DnaG
DnaG is a bacterial DNA primase and is encoded by the dnaG gene. The enzyme DnaG, and any other DNA primase, synthesizes short strands of RNA known as oligonucleotides during DNA replication. These oligonucleotides are known as primers because they act as a starting point for DNA synthesis. DnaG catalyzes the synthesis of oligonucleotides that are 10 to 60 nucleotides (the fundamental unit of DNA and RNA) long, however most of the oligonucleotides synthesized are 11 nucleotides.[1] These RNA oligonucleotides serve as primers, or starting points, for DNA synthesis by bacterial DNA polymerase III (Pol III). DnaG is important in bacterial DNA replication because DNA polymerase cannot initiate the synthesis of a DNA strand, but can only add nucleotides to a preexisting strand.[2] DnaG synthesizes a single RNA primer at the origin of replication. This primer serves to prime leading strand DNA synthesis. For the other parental strand, the lagging strand, DnaG synthesizes an RNA primer every few kilobases (kb). These primers serve as substrates for the synthesis of Okazaki fragments.[3]
| DNA primase | |||||||
|---|---|---|---|---|---|---|---|
| Identifiers | |||||||
| Organism | |||||||
| Symbol | dnaG | ||||||
| Alt. symbols | dnaP | ||||||
| Entrez | 947570 | ||||||
| PDB | 1D0Q, 1DD9, 1DDE, 1EQ9, 2R6A, 2R6C | ||||||
| RefSeq (Prot) | NP_417538 | ||||||
| UniProt | P0ABS5 | ||||||
| Other data | |||||||
| EC number | 2.7.7.7 | ||||||
| Chromosome | chromosome: 3.21 - 3.21 Mb | ||||||
| |||||||
In E. coli DnaG associates through noncovalent interactions with bacterial replicative helicase DnaB to perform its primase activity, with three DnaG primase proteins associating with each DnaB helicase to form the primosome.[4] Primases tend to initiate synthesis at specific three nucleotide sequences on single-stranded DNA (ssDNA) templates and for E. coli DnaG the sequence is 5'-CTG-3'.[1]
DnaG contains three separate protein domains: a zinc binding domain, an RNA polymerase domain, and a DnaB helicase binding domain. There are several bacteria that use the DNA primase DnaG. A few organisms that have DnaG as their DNA primase are Escherichia coli (E. coli), Bacillus stearothermophilus, and Mycobacterium tuberculosis (MTB). E. coli DnaG has a molecular weight of 60 kilodaltons (kDa) and contains 581 amino acids.
Function
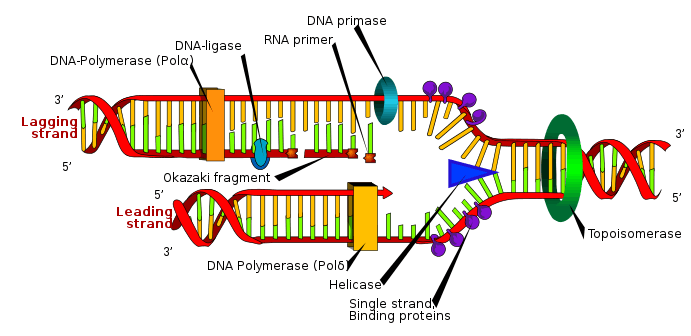
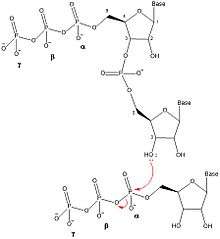
DnaG catalyzes the synthesis of oligonucleotides in five discrete steps: template binding, nucleoside triphosphate (NTP) binding, initiation, extension to form a primer, and primer transfer to DNA polymerase III.[1] DnaG performs this catalysis near the replication fork that is formed by DnaB helicase during DNA replication. DnaG must be complexed with DnaB in order for it to catalyze the formation of the oligonucleotide primers.[1]
The mechanism for primer synthesis by primases involves two NTP binding sites on the primase protein (DnaG).[5] Prior to the binding of any NTPs to form the RNA primer, the ssDNA template sequence binds to DnaG. The ssDNA contains a three nucleotide recognition sequence that recruits NTPs based on Watson-Crick base pairing.[1] After binding DNA, DnaG must bind two NTPs in order to generate an enzyme-DNA-NTP-NTP quaternary complex. The Michaelis constant's (km) for the NTPs vary depending on the primase and templates.[6] The two NTP binding sites on DnaG are referred to as the initiation site and elongation site. The initiation site is the site at which the NTP to be incorporated at the 5' end of the primer binds. The elongation site binds the NTP that is added to the 3' end of the primer.
Once two nucleotides are bound to the primase, DnaG catalyzes the formation of a dinucleotide by forming a phosphodiester bond via dehydration synthesis between the 3' hydroxyl of the nucleotide in the initiation site and the α-phosphate of the nucleotide in the elongation site. This reaction results in a dinucleotide and breaking of the bond between the α and β phosphorus, releasing pyrophosphate. This reaction is irreversible because the pyrophosphate that is formed is hydrolyzed into two inorganic phosphate molecules by the enzyme inorganic pyrophosphatase.[7] This dinucleotide synthesis reaction is the same reaction as any other enzyme that catalyzes the formation of DNA or RNA (DNA Polymerase, RNA Polymerase), therefore DnaG must always synthesize oligonucleotides in the 5' to 3' direction. In E. coli, primers begin with a triphosphate adenine-guanine (pppAG) dinucleotide at the 5' end.
In order for further elongation of the dinucleotide to occur, oligonucleotide must be moved so that the 3' NTP is transferred from the elongation site to the initiation site, allowing for another NTP to bind to the elongation site and attach to the 3' hydroxyl of the oligonucleotide. Once an oligonucleotide of appropriate length has been synthesized from the elongation step of primer synthesis, DnaG transfers the newly synthesized primer to DNA polymerase III for it to synthesize the DNA leading strand or Okazaki fragments for the lagging strand.[1] The rate limiting step of the primer synthesis occurs after NTP binding but before or during dinucleotide synthesis.[6]
Structure
The E. Coli DnaG primase is a 581 residue monomeric protein with three functional domains, according to proteolysis studies. There is an N-terminal Zinc-binding domain (residues 1-110) where a zinc ion is tetrahedrally coordinated between one histidine and three cysteine residues, which plays a role in recognizing sequence specific DNA binding sites. The central domain (residues 111-433) displays RNA polymerase activities, and is the site of RNA primer synthesis. The C-terminal domain (residues 434-581) is responsible for the noncovalent binding of DnaG to the DnaB helicase protein.[8]
Zinc-Binding Domain
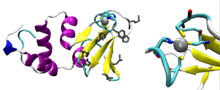
The zinc-binding domain, the domain responsible for recognizing sequence specific DNA binding sites, is conserved across all viral, bacteriophage, prokaryotic and eukaryotic DNA primases.[9] The primase zinc-binding domain is part of the subfamily of zinc-binding domains known as the zinc ribbon. Zinc ribbon domains are characterized by two β-hairpin loops which form the zinc-binding domain. Typically, zinc ribbon domains are thought to lack α-helices, distinguishing them from other zinc-binding domains. However, in 2000 DnaG’s zinc-binding domain was crystallized from Bacillus stearothermophilus revealing that the domain consisted of a five stranded antiparallel β sheet adjacent to four α helices and a 310 helix on the c-terminal end of the domain.[9]
The zinc-binding site of B. stearothermophilus consists of three cysteine residues, Cys40, Cys61, and Cys64, and one histidine residue, His43. Cys40 and His43 are located on the β-hairpin between the second and third β sheet.[9] Cys61 is located on the fifth β sheet, and Cys64 is on the β-hairpin between the fourth and fifth β sheet. These four residues coordinate the zinc ion tetrahedrally. The zinc ion is thought to stabilize the loops between the second and third β sheet as well as the fourth and fifth β sheet. The domain is further stabilized by a number of hydrophobic interactions between the hydrophobic inner surface of the β sheet which is packed against the second and third α helices. The outer surface of the β sheet also has many conserved hydrophobic and basic residues. These residues are Lys30, Arg34, Lys46, Pro48, Lys56, Ile58, His60 and Phe62.[9]
DNA Binding
It is thought that the function of the zinc binding domain is for sequence specific DNA recognition. DNA primases make RNA primers which are then used for DNA synthesis. The placement of the RNA primers is not random, suggesting that they are placed on specific DNA sequences. Indeed, other DNA primases have been shown to recognize triplet sequences; the specific sequence recognized by B. stearothermophilus has not yet been identified.[9] It has been shown that if the cystine residues that coordinate the zinc ion are mutated, the DNA primase stops functioning. This indicates that the zinc-binding domain does play a role in sequence recognition. In addition, the hydrophobic surface of the β sheet, as well as the basic residues which are clustered primarily on one edge of the sheet, serve to attract single stranded DNA, further facilitating DNA binding.[9]
Based on previous studies of DNA binding by DNA Primases, it is thought that DNA binds to the zinc-binding domain across the surface of the β sheet, with the three nucleotides binding across three strands of the β sheet.[9] The positively charged residues in the sheet would be able to form contacts with the phosphates and the aromatic residues would form stacking interactions with the bases. This is the model of DNA binding by the ssDNA-binding domain of replication protein A (RPA).[9] It is logical to assume that B. stearothermophilus’ zinc-binding domain binds DNA in a similar manner, as the residues important for binding DNA in RPA occur in structurally equivalent positions in B. stearothermophilus.[9]
RNA Polymerase Domain
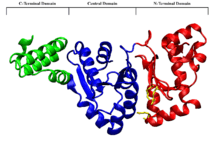
As its name suggests, the RNA polymerase domain (RNAP) of DnaG is responsible for synthesizing the RNA primers on the single stranded DNA. In-vivo, DnaG is able to synthesis primer fragments of up to 60 nucleotides, but in-vivo primer fragments are limited to approximately 11 nucleotides.[10] During the synthesis of the lagging strand DnaG synthesizes between 2000 and 3000 primers at a rate of one primer per-second.[10]
RNAP domain of DnaG has three subdomains, the N-terminal domain, which has a mixed α and β fold, the central domain consisting of a 5 stranded β sheet and 6 α helices, and finally the C-terminal domain which is made up of a helical bundle consisting of 3 antiparallel α helices. The central domain is made up in part of the toprim fold, a fold that has been observed in many metal-binding phosphotransfer proteins. The central domain and the N-terminal domain form a shallow cleft, which makes up the active site of the RNA chain elongation in DnaG.[10] The opening of the cleft is lined by several highly conserved basic residues: Arg146, Arg221, and Lys229. These residues are part of the electrostatically positive ridge of the N-terminal subdomain. It is this ridge that interacts with the ssDNA and helps guide it into the cleft, which consists of the metal binding center of the toprim motif on the central subdomain, and the conserved primase motifs of the N-terminal domain.[10] The metal binding site of the toprim domain is where the primer is synthesized. The RNA:DNA duplex then exits through another basic depression.
C-Terminal Domain
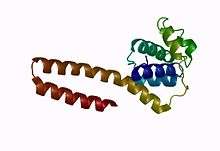
Unlike both the zinc-binding domains, and the RNA polymerase domains, the C-terminal domains of DNA primases are not conserved. In prokaryotic primases, the only known function of this domain is to interact with the helicase, DnaB.[1] Thus, this domain is called the helicase binding domain (HBD). The HBD of DnaG consists of two subdomains: a helical bundle, the C1 subdomain, and a helical hairpin, the C2 subdomain.[4][11] For each of the two to three DnaG molecules that bind the DnaB hexamer, the C1 subdomains of the HBDs interact with DnaB at its N-terminal domains on the inner surface of the hexamer ring, while the C2 subdomains interact with the N-terminal domains on the outer surface of the hexamer.

Three residues in B. stearothermophilus DnaB have been identified as important for formation of the DnaB, DnaG interface. Those residues include Tyr88, Ile119, and Ile125.[4] Tyr88 is close in proximity to, but does not make contact with, the HBD of DnaG. Mutation of Tyr88 inhibits the formation of the N-terminal domain helical bundle of DnaB, interrupting the contacts with the HBD of DnaG.[4] The hexameric structure of DnaB is really a trimer of dimers. Both Ile119 and Ile125 are buried in the N-terminal domain dimer interface of DnaB and mutation of these residues inhibits formation of the hexameric structure and thus the interaction with DnaG.[4] One other residue that has been identified as playing a crucial role in the interaction of DnaB and DnaG is Glu15. Mutation of Glu15 does not disrupt the formation of the DnaB, DnaG complex, but instead plays a role in modulating the length of primers synthesized by DnaG.[4]
Inhibition of DnaG
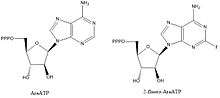
Inhibitors of DNA primases are valuable compounds for the elucidation of biochemical pathways and key interactions, but they are also of interest as lead compounds to design drugs against bacterial diseases. Most of the compounds known to inhibit primases are nucleotide analogs such as AraATP (see Vidarabine) and 2-fluoro-AraATP. These compounds will often be used as substrates by the primase, but once incorporated synthesis or elongation can no longer occur. For example, E. coli DnaG will use 2',3'-dideoxynucleoside 5'-triphosphates (ddNTPs) as substrates, which act as chain terminators due to the lack of a 3' hydroxyl to form a phosphodiester bond with the next nucleotide.[1]
The relatively small number of primase inhibitors likely reflects the inherent difficulty of primase assays rather than a lack of potential binding sites on the enzyme. The short length of products synthesized and the generally slow rate of the enzyme compared to other replication enzymes make developing high-throughput screening (HTS) approaches more difficult.[6] Despite the difficulties, there are several known inhibitors of DnaG that are not NTP analogues. Doxorubicin and suramin are both DNA and NTP competitive inhibitors of Mycobacterium Tuberculosis DnaG.[12] Suramin is also known to inhibit eukaryotic DNA primase by competing with GTP, so suramin is likely to inhibit DnaG via a similar mechanism.[1]
External links
- dnaG+protein,+E+coli at the US National Library of Medicine Medical Subject Headings (MeSH)
- DnaG+(Primase) at the US National Library of Medicine Medical Subject Headings (MeSH)
References
- Frick DN, Richardson CC (2001). "DNA primase". Annual Review of Biochemistry. 70: 39–80. doi:10.1146/annurev.biochem.70.1.39. PMID 11395402. S2CID 33197061.
- Russell P (2009). iGenetics: A Molecular Approach (3rd ed.). Benjamin Cummings. pp. 42–43. ISBN 978-0321772886.
- Nelson D, Cox M (2008). Lehninger Principles of Biochemistry (5th ed.). New York: W.H. Freeman and Company. pp. 986–989. ISBN 978-0716771081.
- Bailey S, Eliason WK, Steitz TA (19 October 2007). "Structure of Hexameric DnaB Helicase and Its complex with a Domain of DnaG Primase". Science. 318 (5849): 459–63. doi:10.1126/science.1147353. PMID 17947583.
- Frick DN, Kumar S, Richardson CC (10 December 1999). "Interaction of ribonucleoside triphosphates with the gene 4 primase of bacteriphage T7". Journal of Biological Chemistry. 274 (50): 35899–907. doi:10.1074/jbc.274.50.35899. PMID 10585475.
- Kuchta RD, Stengel G (May 2010). "Mechanism and evolution of DNA primases". Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics. 1804 (5): 1180–9. doi:10.1016/j.bbapap.2009.06.011. PMC 2846230. PMID 19540940.
- Bruice PY (2007). Organic Chemistry (5th ed.). Pearson Education, Inc. pp. 1202–1203. ISBN 978-0-13-199631-1.
- Voet, Donald (2010). Biochemistry (4th ed.). New York: J. Wiley & Sons. p. 1189. ISBN 978-0-470-57095-1.
- Pan H, Wigley DB (15 March 2000). "Structure of the zinc-binding domain of Bacillus stearothermophilus DNA primase". Structure. 8 (3): 231–9. doi:10.1016/S0969-2126(00)00101-5. PMID 10745010.
- Keck JA, Roche DD, Lynch AS, Berger JM (31 March 2000). "Structure of the RNA Polymerase Domain of E. coli Primase". Science. 287 (5462): 2482–6. doi:10.1126/science.287.5462.2482. PMID 10741967. S2CID 27005599.
- Oakley AJ, Loscha KV, Schaeffer PM, Liepinsh E, Pintacuda G, Wilce MCJ, Otting G, Dixon NE (15 January 2005). "Crystal and Solution Structures of the Helicase-binding Domain of Escherichia coli Primase". The Journal of Biological Chemistry. 280 (12): 11495–11504. doi:10.1074/jbc.M412645200. PMID 15649896.
- Biswas T, Resto-Roldan E, Sawyer SK, Artsimovitch I, Tsodikov OV (December 2012). "A novel non-radioactive primase-pyrophosphatase activity assay and its application to the discovery of inhibitors of Mycobacterium tuberculosis primase DnaG". Nucleic Acids Research. 41 (4): e56. doi:10.1093/nar/gks1292. PMC 3575809. PMID 23267008.