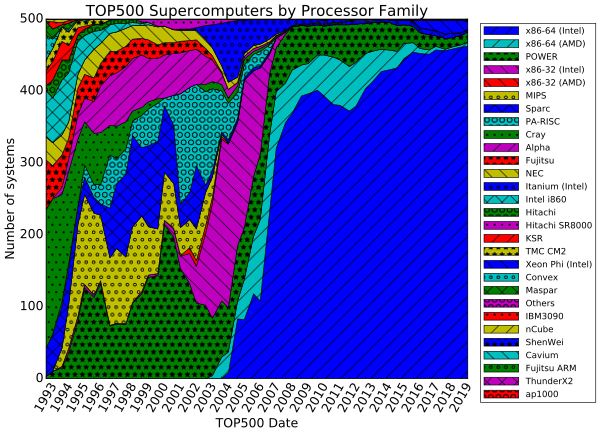
Supercomputer
A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, there are supercomputers which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS).[3] Since November 2017, all of the world's fastest 500 supercomputers run Linux-based operating systems.[4] Additional research is being conducted in China, the United States, the European Union, Taiwan and Japan to build faster, more powerful and technologically superior exascale supercomputers.[5]

Supercomputers play an important role in the field of computational science, and are used for a wide range of computationally intensive tasks in various fields, including quantum mechanics, weather forecasting, climate research, oil and gas exploration, molecular modeling (computing the structures and properties of chemical compounds, biological macromolecules, polymers, and crystals), and physical simulations (such as simulations of the early moments of the universe, airplane and spacecraft aerodynamics, the detonation of nuclear weapons, and nuclear fusion). They have been essential in the field of cryptanalysis.[6]
Supercomputers were introduced in the 1960s, and for several decades the fastest were made by Seymour Cray at Control Data Corporation (CDC), Cray Research and subsequent companies bearing his name or monogram. The first such machines were highly tuned conventional designs that ran faster than their more general-purpose contemporaries. Through the decade, increasing amounts of parallelism were added, with one to four processors being typical. From the 1970s, vector processors operating on large arrays of data came to dominate. A notable example is the highly successful Cray-1 of 1976. Vector computers remained the dominant design into the 1990s. From then until today, massively parallel supercomputers with tens of thousands of off-the-shelf processors became the norm.[7][8]
The US has long been the leader in the supercomputer field, first through Cray's almost uninterrupted dominance of the field, and later through a variety of technology companies. Japan made major strides in the field in the 1980s and 90s, with China becoming increasingly active in the field. As of June 2020, the fastest supercomputer on the TOP500 supercomputer list is Fugaku, in Japan, with a LINPACK benchmark score of 415 PFLOPS, followed by Summit, by around 266.7 PFLOPS.[9] The US has four of the top 10; China and Italy have two each, Switzerland has one.[9] In June 2018, all combined supercomputers on the list broke the 1 exaFLOPS mark.[10]
History



In 1960 UNIVAC built the Livermore Atomic Research Computer (LARC), today considered among the first supercomputers, for the US Navy Research and Development Centre. It still used high-speed drum memory, rather than the newly emerging disk drive technology.[11] Also among the first supercomputers was the IBM 7030 Stretch. The IBM 7030 was built by IBM for the Los Alamos National Laboratory, which in 1955 had requested a computer 100 times faster than any existing computer. The IBM 7030 used transistors, magnetic core memory, pipelined instructions, prefetched data through a memory controller and included pioneering random access disk drives. The IBM 7030 was completed in 1961 and despite not meeting the challenge of a hundredfold increase in performance, it was purchased by the Los Alamos National Laboratory. Customers in England and France also bought the computer and it became the basis for the IBM 7950 Harvest, a supercomputer built for cryptanalysis.[12]
The third pioneering supercomputer project in the early 1960s was the Atlas at the University of Manchester, built by a team led by Tom Kilburn. He designed the Atlas to have memory space for up to a million words of 48 bits, but because magnetic storage with such a capacity was unaffordable, the actual core memory of Atlas was only 16,000 words, with a drum providing memory for a further 96,000 words. The Atlas operating system swapped data in the form of pages between the magnetic core and the drum. The Atlas operating system also introduced time-sharing to supercomputing, so that more than one program could be executed on the supercomputer at any one time.[13] Atlas was a joint venture between Ferranti and the Manchester University and was designed to operate at processing speeds approaching one microsecond per instruction, about one million instructions per second.[14]
The CDC 6600, designed by Seymour Cray, was finished in 1964 and marked the transition from germanium to silicon transistors. Silicon transistors could run faster and the overheating problem was solved by introducing refrigeration to the supercomputer design.[15] Thus the CDC6600 became the fastest computer in the world. Given that the 6600 outperformed all the other contemporary computers by about 10 times, it was dubbed a supercomputer and defined the supercomputing market, when one hundred computers were sold at $8 million each.[16][17][18][19]
Cray left CDC in 1972 to form his own company, Cray Research.[17] Four years after leaving CDC, Cray delivered the 80 MHz Cray-1 in 1976, which became one of the most successful supercomputers in history.[20][21] The Cray-2 was released in 1985. It had eight central processing units (CPUs), liquid cooling and the electronics coolant liquid fluorinert was pumped through the supercomputer architecture. It performed at 1.9 gigaFLOPS and was the world's second fastest after M-13 supercomputer in Moscow.[22]
Massively parallel designs

The only computer to seriously challenge the Cray-1's performance in the 1970s was the ILLIAC IV. This machine was the first realized example of a true massively parallel computer, in which many processors worked together to solve different parts of a single larger problem. In contrast with the vector systems, which were designed to run a single stream of data as quickly as possible, in this concept, the computer instead feeds separate parts of the data to entirely different processors and then recombines the results. The ILLIAC's design was finalized in 1966 with 256 processors and offer speed up to 1 GFLOPS, compared to the 1970s Cray-1's peak of 250 MFLOPS. However, development problems led to only 64 processors being built, and the system could never operate faster than about 200 MFLOPS while being much larger and more complex than the Cray. Another problem was that writing software for the system was difficult, and getting peak performance from it was a matter of serious effort.
But the partial success of the ILLIAC IV was widely seen as pointing the way to the future of supercomputing. Cray argued against this, famously quipping that "If you were plowing a field, which would you rather use? Two strong oxen or 1024 chickens?"[23] But by the early 1980s, several teams were working on parallel designs with thousands of processors, notably the Connection Machine (CM) that developed from research at MIT. The CM-1 used as many as 65,536 simplified custom microprocessors connected together in a network to share data. Several updated versions followed; the CM-5 supercomputer is a massively parallel processing computer capable of many billions of arithmetic operations per second.[24]
In 1982, Osaka University's LINKS-1 Computer Graphics System used a massively parallel processing architecture, with 514 microprocessors, including 257 Zilog Z8001 control processors and 257 iAPX 86/20 floating-point processors. It was mainly used for rendering realistic 3D computer graphics.[25] Fujitsu's VPP500 from 1992 is unusual since, to achieve higher speeds, its processors used GaAs, a material normally reserved for microwave applications due to its toxicity.[26] Fujitsu's Numerical Wind Tunnel supercomputer used 166 vector processors to gain the top spot in 1994 with a peak speed of 1.7 gigaFLOPS (GFLOPS) per processor.[27][28] The Hitachi SR2201 obtained a peak performance of 600 GFLOPS in 1996 by using 2048 processors connected via a fast three-dimensional crossbar network.[29][30][31] The Intel Paragon could have 1000 to 4000 Intel i860 processors in various configurations and was ranked the fastest in the world in 1993. The Paragon was a MIMD machine which connected processors via a high speed two dimensional mesh, allowing processes to execute on separate nodes, communicating via the Message Passing Interface.[32]
Software development remained a problem, but the CM series sparked off considerable research into this issue. Similar designs using custom hardware were made by many companies, including the Evans & Sutherland ES-1, MasPar, nCUBE, Intel iPSC and the Goodyear MPP. But by the mid-1990s, general-purpose CPU performance had improved so much in that a supercomputer could be built using them as the individual processing units, instead of using custom chips. By the turn of the 21st century, designs featuring tens of thousands of commodity CPUs were the norm, with later machines adding graphic units to the mix.[7][8]
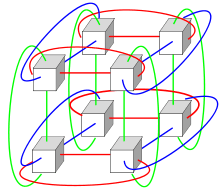
Systems with a massive number of processors generally take one of two paths. In the grid computing approach, the processing power of many computers, organised as distributed, diverse administrative domains, is opportunistically used whenever a computer is available.[33] In another approach, a large number of processors are used in proximity to each other, e.g. in a computer cluster. In such a centralized massively parallel system the speed and flexibility of the interconnect becomes very important and modern supercomputers have used various approaches ranging from enhanced Infiniband systems to three-dimensional torus interconnects.[34][35] The use of multi-core processors combined with centralization is an emerging direction, e.g. as in the Cyclops64 system.[36][37]
As the price, performance and energy efficiency of general purpose graphic processors (GPGPUs) have improved,[38] a number of petaFLOPS supercomputers such as Tianhe-I and Nebulae have started to rely on them.[39] However, other systems such as the K computer continue to use conventional processors such as SPARC-based designs and the overall applicability of GPGPUs in general-purpose high-performance computing applications has been the subject of debate, in that while a GPGPU may be tuned to score well on specific benchmarks, its overall applicability to everyday algorithms may be limited unless significant effort is spent to tune the application towards it.[40][41] However, GPUs are gaining ground and in 2012 the Jaguar supercomputer was transformed into Titan by retrofitting CPUs with GPUs.[42][43][44]
High-performance computers have an expected life cycle of about three years before requiring an upgrade.[45] The Gyoukou supercomputer is unique in that it uses both a massively parallel design and liquid immersion cooling.
Special purpose supercomputers
A number of "special-purpose" systems have been designed, dedicated to a single problem. This allows the use of specially programmed FPGA chips or even custom ASICs, allowing better price/performance ratios by sacrificing generality. Examples of special-purpose supercomputers include Belle,[46] Deep Blue,[47] and Hydra,[48] for playing chess, Gravity Pipe for astrophysics,[49] MDGRAPE-3 for protein structure computation molecular dynamics[50] and Deep Crack,[51] for breaking the DES cipher.
Energy usage and heat management
.jpg)
Throughout the decades, the management of heat density has remained a key issue for most centralized supercomputers.[54][55][56] The large amount of heat generated by a system may also have other effects, e.g. reducing the lifetime of other system components.[57] There have been diverse approaches to heat management, from pumping Fluorinert through the system, to a hybrid liquid-air cooling system or air cooling with normal air conditioning temperatures.[58][59] A typical supercomputer consumes large amounts of electrical power, almost all of which is converted into heat, requiring cooling. For example, Tianhe-1A consumes 4.04 megawatts (MW) of electricity.[60] The cost to power and cool the system can be significant, e.g. 4 MW at $0.10/kWh is $400 an hour or about $3.5 million per year.

Heat management is a major issue in complex electronic devices and affects powerful computer systems in various ways.[61] The thermal design power and CPU power dissipation issues in supercomputing surpass those of traditional computer cooling technologies. The supercomputing awards for green computing reflect this issue.[62][63][64]
The packing of thousands of processors together inevitably generates significant amounts of heat density that need to be dealt with. The Cray 2 was liquid cooled, and used a Fluorinert "cooling waterfall" which was forced through the modules under pressure.[58] However, the submerged liquid cooling approach was not practical for the multi-cabinet systems based on off-the-shelf processors, and in System X a special cooling system that combined air conditioning with liquid cooling was developed in conjunction with the Liebert company.[59]
In the Blue Gene system, IBM deliberately used low power processors to deal with heat density.[65] The IBM Power 775, released in 2011, has closely packed elements that require water cooling.[66] The IBM Aquasar system uses hot water cooling to achieve energy efficiency, the water being used to heat buildings as well.[67][68]
The energy efficiency of computer systems is generally measured in terms of "FLOPS per watt". In 2008, Roadrunner by IBM operated at 3.76 MFLOPS/W.[69][70] In November 2010, the Blue Gene/Q reached 1,684 MFLOPS/W.[71][72] In June 2011 the top 2 spots on the Green 500 list were occupied by Blue Gene machines in New York (one achieving 2097 MFLOPS/W) with the DEGIMA cluster in Nagasaki placing third with 1375 MFLOPS/W.[73]
Because copper wires can transfer energy into a supercomputer with much higher power densities than forced air or circulating refrigerants can remove waste heat,[74] the ability of the cooling systems to remove waste heat is a limiting factor.[75][76] As of 2015, many existing supercomputers have more infrastructure capacity than the actual peak demand of the machine – designers generally conservatively design the power and cooling infrastructure to handle more than the theoretical peak electrical power consumed by the supercomputer. Designs for future supercomputers are power-limited – the thermal design power of the supercomputer as a whole, the amount that the power and cooling infrastructure can handle, is somewhat more than the expected normal power consumption, but less than the theoretical peak power consumption of the electronic hardware.[77]
Software and system management
Operating systems
Since the end of the 20th century, supercomputer operating systems have undergone major transformations, based on the changes in supercomputer architecture.[78] While early operating systems were custom tailored to each supercomputer to gain speed, the trend has been to move away from in-house operating systems to the adaptation of generic software such as Linux.[79]
Since modern massively parallel supercomputers typically separate computations from other services by using multiple types of nodes, they usually run different operating systems on different nodes, e.g. using a small and efficient lightweight kernel such as CNK or CNL on compute nodes, but a larger system such as a Linux-derivative on server and I/O nodes.[80][81][82]
While in a traditional multi-user computer system job scheduling is, in effect, a tasking problem for processing and peripheral resources, in a massively parallel system, the job management system needs to manage the allocation of both computational and communication resources, as well as gracefully deal with inevitable hardware failures when tens of thousands of processors are present.[83]
Although most modern supercomputers use a Linux-based operating system, each manufacturer has its own specific Linux-derivative, and no industry standard exists, partly due to the fact that the differences in hardware architectures require changes to optimize the operating system to each hardware design.[78][84]
Software tools and message passing

The parallel architectures of supercomputers often dictate the use of special programming techniques to exploit their speed. Software tools for distributed processing include standard APIs such as MPI and PVM, VTL, and open source-based software solutions such as Beowulf.
In the most common scenario, environments such as PVM and MPI for loosely connected clusters and OpenMP for tightly coordinated shared memory machines are used. Significant effort is required to optimize an algorithm for the interconnect characteristics of the machine it will be run on; the aim is to prevent any of the CPUs from wasting time waiting on data from other nodes. GPGPUs have hundreds of processor cores and are programmed using programming models such as CUDA or OpenCL.
Moreover, it is quite difficult to debug and test parallel programs. Special techniques need to be used for testing and debugging such applications.
Distributed supercomputing
Opportunistic approaches
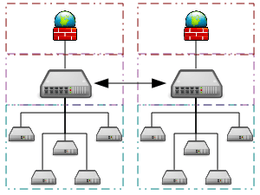
Opportunistic Supercomputing is a form of networked grid computing whereby a "super virtual computer" of many loosely coupled volunteer computing machines performs very large computing tasks. Grid computing has been applied to a number of large-scale embarrassingly parallel problems that require supercomputing performance scales. However, basic grid and cloud computing approaches that rely on volunteer computing cannot handle traditional supercomputing tasks such as fluid dynamic simulations.
The fastest grid computing system is the distributed computing project Folding@home (F@h). F@h reported 2.5 exaFLOPS of x86 processing power As of April 2020. Of this, over 100 PFLOPS are contributed by clients running on various GPUs, and the rest from various CPU systems.[86]
The Berkeley Open Infrastructure for Network Computing (BOINC) platform hosts a number of distributed computing projects. As of February 2017, BOINC recorded a processing power of over 166 petaFLOPS through over 762 thousand active Computers (Hosts) on the network.[87]
As of October 2016, Great Internet Mersenne Prime Search's (GIMPS) distributed Mersenne Prime search achieved about 0.313 PFLOPS through over 1.3 million computers.[88] The Internet PrimeNet Server supports GIMPS's grid computing approach, one of the earliest and most successful grid computing projects, since 1997.
Quasi-opportunistic approaches
Quasi-opportunistic supercomputing is a form of distributed computing whereby the "super virtual computer" of many networked geographically disperse computers performs computing tasks that demand huge processing power.[89] Quasi-opportunistic supercomputing aims to provide a higher quality of service than opportunistic grid computing by achieving more control over the assignment of tasks to distributed resources and the use of intelligence about the availability and reliability of individual systems within the supercomputing network. However, quasi-opportunistic distributed execution of demanding parallel computing software in grids should be achieved through implementation of grid-wise allocation agreements, co-allocation subsystems, communication topology-aware allocation mechanisms, fault tolerant message passing libraries and data pre-conditioning.[89]
High-performance computing clouds
Cloud computing with its recent and rapid expansions and development have grabbed the attention of high-performance computing (HPC) users and developers in recent years. Cloud computing attempts to provide HPC-as-a-service exactly like other forms of services available in the cloud such as software as a service, platform as a service, and infrastructure as a service. HPC users may benefit from the cloud in different angles such as scalability, resources being on-demand, fast, and inexpensive. On the other hand, moving HPC applications have a set of challenges too. Good examples of such challenges are virtualization overhead in the cloud, multi-tenancy of resources, and network latency issues. Much research is currently being done to overcome these challenges and make HPC in the cloud a more realistic possibility.[90][91][92][93]
In 2016 Penguin Computing, R-HPC, Amazon Web Services, Univa, Silicon Graphics International, Sabalcore, and Gomput started to offer HPC cloud computing. The Penguin On Demand (POD) cloud is a bare-metal compute model to execute code, but each user is given virtualized login node. POD computing nodes are connected via nonvirtualized 10 Gbit/s Ethernet or QDR InfiniBand networks. User connectivity to the POD data center ranges from 50 Mbit/s to 1 Gbit/s.[94] Citing Amazon's EC2 Elastic Compute Cloud, Penguin Computing argues that virtualization of compute nodes is not suitable for HPC. Penguin Computing has also criticized that HPC clouds may allocated computing nodes to customers that are far apart, causing latency that impairs performance for some HPC applications.[95]
Performance measurement
Capability versus capacity
Supercomputers generally aim for the maximum in capability computing rather than capacity computing. Capability computing is typically thought of as using the maximum computing power to solve a single large problem in the shortest amount of time. Often a capability system is able to solve a problem of a size or complexity that no other computer can, e.g., a very complex weather simulation application.[96]
Capacity computing, in contrast, is typically thought of as using efficient cost-effective computing power to solve a few somewhat large problems or many small problems.[96] Architectures that lend themselves to supporting many users for routine everyday tasks may have a lot of capacity but are not typically considered supercomputers, given that they do not solve a single very complex problem.[96]
Performance metrics
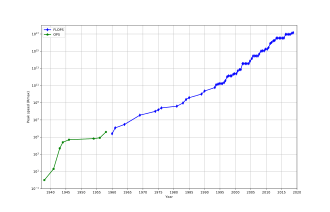
In general, the speed of supercomputers is measured and benchmarked in FLOPS ("floating-point operations per second"), and not in terms of MIPS ("million instructions per second), as is the case with general-purpose computers.[97] These measurements are commonly used with an SI prefix such as tera-, combined into the shorthand "TFLOPS" (1012 FLOPS, pronounced teraflops), or peta-, combined into the shorthand "PFLOPS" (1015 FLOPS, pronounced petaflops.) "Petascale" supercomputers can process one quadrillion (1015) (1000 trillion) FLOPS. Exascale is computing performance in the exaFLOPS (EFLOPS) range. An EFLOPS is one quintillion (1018) FLOPS (one million TFLOPS).
No single number can reflect the overall performance of a computer system, yet the goal of the Linpack benchmark is to approximate how fast the computer solves numerical problems and it is widely used in the industry.[98] The FLOPS measurement is either quoted based on the theoretical floating point performance of a processor (derived from manufacturer's processor specifications and shown as "Rpeak" in the TOP500 lists), which is generally unachievable when running real workloads, or the achievable throughput, derived from the LINPACK benchmarks and shown as "Rmax" in the TOP500 list.[99] The LINPACK benchmark typically performs LU decomposition of a large matrix.[100] The LINPACK performance gives some indication of performance for some real-world problems, but does not necessarily match the processing requirements of many other supercomputer workloads, which for example may require more memory bandwidth, or may require better integer computing performance, or may need a high performance I/O system to achieve high levels of performance.[98]
The TOP500 list
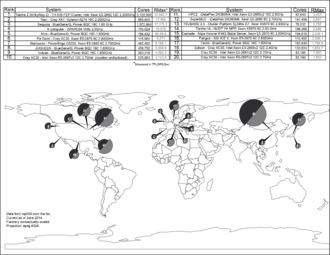
Since 1993, the fastest supercomputers have been ranked on the TOP500 list according to their LINPACK benchmark results. The list does not claim to be unbiased or definitive, but it is a widely cited current definition of the "fastest" supercomputer available at any given time.
This is a recent list of the computers which appeared at the top of the TOP500 list,[101] and the "Peak speed" is given as the "Rmax" rating. In 2018, Lenovo became the world's largest provider for the TOP500 supercomputers with 117 units produced.[102]
| Year | Supercomputer | Rmax (TFlop/s) | Location |
|---|---|---|---|
| 2020 | Fujitsu Fugaku | 415,530.0 | Kobe, Japan |
| 2018 | IBM Summit | 148,600.0 | Oak Ridge, U.S. |
| 2018 | IBM/Nvidia/Mellanox Sierra | 94,640.0 | Livermore, U.S. |
| 2016 | Sunway TaihuLight | 93,014.6 | Wuxi, China |
| 2013 | NUDT Tianhe-2 | 61,444.5 | Guangzhou, China |
| 2019 | Dell Frontera | 23,516.4 | Austin, U.S. |
| 2012 | Cray/HPE Piz Daint | 21,230.0 | Lugano, Switzerland |
| 2015 | Cray/HPE Trinity | 20,158.7 | New Mexico, U.S. |
| 2018 | Fujitsu ABCI | 19,880.0 | Tokyo, Japan |
| 2018 | Lenovo SuperMUC-NG | 19,476.6 | Garching, Germany |
Applications
The stages of supercomputer application may be summarized in the following table:
| Decade | Uses and computer involved |
|---|---|
| 1970s | Weather forecasting, aerodynamic research (Cray-1).[103] |
| 1980s | Probabilistic analysis,[104] radiation shielding modeling[105] (CDC Cyber). |
| 1990s | Brute force code breaking (EFF DES cracker).[106] |
| 2000s | 3D nuclear test simulations as a substitute for legal conduct Nuclear Non-Proliferation Treaty (ASCI Q).[107] |
| 2010s | Molecular Dynamics Simulation (Tianhe-1A)[108] |
| 2020s | Scientific research for outbreak prevention/Electrochemical Reaction Research[109] |
The IBM Blue Gene/P computer has been used to simulate a number of artificial neurons equivalent to approximately one percent of a human cerebral cortex, containing 1.6 billion neurons with approximately 9 trillion connections. The same research group also succeeded in using a supercomputer to simulate a number of artificial neurons equivalent to the entirety of a rat's brain.[110]
Modern-day weather forecasting also relies on supercomputers. The National Oceanic and Atmospheric Administration uses supercomputers to crunch hundreds of millions of observations to help make weather forecasts more accurate.[111]
In 2011, the challenges and difficulties in pushing the envelope in supercomputing were underscored by IBM's abandonment of the Blue Waters petascale project.[112]
The Advanced Simulation and Computing Program currently uses supercomputers to maintain and simulate the United States nuclear stockpile.[113]
In early 2020, Coronavirus was front and center in the world. Supercomputers used different simulations to find compounds that could potentially stop the spread. These computers run for tens of hours using multiple paralleled running CPU's to model different processes.[114][115][116]
Development and trends
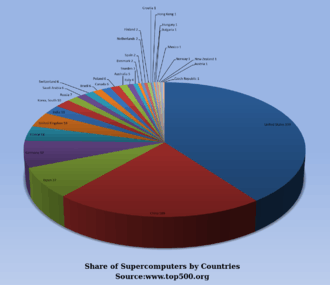
In the 2010s, China, the United States, the European Union, and others competed to be the first to create a 1 exaFLOP (1018 or one quintillion FLOPS) supercomputer.[117] Erik P. DeBenedictis of Sandia National Laboratories has theorized that a zettaFLOPS (1021 or one sextillion FLOPS) computer is required to accomplish full weather modeling, which could cover a two-week time span accurately.[118][119][120] Such systems might be built around 2030.[121]
Many Monte Carlo simulations use the same algorithm to process a randomly generated data set; particularly, integro-differential equations describing physical transport processes, the random paths, collisions, and energy and momentum depositions of neutrons, photons, ions, electrons, etc. The next step for microprocessors may be into the third dimension; and specializing to Monte Carlo, the many layers could be identical, simplifying the design and manufacture process.[122]
The cost of operating high performance supercomputers has risen, mainly due to increasing power consumption. In the mid 1990s a top 10 supercomputer required in the range of 100 kilowatt, in 2010 the top 10 supercomputers required between 1 and 2 megawatt.[123] A 2010 study commissioned by DARPA identified power consumption as the most pervasive challenge in achieving Exascale computing.[124] At the time a megawatt per year in energy consumption cost about 1 million dollar. Supercomputing facilities were constructed to efficiently remove the increasing amount of heat produced by modern multi-core central processing units. Based on the energy consumption of the Green 500 list of supercomputers between 2007 and 2011, a supercomputer with 1 exaflops in 2011 would have required nearly 500 megawatt. Operating systems were developed for existing hardware to conserve energy whenever possible.[125] CPU cores not in use during the execution of a parallelised application were put into low-power states, producing energy savings for some supercomputing applications.[126]
The increasing cost of operating supercomputers has been a driving factor in a trend towards bundling of resources through a distributed supercomputer infrastructure. National supercomputing centres first emerged in the US, followed by Germany and Japan. The European Union launched the Partnership for Advanced Computing in Europe (PRACE) with the aim of creating a persistent pan-European supercomputer infrastructure with services to support scientists across the European Union in porting, scaling and optimizing supercomputing applications.[123] Iceland built the world's first zero-emission supercomputer. Located at the Thor Data Center in Reykjavik, Iceland, this supercomputer relies on completely renewable sources for its power rather than fossil fuels. The colder climate also reduces the need for active cooling, making it one of the greenest facilities in the world of computers.[127]
Funding supercomputer hardware also became increasingly difficult. In the mid 1990s a top 10 supercomputer cost about 10 million Euros, while in 2010 the top 10 supercomputers required an investment of between 40 and 50 million Euros.[123] In the 2000s national governments put in place different strategies to fund supercomputers. In the UK the national government funded supercomputers entirely and high performance computing was put under the control of a national funding agency. Germany developed a mixed funding model, pooling local state funding and federal funding.[123]
In fiction
Many science fiction writers have depicted supercomputers in their works, both before and after the historical construction of such computers. Much of such fiction deals with the relations of humans with the computers they build and with the possibility of conflict eventually developing between them. Examples of supercomputers in fiction include HAL-9000, Multivac, The Machine Stops, GLaDOS, The Evitable Conflict, Vulcan's Hammer, Colossus and Deep Thought.
See also
| Wikimedia Commons has media related to Supercomputers. |
- ACM/IEEE Supercomputing Conference
- ACM SIGHPC
- High-performance technical computing
- Jungle computing
- Nvidia Tesla Personal Supercomputer
- Parallel computing
- Supercomputing in China
- Supercomputing in Europe
- Supercomputing in India
- Supercomputing in Japan
- Testing high-performance computing applications
- Ultra Network Technologies
- Quantum computing
Notes and references
- "IBM Blue gene announcement". 03.ibm.com. 26 June 2007. Retrieved 9 June 2012.
- "Intrepid". Argonne Leadership Computing Facility. Argonne National Laboratory. Archived from the original on 7 May 2013. Retrieved 26 March 2020.
- "The List: June 2018". Top 500. Retrieved 25 June 2018.
- "Operating system Family / Linux". TOP500.org. Retrieved 30 November 2017.
- Anderson, Mark (21 June 2017). "Global Race Toward Exascale Will Drive Supercomputing, AI to Masses." Spectrum.IEEE.org. Retrieved 20 January 2019.
- Lemke, Tim (8 May 2013). "NSA Breaks Ground on Massive Computing Center". Retrieved 11 December 2013.
- Hoffman, Allan R.; et al. (1990). Supercomputers: directions in technology and applications. National Academies. pp. 35–47. ISBN 978-0-309-04088-4.
- Hill, Mark Donald; Jouppi, Norman Paul; Sohi, Gurindar (1999). Readings in computer architecture. pp. 40–49. ISBN 978-1-55860-539-8.
- "Japan Captures TOP500 Crown with Arm-Powered Supercomputer - TOP500 website". www.top500.org.
- "Performance Development - TOP500 Supercomputer Sites". www.top500.org.
- Eric G. Swedin; David L. Ferro (2007). Computers: The Life Story of a Technology. JHU Press. p. 57. ISBN 9780801887741.
- Eric G. Swedin; David L. Ferro (2007). Computers: The Life Story of a Technology. JHU Press. p. 56. ISBN 9780801887741.
- Eric G. Swedin; David L. Ferro (2007). Computers: The Life Story of a Technology. JHU Press. p. 58. ISBN 9780801887741.
- The Atlas, University of Manchester, archived from the original on 28 July 2012, retrieved 21 September 2010
- The Supermen, Charles Murray, Wiley & Sons, 1997.
- Paul E. Ceruzzi (2003). A History of Modern Computing. MIT Press. p. 161. ISBN 978-0-262-53203-7.
- Hannan, Caryn (2008). Wisconsin Biographical Dictionary. State History Publications. pp. 83–84. ISBN 978-1-878592-63-7.
- John Impagliazzo; John A. N. Lee (2004). History of computing in education. Springer Science & Business Media. p. 172. ISBN 978-1-4020-8135-4.
- Andrew R. L. Cayton; Richard Sisson; Chris Zacher (2006). The American Midwest: An Interpretive Encyclopedia. Indiana University Press. p. 1489. ISBN 978-0-253-00349-2.
- Readings in computer architecture by Mark Donald Hill, Norman Paul Jouppi, Gurindar Sohi 1999 ISBN 978-1-55860-539-8 page 41-48
- Milestones in computer science and information technology by Edwin D. Reilly 2003 ISBN 1-57356-521-0 page 65
- "Mikhail A.Kartsev,M1,M4,M10,M13.Development of Computer Science and Technologies in Ukraine". www.icfcst.kiev.ua.
- "Seymour Cray Quotes". BrainyQuote.
- Steve Nelson (3 October 2014). "ComputerGK.com : Supercomputers".
- "LINKS-1 Computer Graphics System-Computer Museum". museum.ipsj.or.jp.
- "VPP500 (1992) - Fujitsu Global".
- "TOP500 Annual Report 1994". Netlib.org. 1 October 1996. Retrieved 9 June 2012.
- N. Hirose & M. Fukuda (1997). Numerical Wind Tunnel (NWT) and CFD Research at National Aerospace Laboratory. Proceedings of HPC-Asia '97. IEEE Computer SocietyPages. doi:10.1109/HPC.1997.592130.
- H. Fujii, Y. Yasuda, H. Akashi, Y. Inagami, M. Koga, O. Ishihara, M. Syazwan, H. Wada, T. Sumimoto, Architecture and performance of the Hitachi SR2201 massively parallel processor system, Proceedings of 11th International Parallel Processing Symposium, April 1997, pages 233–241.
- Y. Iwasaki, The CP-PACS project, Nuclear Physics B: Proceedings Supplements, Volume 60, Issues 1–2, January 1998, pages 246–254.
- A.J. van der Steen, Overview of recent supercomputers, Publication of the NCF, Stichting Nationale Computer Faciliteiten, the Netherlands, January 1997.
- Scalable input/output: achieving system balance by Daniel A. Reed 2003 ISBN 978-0-262-68142-1 page 182
- Prodan, Radu; Fahringer, Thomas (2007). Grid computing: experiment management, tool integration, and scientific workflows. pp. 1–4. ISBN 978-3-540-69261-4.
- Knight, Will: "IBM creates world's most powerful computer", NewScientist.com news service, June 2007
- N. R. Agida; et al. (2005). "Blue Gene/L Torus Interconnection Network | IBM Journal of Research and Development" (PDF). Torus Interconnection Network. p. 265. Archived from the original (PDF) on 15 August 2011.
- Niu, Yanwei; Hu, Ziang; Barner, Kenneth; Gao, Guang R. (2005). "Performance Modelling and Optimization of Memory Access on Cellular Computer Architecture Cyclops64" (PDF). Network and Parallel Computing. Lecture Notes in Computer Science. 3779. pp. 132–143. doi:10.1007/11577188_18. ISBN 978-3-540-29810-6.
- Analysis and performance results of computing betweenness centrality on IBM Cyclops64 by Guangming Tan, Vugranam C. Sreedhar and Guang R. Gao The Journal of Supercomputing Volume 56, Number 1, 1–24 September 2011
- Mittal et al., "A Survey of Methods for Analyzing and Improving GPU Energy Efficiency", ACM Computing Surveys, 2014.
- Prickett, Timothy (31 May 2010). "Top 500 supers – The Dawning of the GPUs". Theregister.co.uk.
- "A Survey of CPU-GPU Heterogeneous Computing Techniques", ACM Computing Surveys, 2015
- Hans Hacker; Carsten Trinitis; Josef Weidendorfer; Matthias Brehm (2010). "Considering GPGPU for HPC Centers: Is It Worth the Effort?". In Rainer Keller; David Kramer; Jan-Philipp Weiss (eds.). Facing the Multicore-Challenge: Aspects of New Paradigms and Technologies in Parallel Computing. Springer Science & Business Media. pp. 118–121. ISBN 978-3-642-16232-9.
- Damon Poeter (11 October 2011). "Cray's Titan Supercomputer for ORNL Could Be World's Fastest". Pcmag.com.
- Feldman, Michael (11 October 2011). "GPUs Will Morph ORNL's Jaguar into 20-Petaflop Titan". Hpcwire.com.
- Timothy Prickett Morgan (11 October 2011). "Oak Ridge changes Jaguar's spots from CPUs to GPUs". Theregister.co.uk.
- "The NETL SuperComputer". page 2.
- Condon, J.H. and K.Thompson, "Belle Chess Hardware", In Advances in Computer Chess 3 (ed.M.R.B.Clarke), Pergamon Press, 1982.
- Hsu, Feng-hsiung (2002). Behind Deep Blue: Building the Computer that Defeated the World Chess Champion. Princeton University Press. ISBN 978-0-691-09065-8.
- C. Donninger, U. Lorenz. The Chess Monster Hydra. Proc. of 14th International Conference on Field-Programmable Logic and Applications (FPL), 2004, Antwerp – Belgium, LNCS 3203, pp. 927 – 932
- J Makino and M. Taiji, Scientific Simulations with Special Purpose Computers: The GRAPE Systems, Wiley. 1998.
- RIKEN press release, Completion of a one-petaFLOPS computer system for simulation of molecular dynamics
- Electronic Frontier Foundation (1998). Cracking DES – Secrets of Encryption Research, Wiretap Politics & Chip Design. Oreilly & Associates Inc. ISBN 978-1-56592-520-5.
- Lohr, Steve (8 June 2018). "Move Over, China: U.S. Is Again Home to World's Speediest Supercomputer". New York Times. Retrieved 19 July 2018.
- "Green500 List - November 2018". TOP500. Retrieved 19 July 2018.
- Xue-June Yang; Xiang-Ke Liao; et al. (2011). "The TianHe-1A Supercomputer: Its Hardware and Software". Journal of Computer Science and Technology. 26 (3): 344–351. doi:10.1007/s02011-011-1137-8.
- The Supermen: Story of Seymour Cray and the Technical Wizards Behind the Supercomputer by Charles J. Murray 1997, ISBN 0-471-04885-2, pages 133–135
- Parallel Computational Fluid Dyynamics; Recent Advances and Future Directions edited by Rupak Biswas 2010 ISBN 1-60595-022-X page 401
- Supercomputing Research Advances by Yongge Huáng 2008, ISBN 1-60456-186-6, pages 313–314
- Parallel computing for real-time signal processing and control by M. O. Tokhi, Mohammad Alamgir Hossain 2003, ISBN 978-1-85233-599-1, pages 201–202
- Computational science – ICCS 2005: 5th international conference edited by Vaidy S. Sunderam 2005, ISBN 3-540-26043-9, pages 60–67
- "NVIDIA Tesla GPUs Power World's Fastest Supercomputer" (Press release). Nvidia. 29 October 2010.
- Balandin, Alexander A. (October 2009). "Better Computing Through CPU Cooling". Spectrum.ieee.org.
- "The Green 500". Green500.org.
- "Green 500 list ranks supercomputers". iTnews Australia. Archived from the original on 22 October 2008.
- Wu-chun Feng (2003). "Making a Case for Efficient Supercomputing | ACM Queue Magazine, Volume 1 Issue 7, 10 January 2003 doi 10.1145/957717.957772" (PDF). Queue. 1 (7): 54. doi:10.1145/957717.957772. Archived from the original (PDF) on 30 March 2012.
- "IBM uncloaks 20 petaflops BlueGene/Q super". The Register. 22 November 2010. Retrieved 25 November 2010.
- Prickett, Timothy (15 July 2011). "The Register: IBM 'Blue Waters' super node washes ashore in August". Theregister.co.uk. Retrieved 9 June 2012.
- "IBM Hot Water-Cooled Supercomputer Goes Live at ETH Zurich". IBM News room. 2 July 2010. Archived from the original on 10 January 2011. Retrieved 16 March 2020.
- Martin LaMonica (10 May 2010). "CNet 10 May 2010". News.cnet.com. Retrieved 9 June 2012.
- "Government unveils world's fastest computer". CNN. Archived from the original on 10 June 2008.
performing 376 million calculations for every watt of electricity used.
- "IBM Roadrunner Takes the Gold in the Petaflop Race". Archived from the original on 17 December 2008. Retrieved 16 March 2020.
- "Top500 Supercomputing List Reveals Computing Trends".
IBM... BlueGene/Q system .. setting a record in power efficiency with a value of 1,680 MFLOPS/W, more than twice that of the next best system.
- "IBM Research A Clear Winner in Green 500". 18 November 2010.
- "Green 500 list". Green500.org. Archived from the original on 3 July 2011. Retrieved 16 March 2020.
- Saed G. Younis. "Asymptotically Zero Energy Computing Using Split-Level Charge Recovery Logic". 1994. page 14.
- "Hot Topic – the Problem of Cooling Supercomputers" Archived 18 January 2015 at the Wayback Machine.
- Anand Lal Shimpi. "Inside the Titan Supercomputer: 299K AMD x86 Cores and 18.6K NVIDIA GPUs". 2012.
- Curtis Storlie; Joe Sexton; Scott Pakin; Michael Lang; Brian Reich; William Rust. "Modeling and Predicting Power Consumption of High-Performance Computing Jobs". 2014.
- Encyclopedia of Parallel Computing by David Padua 2011 ISBN 0-387-09765-1 pages 426–429
- Knowing machines: essays on technical change by Donald MacKenzie 1998 ISBN 0-262-63188-1 page 149-151
- Euro-Par 2004 Parallel Processing: 10th International Euro-Par Conference 2004, by Marco Danelutto, Marco Vanneschi and Domenico Laforenza, ISBN 3-540-22924-8, page 835
- Euro-Par 2006 Parallel Processing: 12th International Euro-Par Conference, 2006, by Wolfgang E. Nagel, Wolfgang V. Walter and Wolfgang Lehner ISBN 3-540-37783-2 page
- An Evaluation of the Oak Ridge National Laboratory Cray XT3 by Sadaf R. Alam etal International Journal of High Performance Computing Applications February 2008 vol. 22 no. 1 52–80
- Open Job Management Architecture for the Blue Gene/L Supercomputer by Yariv Aridor et al. in Job scheduling strategies for parallel processing by Dror G. Feitelson 2005 ISBN 978-3-540-31024-2 pages 95–101
- "Top500 OS chart". Top500.org. Archived from the original on 5 March 2012. Retrieved 31 October 2010.
- "Wide-angle view of the ALMA correlator". ESO Press Release. Retrieved 13 February 2013.
- Pande lab. "Client Statistics by OS". Folding@home. Stanford University. Retrieved 10 April 2020.
- "BOINC Combined". BOINCstats. BOINC. Archived from the original on 19 September 2010. Retrieved 30 October 2016Note this link will give current statistics, not those on the date last accessed.
- "Internet PrimeNet Server Distributed Computing Technology for the Great Internet Mersenne Prime Search". GIMPS. Retrieved 6 June 2011.
- Kravtsov, Valentin; Carmeli, David; Dubitzky, Werner; Orda, Ariel; Schuster, Assaf; Yoshpa, Benny. "Quasi-opportunistic supercomputing in grids, hot topic paper (2007)". IEEE International Symposium on High Performance Distributed Computing. IEEE. Retrieved 4 August 2011.
- Jamalian, S.; Rajaei, H. (1 March 2015). ASETS: A SDN Empowered Task Scheduling System for HPCaaS on the Cloud. 2015 IEEE International Conference on Cloud Engineering. pp. 329–334. doi:10.1109/IC2E.2015.56. ISBN 978-1-4799-8218-9.
- Jamalian, S.; Rajaei, H. (1 June 2015). Data-Intensive HPC Tasks Scheduling with SDN to Enable HPC-as-a-Service. 2015 IEEE 8th International Conference on Cloud Computing. pp. 596–603. doi:10.1109/CLOUD.2015.85. ISBN 978-1-4673-7287-9.
- Gupta, A.; Milojicic, D. (1 October 2011). Evaluation of HPC Applications on Cloud. 2011 Sixth Open Cirrus Summit. pp. 22–26. CiteSeerX 10.1.1.294.3936. doi:10.1109/OCS.2011.10. ISBN 978-0-7695-4650-6.
- Kim, H.; el-Khamra, Y.; Jha, S.; Parashar, M. (1 December 2009). An Autonomic Approach to Integrated HPC Grid and Cloud Usage. 2009 Fifth IEEE International Conference on E-Science. pp. 366–373. CiteSeerX 10.1.1.455.7000. doi:10.1109/e-Science.2009.58. ISBN 978-1-4244-5340-5.
- Eadline, Douglas. "Moving HPC to the Cloud". Admin Magazine. Admin Magazine. Retrieved 30 March 2019.
- Niccolai, James (11 August 2009). "Penguin Puts High-performance Computing in the Cloud". PCWorld. IDG Consumer & SMB. Retrieved 6 June 2016.
- The Potential Impact of High-End Capability Computing on Four Illustrative Fields of Science and Engineering by Committee on the Potential Impact of High-End Computing on Illustrative Fields of Science and Engineering and National Research Council (28 October 2008) ISBN 0-309-12485-9 page 9
- Xingfu Wu (1999). Performance Evaluation, Prediction and Visualization of Parallel Systems. Springer Science & Business Media. pp. 114–117. ISBN 978-0-7923-8462-5.
- Dongarra, Jack J.; Luszczek, Piotr; Petitet, Antoine (2003), "The LINPACK Benchmark: past, present and future" (PDF), Concurrency and Computation: Practice and Experience, 15 (9): 803–820, doi:10.1002/cpe.728
- "Understanding measures of supercomputer performance and storage system capacity". Indiana University. Retrieved 3 December 2017.
- "Frequently Asked Questions". TOP500.org. Retrieved 3 December 2017.
- Intel brochure – 11/91. "Directory page for Top500 lists. Result for each list since June 1993". Top500.org. Retrieved 31 October 2010.
- "Lenovo Attains Status as Largest Global Provider of TOP500 Supercomputers". Business Wire. 25 June 2018.
- "The Cray-1 Computer System" (PDF). Cray Research, Inc. Retrieved 25 May 2011.
- Joshi, Rajani R. (9 June 1998). "A new heuristic algorithm for probabilistic optimization". Computers & Operations Research. 24 (7): 687–697. doi:10.1016/S0305-0548(96)00056-1.
- "Abstract for SAMSY – Shielding Analysis Modular System". OECD Nuclear Energy Agency, Issy-les-Moulineaux, France. Retrieved 25 May 2011.
- "EFF DES Cracker Source Code". Cosic.esat.kuleuven.be. Retrieved 8 July 2011.
- "Disarmament Diplomacy: – DOE Supercomputing & Test Simulation Programme". Acronym.org.uk. 22 August 2000. Retrieved 8 July 2011.
- "China's Investment in GPU Supercomputing Begins to Pay Off Big Time!". Blogs.nvidia.com. Retrieved 8 July 2011.
- Andrew, Scottie. "The world's fastest supercomputer identified chemicals that could stop coronavirus from spreading, a crucial step toward a treatment". CNN. Retrieved 12 May 2020.
- Kaku, Michio. Physics of the Future (New York: Doubleday, 2011), 65.
- "Faster Supercomputers Aiding Weather Forecasts". News.nationalgeographic.com. 28 October 2010. Retrieved 8 July 2011.
- "IBM Drops 'Blue Waters' Supercomputer Project". International Business Times. 9 August 2011. Retrieved 14 December 2018. – via EBSCO (subscription required)
- "Supercomputers". U.S. Department of Energy. Retrieved 7 March 2017.
- "Supercomputer Simulations Help Advance Electrochemical Reaction Research". ucsdnews.ucsd.edu. Retrieved 12 May 2020.
- "IBM's Summit—The Supercomputer Fighting Coronavirus". MedicalExpo e-Magazine. 16 April 2020. Retrieved 12 May 2020.
- "OSTP Funding Supercomputer Research to Combat COVID-19 – MeriTalk". Retrieved 12 May 2020.
- "EU $1.2 supercomputer project to several 10-100 PetaFLOP computers by 2020 and exaFLOP by 2022 | NextBigFuture.com". NextBigFuture.com. 4 February 2018. Retrieved 21 May 2018.
- Erik, DeBenedictis. "The Path To Extreme Computing" (PDF). Sandia National Laboratories. Retrieved 1 December 2017.
- Cohen, Reuven (28 November 2013). "Global Bitcoin Computing Power Now 256 Times Faster Than Top 500 Supercomputers, Combined!". Forbes. Retrieved 1 December 2017.
- DeBenedictis, Erik P. (2005). "Reversible logic for supercomputing". Proceedings of the 2nd conference on Computing frontiers. pp. 391–402. ISBN 978-1-59593-019-4.
- "IDF: Intel says Moore's Law holds until 2029". Heise Online. 4 April 2008. Archived from the original on 8 December 2013.
- Solem, J. C. (1985). "MECA: A multiprocessor concept specialized to Monte Carlo". Proceedings of the Joint los Alamos National Laboratory – Commissariat à l'Energie Atomique Meeting Held at Cadarache Castle, Provence, France 22–26 April 1985; Monte-Carlo Methods and Applications in Neutronics, Photonics and Statistical Physics, Alcouffe, R.; Dautray, R.; Forster, A.; Forster, G.; Mercier, B.; Eds. (Springer Verlag, Berlin). Lecture Notes in Physics. 240: 184–195. Bibcode:1985LNP...240..184S. doi:10.1007/BFb0049047. ISBN 978-3-540-16070-0.
- Yiannis Cotronis; Anthony Danalis; Dimitris Nikolopoulos; Jack Dongarra (2011). Recent Advances in the Message Passing Interface: 18th European MPI Users' Group Meeting, EuroMPI 2011, Santorini, Greece, September 18-21, 2011. Proceedings. Springer Science & Business Media. ISBN 9783642244483.
- James H. Laros III; Kevin Pedretti; Suzanne M. Kelly; Wei Shu; Kurt Ferreira; John Van Dyke; Courtenay Vaughan (2012). Energy-Efficient High Performance Computing: Measurement and Tuning. Springer Science & Business Media. p. 1. ISBN 9781447144922.
- James H. Laros III; Kevin Pedretti; Suzanne M. Kelly; Wei Shu; Kurt Ferreira; John Van Dyke; Courtenay Vaughan (2012). Energy-Efficient High Performance Computing: Measurement and Tuning. Springer Science & Business Media. p. 2. ISBN 9781447144922.
- James H. Laros III; Kevin Pedretti; Suzanne M. Kelly; Wei Shu; Kurt Ferreira; John Van Dyke; Courtenay Vaughan (2012). Energy-Efficient High Performance Computing: Measurement and Tuning. Springer Science & Business Media. p. 3. ISBN 9781447144922.
- "Green Supercomputer Crunches Big Data in Iceland". intelfreepress.com. 21 May 2015. Archived from the original on 20 May 2015. Retrieved 18 May 2015.
| General | |
|---|---|
| Levels | |
| Multithreading |
|
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |

| Authority control |
|
|---|