Unicode input
Unicode input is the insertion of a specific Unicode character on a computer by a user; it is a common way to input characters not directly supported by a physical keyboard. Unicode characters can be produced either by selecting them from a display or by typing a certain sequence of keys on a physical keyboard. In addition, a character produced by one of these methods in one web page or document can be copied into another. In contrast to ASCII's 96 element character set (which it contains), Unicode encodes hundreds of thousands of glyphs (characters) from almost all of the world's written languages and many other signs and symbols besides.[1]
A Unicode input system must provide for a large repertoire of characters, ideally all valid Unicode code points. This is different from a keyboard layout which defines keys and their combinations only for a limited number of characters appropriate for a certain locale.
Unicode numbers
Unicode characters are distinguished by code points, which are conventionally represented by "U+" followed by four, five or six hexadecimal digits, for example U+00AE or U+1D310. Characters in the Basic Multilingual Plane (BMP), containing modern scripts – including many Chinese and Japanese characters – and many symbols, have a 4-digit code. Historic scripts, but also many modern symbols and pictographs (such as emoticons, emojis, playing cards and many CJK characters) have 5-digit codes.
Availability
An application can display a character only if it can access a font which contains a glyph for the character.[2] Very few fonts have full Unicode coverage; most only contain the glyphs needed to support a few writing systems. However, most modern browsers and other text-processing applications are able to display multilingual content because they perform font substitution, automatically switching to a fallback font when necessary to display characters which are not supported in the current font. Which fonts are used for fallback and the thoroughness of Unicode coverage varies by software and operating system; some software will search for a suitable glyph in all of the installed fonts, others only search within certain fonts.
If an application does not have access to a font supporting a character, the character will usually be shown as a question mark, the replacement character � (U+FFFD), or the font's ".notdef." character (sometimes called a "tofu" due to looking like an empty box, some fonts have a box with a cross in it).[3] Modern implementations use .notdef. for unsupported characters, and the replacement character only for encoding errors.
Selection from a screen
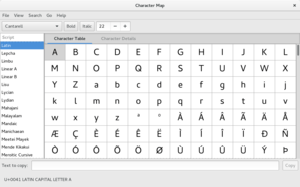
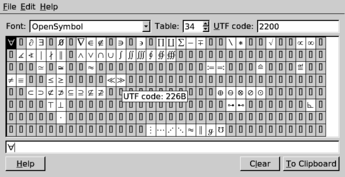
Many systems provide a way to select Unicode characters visually. ISO/IEC 14755 refers to this as a screen-selection entry method.[4]
Microsoft Windows has provided a Unicode version of the Character Map program, appearing in the consumer edition since XP. This is limited to characters in the Basic Multilingual Plane (BMP). Characters are searchable by Unicode character name, and the table can be limited to a particular code block.[5]
More advanced third-party tools of the same type are also available (a notable freeware example is BabelMap, which supports all Unicode characters).[6]
On most Linux desktop environments, equivalent tools – such as gucharmap (GNOME) or kcharselect (KDE) – are available.[7]
Decimal input
Microsoft Windows can input at least some Unicode code points using decimal typed on the numeric keypad by using Alt codes. For example, the division sign has code point U+00F7 and F716 equals decimal 247, so Alt+0247 produces a '÷' (The leading zero is essential; Alt+247 produces a '≈' from CP437). In many applications this only works for numbers less than 256.
The text editor Vim allows characters to be specified by two-character mnemonics (confusingly called "digraphs" by Vim developers). The installed set can be augmented by custom mnemonics defined for arbitrary code points, specified in decimal. For example, as decimal 9881 is equal to hexadecimal 2699, dig Gr 9881 associates "Gr" with U+2699 ⚙ GEAR.
Hexadecimal input
Clause 5.1 of ISO/IEC 14755 describes a Basic method whereby a beginning sequence is followed by the hex number representation of the code point and the ending sequence. Most modern systems have some method to emulate this, sometimes limited to four digits (thus only the Basic Multilingual Plane).
In Microsoft Windows
Hexadecimal Unicode input can be enabled by adding a string type (REG_SZ) value called EnableHexNumpad to the registry key HKEY_CURRENT_USER\Control Panel\Input Method and assigning the value data 1 to it. Users will need to log off and back in after editing the registry for this input method to start working. (In versions earlier than Vista, users needed to reboot for it to start working.)
Unicode characters can then be entered by holding down Alt, and typing + on the numeric keypad, followed by the hexadecimal code – using the numeric keypad for digits from 0 to 9 and letter keys for A to F – and then releasing Alt.[2] This may not work for 5-digit hexadecimal codes like U+1F937.
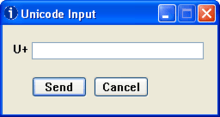
If one prefers not to edit the registry or if, as on many laptops, the numeric keypad is unavailable, the utility UnicodeInput can be downloaded.[8] If one invokes this program when typing text, the window shown on the right appears; entering the hexadecimal value and pressing ↵ Enter then produces the desired character and makes the window disappear.
AutoHotkey scripts support substitution of Unicode characters for keystrokes. For example, the command Send {U+2014} will insert an em dash in a text field in the active window.[9]
In some applications (Word, WordPad and LibreOffice programs) a simpler method is supported: one first enters the character's hexadecimal code (between two and six hexadecimal digits), then types Alt+X which will replace the digits with the Unicode character. For example, entering f1 and then pressing the combination will produce the character 'ñ'. Unless it is six hexadecimal digits long, the code must not be preceded by any digit or letters a–f as they will be treated as part of the code to be converted. For example, entering af1 followed by Alt+X will produce '૱' (U+0AF1), but entering a0000f1 followed by Alt+X will produce 'añ'.
In MacOS
Hex input of Unicode must be enabled. In Mac OS 8.5 and later, one can choose the Unicode Hex Input keyboard layout; in OS X (10.10) Yosemite, this can be added in Keyboard → Input Sources.
Holding down ⌥ Option, one types the four-digit hexadecimal Unicode code point and the equivalent character appears; one can then release the ⌥ Option key.[10] Characters outside of the BMP (the Basic Multilingual Plane) exceed the four-digit limit of the Unicode hex input mechanism but can be entered by using surrogate pairs: holding down the ⌥ Option key while entering the first surrogate, the +, the second surrogate, then releasing the Option key.
In X11 (Linux and other Unix variants including Chrome OS)
In many applications one or both of the following methods work to directly input Unicode characters:
- Holding Ctrl+⇧ Shift and typing u followed by the hex digits, then releasing Ctrl+⇧ Shift.
- Entering Ctrl+⇧ Shift+u, releasing, then typing the hex digits and pressing ↵ Enter (or Space or even, on some systems, pressing and releasing ⇧ Shift or Ctrl ).[11]
This is supported by GTK and Qt applications, and possibly others. In Chrome OS, this is an operating system function.[11]
In platform-independent applications
- In Emacs, Ctrl+x8↵ Enter or Meta+x
insert-char. - In LibreOffice 5.1 onwards, the Alt+X method described above for Windows works.
- In Opera versions that use the Presto layout engine—i.e. up to and including version 12.xx—, entering the hexadecimal number of the desired symbol or character and then pressing Ctrl+⇧ Shift+x (alternative shortcut Meta+⇧ Shift++x on macOS).
- In the Vim editor, in insert mode, the user first types Ctrl+V u (for codepoints up to 4 hex digits long; using Ctrl+V ⇧ Shift+U for longer), then types in the hexadecimal number of the symbol or character desired, and it will be converted into the symbol. (On Microsoft Windows, Ctrl+Q may be required instead of Ctrl+V.[12])
- In AutoCAD
\U2300or three shortcuts%%c,%%d,%%p.
HTML
In HTML and XML, character codes to be rendered as characters are prefixed by ampersand and number sign (&#), and are followed by a semicolon (;). The code point can be either in decimal or in hexadecimal; in the latter case it is preceded by an "x". Leading zeros may be omitted. A number of characters may be represented by a named entity.
Example: In HTML/XML, the copyright sign © (U+00A9) may be coded as:
©(decimal code point)©(hexadecimal code point)©(entity name)
This works in many pieces of software that accept HTML markup, such as Thunderbird and Wikipedia editing.
See also
- ASCII
- Digraph (programming)
- AltGr key
- Compose key
References
- Lafontaine, Sylvain (February 17, 2012). "Unicode vs ASCII difference and benefits". MSDN. Retrieved 28 February 2014.
- Andrew Marcuse, "How to enter Unicode characters in Microsoft Windows". Access date: September 13, 2012
- https://www.quora.com/What-symbol-is-the-square-box-shown-for-non-representable-Unicode-characters
- "ISO/IEC 14755:1997 Information technology -- Input methods to enter characters from the repertoire of ISO/IEC 10646 with a keyboard or other input device". ISO. Retrieved 2017-10-14.
- "How to Insert Special Characters with Windows 7 Character Map". dummies.com. Retrieved 2018-12-05.
- "Ancient Signs: The Alphabet & the Origins of Writing". books.google.com. Retrieved 2018-12-05.
- Peck, Akkana (2009-11-25). "Mastering Characters Sets in Linux (Weird Characters, part 2)". LinuxPlanet. Retrieved 2018-12-05.
- Opris, Elena. "UnicodeInput Review". Softpedia. Retrieved November 28, 2018.
- "Send Keys & Clicks". AutoHotkey Foundation LLC. Copyright © 2003–2018.
- typing special and accented characters Archived 2008-03-09 at the Wayback Machine
- Jack Busch (April 20, 2018). "Type Special Characters with a Chromebook (Accents, Symbols, Em Dashes)". groovypost.com. Retrieved February 28, 2020.
- Vim documentation: gui_w32