sometimes printed as digraphs, in other words, ⟨Ae⟩, ⟨Oe⟩, ⟨Ue⟩, instead of ⟨Ä⟩, ⟨Ö⟩, ⟨Ü⟩ (see German alphabet for an elaboration.) This is because the Swiss typewriter keyboard contains the French accents on the same keys as the umlauts (selected by Shift). To write capital umlauts the ¨-key is pressed followed by the capital letter to which the umlaut should apply.
Borrowing of German umlaut notation
Some languages have borrowed some of the forms of the German letters Ä, Ö, or Ü, including Azerbaijani, Estonian, Finnish, Hungarian, Karelian, some of the Sami languages, Slovak, Swedish, and Turkish. This indicates sounds similar to the corresponding umlauted letters in German. In spoken Scandinavian languages the grammatical umlaut change is used (singular to plural, derivations etc.) but the character used differs between languages. In Finnish, a/ä and o/ö change systematically in suffixes according to the rules of vowel harmony. In Hungarian, where long vowels are indicated with an acute accent, the umlaut notation has been expanded with a version of the umlaut which looks like double acute accents, indicating a blend of umlaut and acute. Contrast: short ö; long ő. The Estonian alphabet has borrowed ⟨ä⟩, ⟨ö⟩, and ⟨ü⟩ from German; Swedish and Finnish have ⟨ä⟩ and ⟨ö⟩; and Slovak has ⟨ä⟩. In Estonian, Swedish, Finnish, and Sami ⟨ä⟩ and ⟨ö⟩ denote [æ] and [ø], respectively. Hungarian has ⟨ö⟩ and ⟨ü⟩. The Slovak language uses the letter ⟨ä⟩ to denote [ɛ] (or a bit archaic but still correct [æ]). The sign is called dve bodky ("two dots"), and the full name of the letter ä is a s dvomi bodkami ("a with two dots"). The similar word dvojbodka ("double dot") however refers to the colon. In these languages, with the exception of Hungarian, the replacement rule for situations where the umlaut character is not available, is to simply use the underlying unaccented character instead. Hungarian follows the German rules and replaces ⟨ö⟩ and ⟨ü⟩ with ⟨oe⟩ and ⟨ue⟩ respectively – at least for telegrams and telex messages. The same rule is followed for the near-lookalikes ⟨ő⟩ and ⟨ű⟩.
In Luxembourgish (Lëtzebuergesch), the umlaut diacritic in ⟨ä⟩ and ⟨ë⟩ represents a stressed schwa. The letters ⟨ü⟩ and ⟨ö⟩ do not occur in native Luxembourgish words, but at least the former is common in words borrowed from standard German.
When Turkish switched from the Arabic to the Latin alphabet in 1928, it adopted a number of diacritics borrowed from various languages, including ⟨ü⟩ and ⟨ö⟩ from German (probably reinforced by their use in languages like Swedish, Hungarian, etc.). These Turkish graphemes represent sounds similar to their respective values in German (see Turkish alphabet).
As the borrowed diacritic has lost its relationship to Germanic i-mutation, they are in some languages considered independent graphemes, and cannot be replaced with ⟨ae⟩, ⟨oe⟩, or ⟨ue⟩ as in German. In Estonian and Finnish, for example, these latter diphthongs have independent meanings. Even some Germanic languages, such as Swedish (which does have a transformation analogous to the German umlaut, called omljud), treat them always as independent letters. In collation, this means they have their own positions in the alphabet, for example at the end ("A–Ö" or "A–Ü", not "A–Z") as in Swedish, Estonian and Finnish, which means that the dictionary order is different from German. The transformations ä → ae and ö → oe can, therefore, be considered less appropriate for these languages, although Swedish and Finnish passports use the transformation to render ö and ä (and å as aa) in the machine-readable zone. In contexts of technological limitation, e.g. in English based systems, Swedes can either be forced to omit the diacritics or use the two letter system.
When typing in Norwegian, the letters Æ and Ø might be replaced with Ä and Ö respectively if the former are not available. If ä is not available either, it is appropriate to use ae. The same goes for ö and oe. While ae has a great resemblance to the letter æ and, therefore, does not impede legibility, the digraph oe is likely to reduce the legibility of a Norwegian text. This especially applies to the digraph øy, which would be rendered in the more cryptic form oey. Also in Danish, Ö has been used in place of Ø in some older texts and to distinguish between open and closed ö-sounds and when confusion with other symbols could occur, e.g. on maps. The Danish/Norwegian Ø is like the German Ö a development of OE, to be compared with the French Œ.
Early Volapük used Fraktur a, o and u as different from Antiqua ones. Later, the Fraktur forms were replaced with umlauted vowels.
The usage of umlaut-like diacritic vowels, particularly ü, occurs in the transcription of languages that do not use the Roman alphabet, such as Chinese. For example, 女 (female) is transcribed as nǚ in proper Mandarin Chinese pinyin, while nv is sometimes used as a replacement for convenience since the letter v is not used in pinyin. Tibetan pinyin uses ä, ö, ü with approximately their German values.
The Cyrillic letters ӓ, ӧ, ӱ are used in Mari, Khanty, and other languages for approximately [æ], [ø], and [y]. These directly parallel the German umlaut ä, ö, ü. Other vowels using a double dot to modify their values in various minority languages of Russia are ӛ, ӫ, and ӹ.
Use of the umlaut for special effect
The umlaut diacritic can be used in "sensational spellings" or foreign branding, for example in advertising, or for other special effects. Häagen-Dazs is an example of such usage.
Other uses
A double dot is also used as a diacritic in cases where it functions as neither a diaeresis nor an umlaut. In the International Phonetic Alphabet (IPA), a double dot is used for a centralized vowel, a situation more similar to umlaut than to diaeresis. In other languages it is used for vowel length, nasalization, tone, and various other uses where diaeresis or umlaut was available typographically. The IPA uses a double dot below letters to indicate a breathy-voice or murmur.
Vowels
- In Albanian and Kashubian, ⟨ë⟩ represents a schwa [ə].
- In Aymara, a double dot is used on ⟨ä⟩ ⟨ï⟩ ⟨ü⟩ for vowel length.
- In the Basque dialect of Soule, ⟨ü⟩ represents [y]
- In the DMG romanization of Tunisian Arabic, ⟨ä⟩, ⟨ö⟩, ⟨ṏ⟩, ⟨ü⟩, and ⟨ṻ⟩ represent [æ], [œ], [œ̃], [y], and [y:].
- In Ligurian official orthography, ⟨ö⟩ is used to represent the sound [oː].
- In Māori a diaeresis (e.g. Mäori) was often used on computers in the past instead of the macron to indicate long vowels, as the diaeresis was relatively easy to produce on many systems, and the macron difficult or impossible.[17][18]
- In Seneca, ⟨ë⟩ ⟨ö⟩ are nasal vowels, though ⟨ä⟩ is [ɛ], as in German umlaut.
- In Vurës (Vanuatu), ⟨ë⟩ and ⟨ö⟩ encode respectively [œ] and [ø].
- In the Pahawh Hmong script, a double dot is used as one of several tone marks.
- The double dot was used in the early Cyrillic alphabet, which was used to write Old Church Slavonic. The modern Cyrillic Belarusian and Russian alphabets include the letter yo ⟨ё⟩, although replacing it with the letter ⟨е⟩ without the diacritic is allowed in Russian unless doing so would create ambiguity. Since the 1870s, the letter yi (Ї, ї) has been used in the Ukrainian alphabet for iotated [ji]; plain і is not iotated [i]. In Udmurt, ӥ is used for uniotated [i], with и for iotated [ji].
- The form ÿ is common in Dutch handwriting and also occasionally used in printed text – but is a form of the digraph "ij" rather than a modification of the letter "y".
- Komi language uses ⟨Ӧ⟩ (a Cyrillic O with diaeresis) for [ə].
Consonants
Jacaltec (a Mayan language) and Malagasy are among the very few languages with a diaeresis on the letter "n"; in both, n̈ is the velar nasal [ŋ].
In Udmurt, a double dot is also used with the consonant letters ӝ [dʒ] (from ж [ʒ]), ӟ [dʑ] (from з [z] ~ [ʑ]) and ӵ [tʃ] (from ч [tɕ]).
Ḧ and ẍ are used for [ħ] and [ʁ] in the unified Kurdish alphabet. These are foreign sounds borrowed from Arabic.
Ẅ and ÿ: Ÿ is generally a vowel, but it is used as the (semi-vowel) consonant [ɰ] (a [w] without the use of the lips) in Tlingit. This sound is also found in Coast Tsimshian, where it is written ẅ.
A number of languages in Vanuatu use double dots on consonants, to represent linguolabial (or apicolabial) phonemes in their orthography. Thus Araki contrasts bilabial p [p] with linguolabial p̈ [t̼]; bilabial m [m] with linguolabial m̈ [n̼]; and bilabial v [β] with linguolabial v̈ [ð̼].
Seneca uses ⟨s̈⟩ for [ʃ].
The letter ẗ is used in the ISO 233 transliteration of Arabic for tāʾ marbūṭah ة.
Syriac uses a two dots above a letter, called Siyame, to indicate that the word should be understood as plural. For instance, ܒܝܬܐ (bayta) means 'house', while ܒܝ̈ܬܐ (bayte) means 'houses'. The sign is used especially when no vowel marks are present, which could differentiate between the two forms. Although the origin of the Siyame is different from that of the Diaeresis sign, in modern computer systems both are represented by the same Unicode character. This, however, often leads to wrong rendering of the Syriac text.
Computer usage
Character encoding generally treats the umlaut and the diaeresis as the same diacritic mark.
Keyboard input

If letters with double dots are not present on the keyboard (or if they are not recognized by the operating system), there are a number of ways to input them into a computer system.
On several operating systems, double-dotted letters can be written by entering Alt codes. On Microsoft Windows keyboard layouts that do not have double dotted characters, one can especially use Windows Alt keycodes. Double dots are then entered by pressing the left Alt key, and entering the full decimal value of the character's position in the Windows code page on the numeric keypad, provided that the compatible code page is used as a system code page. One can also use numbers from Code page 850; these lack a leading 0. On a Swedish/Finnish keyboard both letters å, ä and ö are present, as well as ¨ to combine with any vowel character, in the same way as ´`^ and ~ accentuation signs. Most modern systems support direct entry of the Unicode code point, unaffected by locality settings.
| Character | Windows Code Page Code | CP850 Code | Unicode |
|---|---|---|---|
| ä | Alt+0228 | Alt+132 | 00E4 |
| ë | Alt+0235 | Alt+137 | 00EB |
| ï | Alt+0239 | Alt+139 | 00EF |
| ö | Alt+0246 | Alt+148 | 00F6 |
| ü | Alt+0252 | Alt+129 | 00FC |
| ÿ | Alt+0255 | Alt+152 | 00FF |
| Ä | Alt+0196 | Alt+142 | 00C4 |
| Ë | Alt+0203 | Alt+211 | 00CB |
| Ï | Alt+0207 | Alt+216 | 00CF |
| Ö | Alt+0214 | Alt+153 | 00D6 |
| Ü | Alt+0220 | Alt+154 | 00DC |
| Ÿ | Alt+0159 | N/A | 0178 |
Apple MacOS, iOS
iOS provides accented letters through press-and-hold on most European Latin-script keyboards, including English. Some keyboard layouts feature combining-accent keys that can add accents to any appropriate letter. A letter with double dots can be produced by pressing ⌥ Option+U, then the letter. This works on English and other keyboards and is documented further in the supplied manuals.
Google Chrome OS
For Chrome OS with US-Extended keyboard setting, the combination is "+(letter).[19] For Chrome OS with UK-extended setting, use AltGr⇧ Shift2, release, then the letter. Alternatively, the Unicode codepoint may be entered directly, using Ctrl+⇧ Shift+u, release, then the four-digit code, then ↵ Enter or Space.[20]
Linux
In some Linux desktop environments a letter with double dots can be produced by pressing AltGr⇧ Shift:, then the letter.
Microsoft Windows
Microsoft Windows allows users to set their US layout keyboard language to International, which supports creation of accented letters by changing the function of some keys into dead keys. If the user enters ", nothing will appear on screen, until the user types another character, after which the characters will be merged if possible, or added independently at once if not. Otherwise, the desired character may generated using the Alt table above.
When using Microsoft Word or Outlook, a letter with double dots can be produced by pressing Ctrl⇧ Shift: and then the letter.
X-windows
X-based systems with a Compose key set in the system can usually insert characters with double dots by typing Compose, quotedbl (i.e. ") followed by the letter. Compose+⇧ Shift, letter may also work, depending on the system's set-up. However, most modern UNIX-like systems also accept the sequence Compose+⇧ Shift+U to initiate the direct input of a Unicode value. Thus, typing Compose+⇧ Shift+U, 00F6, finishing with Space or ↵ Enter, will insert ö into the document.
Dedicated keys
The German keyboard has dedicated keys for ü ö ä. Scandinavian and Turkish keyboards have dedicated keys for their respective language-specific letters, including ö for Swedish, Finnish, and Icelandic, and both ö and ü for Turkish.
Other scripts
For non-Latin scripts, Greek and Russian use press-and-hold for double-dot diacritics on only a few characters. The Greek keyboard has dialytica and dialytica–tonos variants for upsilon and iota (ϋ ΰ ϊ ΐ), but not for ε ο α η ω, following modern monotonic usage. Russian keyboards feature separate keys for е and ё.
On-screen keyboards
The early 21st century has seen noticeable growth in stylus- and touch-operated interfaces, making the use of on-screen keyboards operated by pointing devices (mouse, stylus, or finger) more important. These "soft" keyboards may replicate the modifier keys found on hardware keyboards, but they may also employ other means of selecting options from a base key, such as right-click or press-and-hold. Soft keyboards may also have multiple contexts, such as letter, numeric, and symbol.
Character encodings
The ISO 8859-1 character encoding includes the letters ä, ë, ï, ö, ü, and their respective capital forms, as well as ÿ in lower case only, with Ÿ added in the revised edition ISO 8859-15 and Windows-1252.
Unicode includes all of ISO-8859 and also provides the double dot as U+00A8 ¨ DIAERESIS and as U+0308 ◌̈ COMBINING DIAERESIS. In addition, there are codepoints for dozens of precomposed characters as shown above, mainly for compatibility with older character encodings.
Both the combining character U+0308 and the precomposed codepoints can be used as umlaut or diaeresis.
Sometimes, there's a need to distinguish between the umlaut sign and the diaeresis sign. ISO/IEC JTC 1/SC 2/WG 2 recommends the following for these cases:
- To represent the umlaut use Combining Diaeresis (U+0308)
- To represent the diaeresis use Combining Grapheme Joiner (CGJ, U+034F) + Combining Diaeresis (U+0308)
As of version 3.2.0, Unicode also provides U+0364 ◌ͤ COMBINING LATIN SMALL LETTER E which can produce the older umlaut typography.
Unicode provides a combining double dot below as U+0324 ◌̤ COMBINING DIAERESIS BELOW.
HTML
In HTML, vowels with double dots can be entered with an entity reference of the form &?uml;, where ? can be any of a, e, i, o, u, y or their majuscule counterparts. With the exception of the uppercase Ÿ, these characters are also available in all of the ISO 8859 character sets and thus have the same codepoints in ISO-8859-1 (-2, -3, -4, -9, -10, -13, -14, -15, -16) and Unicode. The uppercase Ÿ is available in ISO 8859-15 and Unicode, and Unicode provides a number of other letters with double dots as well.
| Character | Replacement | HTML | Unicode |
|---|---|---|---|
| Ä ä | A or Ae a or ae | Ää | U+00C4 U+00E4 |
| Ö ö | O or Oe o or oe | Öö | U+00D6 U+00F6 |
| Ü ü | U or Ue u or ue | Üü | U+00DC U+00FC |
| Character | HTML | Unicode |
|---|---|---|
| Ë ë | Ëë | U+00CB U+00EB |
| Ḧ ḧ | U+1E26 U+1E27 | |
| Ï ï | Ïï | U+00CF U+00EF |
| ẗ | U+1E97 | |
| Ṳ ṳ | U+1E72 U+1E73 | |
| Ẅ ẅ | U+1E84 U+1E85 | |
| Ẍ ẍ | U+1E8C U+1E8D | |
| Ÿ ÿ | Ÿÿ | U+0178 U+00FF |
Note: when replacing umlaut characters with plain ASCII, use ae, oe, etc. for German language, and the simple character replacements for all other languages.
TeX and LaTeX
TeX (and its derivatives, most notably LaTeX) also allows double dots to be placed over letters. The standard way is to use the control sequence \" followed by the relevant letter, e.g. \"u. It is good practice to set the sequence off with curly braces: {\"u} or \"{u}.
TeX's "German" package can be used: it adds the " control sequence (without the backslash) to produce the Umlaut. However, this can cause conflicts if the main language of the document is not German. Since the integration of Unicode through the development of XeTeX and XeLaTeX, it is also possible to input the Unicode character directly into the document, using one of the recognized methods such as Compose key or direct Unicode input.
TeX's traditional control sequences can still be used and will produce the same output (in very early versions of TeX these sequences would produce double dots that were too far above the letter's body).
All these methods can be used with all available font variations (italic, bold etc.).
See also
Notes
- Plural: diaereses; also spelled diæresis or dieresis
- Or trema
- The phonological phenomenon of umlaut occurred in English as well (man ~ men; full ~ fill; goose ~ geese) but English orthography does not indicate this using the umlaut diacritic.
- Note that not all such combinations are necessarily umlauts: In the town names Coesfeld and Raesfeld, for example, the e merely lengthens the preceding vowel ([oː] and [aː], respectively).
References
- The Unicode Standard v 5.0. San Francisco, etc.: Addison-Wesley. 1991–2007. p. 228. ISBN 0-321-48091-0.
- διαίρεσις. Liddell, Henry George; Scott, Robert; A Greek–English Lexicon at the Perseus Project
- τρῆμα. Liddell, Henry George; Scott, Robert; A Greek–English Lexicon at the Perseus Project
- Harry Shaw, 1964. Punctuate It Right. p. 43, Accent Marks: Dieresis: "...it is much less used than formerly, having been largely replaced by the hyphen..."
- Mary Norris (2012-04-26). "The Curse of the Diaeresis". The New Yorker.
The special tool we use here at The New Yorker for punching out the two dots that we then center carefully over the second vowel in such words as “naïve” and “Laocoön” will be getting a workout this year, as the Democrats coöperate to reëlect the President.
- William Johnson, 2004. Bookrolls and scribes in Oxyrhynchus, p 343; examples on pp 259, 315, 334, etc.
- Roger Bagnall, 2009:262. The Oxford handbook of papyrology
- "woordenlijst". woordenlijst.org.
- Burchfield, R.W. (1996). Fowlers's Modern English Usage (3 ed.). Oxford University Press. p. 210. ISBN 0-19-869126-2.
- On Diacritics and Archaïsm. Flakery.org, June 18, 2006.
- diaeresis: December 9, 1998. The Mavens' Word of the Day. Random House.
- Umlauts in English?. General Questions. Straight Dope Message Board.
- Hardwig, Florian. "Unusual Umlauts (German)". Typojournal. Retrieved 15 July 2015.
- Hardwig, Florian. "Jazz in Town". Fonts in Use. Retrieved 15 July 2015.
- "Flickr collection: vertical umlauts". Flickr. Retrieved 15 July 2015.
- Hardwig, Florian. "Compact umlaut". Fonts in Use. Retrieved 15 July 2015.
- Māori Orthographic Conventions, Māori Language Commission, accessed 11 June 2010.
- "Māori language on the internet", Te Ara
- Angela Randall (February 18, 2014). "How to Write Foreign Character Accents Using Your Chromebook". Retrieved March 2, 2020.
- Jack Busch (April 20, 2018). "Type Special Characters with a Chromebook (Accents, Symbols, Em Dashes)". groovypost.com. Retrieved February 28, 2020.
External links
| Look up ä, Ë, ë, or ö in Wiktionary, the free dictionary. |
- Keyboard Help – Learn how to create world language accent marks and other diacriticals on a computer