Intel QuickPath Interconnect
The Intel QuickPath Interconnect (QPI)[1][2] is a point-to-point processor interconnect developed by Intel which replaced the front-side bus (FSB) in Xeon, Itanium, and certain desktop platforms starting in 2008. It increased the scalability and available bandwidth. Prior to the name's announcement, Intel referred to it as Common System Interface (CSI).[3] Earlier incarnations were known as Yet Another Protocol (YAP) and YAP+.
QPI 1.1 is a significantly revamped version introduced with Sandy Bridge-EP (Romley platform).[4]
QPI was replaced by Intel Ultra Path Interconnect (UPI) in Skylake-SP Xeon processors based on LGA 3647 socket.[5]
Background
Although sometimes called a "bus", QPI is a point-to-point interconnect. It was designed to compete with HyperTransport that had been used by Advanced Micro Devices (AMD) since around 2003.[6][7] Intel developed QPI at its Massachusetts Microprocessor Design Center (MMDC) by members of what had been the Alpha Development Group, which Intel had acquired from Compaq and HP and in turn originally came from Digital Equipment Corporation (DEC).[8] Its development had been reported as early as 2004.[9]
Intel first delivered it for desktop processors in November 2008 on the Intel Core i7-9xx and X58 chipset. It was released in Xeon processors code-named Nehalem in March 2009 and Itanium processors in February 2010 (code named Tukwila).[10]
Implementation
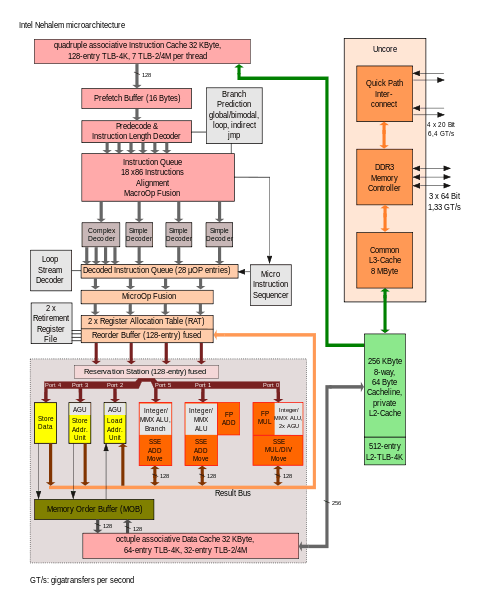
The QPI is an element of a system architecture that Intel calls the QuickPath architecture that implements what Intel calls QuickPath technology.[11] In its simplest form on a single-processor motherboard, a single QPI is used to connect the processor to the IO Hub (e.g., to connect an Intel Core i7 to an X58). In more complex instances of the architecture, separate QPI link pairs connect one or more processors and one or more IO hubs or routing hubs in a network on the motherboard, allowing all of the components to access other components via the network. As with HyperTransport, the QuickPath Architecture assumes that the processors will have integrated memory controllers, and enables a non-uniform memory access (NUMA) architecture.
Each QPI comprises two 20-lane point-to-point data links, one in each direction (full duplex), with a separate clock pair in each direction, for a total of 42 signals. Each signal is a differential pair, so the total number of pins is 84. The 20 data lanes are divided onto four "quadrants" of 5 lanes each. The basic unit of transfer is the 80-bit flit, which is transferred in two clock cycles (four 20 bit transfers, two per clock.) The 80-bit flit has 8 bits for error detection, 8 bits for "link-layer header", and 64 bits for data. QPI bandwidths are advertised by computing the transfer of 64 bits (8 bytes) of data every two clock cycles in each direction.[8]
Although the initial implementations use single four-quadrant links, the QPI specification permits other implementations. Each quadrant can be used independently. On high-reliability servers, a QPI link can operate in a degraded mode. If one or more of the 20+1 signals fails, the interface will operate using 10+1 or even 5+1 remaining signals, even reassigning the clock to a data signal if the clock fails.[8] The initial Nehalem implementation used a full four-quadrant interface to achieve 25.6 GB/s, which provides exactly double the theoretical bandwidth of Intel's 1600 MHz FSB used in the X48 chipset.
Although some high-end Core i7 processors expose QPI, other "mainstream" Nehalem desktop and mobile processors intended for single-socket boards (e.g. LGA 1156 Core i3, Core i5, and other Core i7 processors from the Lynnfield/Clarksfield and successor families) do not expose QPI externally, because these processors are not intended to participate in multi-socket systems. However, QPI is used internally on these chips to communicate with the "uncore", which is part of the chip containing memory controllers, CPU-side PCI Express and GPU, if present; the uncore may or may not be on the same die as the CPU core, for instance it is on a separate die in the Westmere-based Clarkdale/Arrandale.[12][13][14][15]:3 These post-2009 single-socket chips communicate externally via the slower DMI and PCI Express interfaces, because the functions of the traditional northbridge are actually integrated into these processors, starting with Lynnfield, Clarksfield, Clarkdale and Arrandale; thus, there is no need to incur the expense of exposing the (former) front-side bus interface via the processor socket.[16] Although the core–uncore QPI link is not present in desktop and mobile Sandy Bridge processors (as it was on Clarkdale, for example), the internal ring interconnect between on-die cores is also based on the principles behind QPI, at least as far as cache coherency is concerned.[15]:10
Frequency specifications
QPI operates at a clock rate of 2.4 GHz, 2.93 GHz, 3.2 GHz, 3.6 GHz, 4.0 GHz or 4.8 GHz (3.6 GHZ and 4.0 GHz frequencies were introduced with the Sandy Bridge-E/EP platform and 4.8 GHz with the Haswell-E/EP platform). The clock rate for a particular link depends on the capabilities of the components at each end of the link and the signal characteristics of the signal path on the printed circuit board. The non-extreme Core i7 9xx processors are restricted to a 2.4 GHz frequency at stock reference clocks. Bit transfers occur on both the rising and the falling edges of the clock, so the transfer rate is double the clock rate.
Intel describes the data throughput (in GB/s) by counting only the 64-bit data payload in each 80-bit flit. However, Intel then doubles the result because the unidirectional send and receive link pair can be simultaneously active. Thus, Intel describes a 20-lane QPI link pair (send and receive) with a 3.2 GHz clock as having a data rate of 25.6 GB/s. A clock rate of 2.4 GHz yields a data rate of 19.2 GB/s. More generally, by this definition a two-link 20-lane QPI transfers eight bytes per clock cycle, four in each direction.
The rate is computed as follows:
- 3.2 GHz
- × 2 bits/Hz (double data rate)
- × 16(20) (data bits/QPI link width)
- × 2 (unidirectional send and receive operating simultaneously)
- ÷ 8 (bits/byte)
- = 25.6 GB/s
Protocol layers
QPI is specified as a five-layer architecture, with separate physical, link, routing, transport, and protocol layers.[1] In devices intended only for point-to-point QPI use with no forwarding, such as the Core i7-9xx and Xeon DP processors, the transport layer is not present and the routing layer is minimal.
- Physical layer
- The physical layer comprises the actual wiring and the differential transmitters and receivers, plus the lowest-level logic that transmits and receives the physical-layer unit. The physical-layer unit is the 20-bit "phit." The physical layer transmits a 20-bit "phit" using a single clock edge on 20 lanes when all 20 lanes are available, or on 10 or 5 lanes when the QPI is reconfigured due to a failure. Note that in addition to the data signals, a clock signal is forwarded from the transmitter to receiver (which simplifies clock recovery at the expense of additional pins).
- Link layer
- The link layer is responsible for sending and receiving 80-bit flits. Each flit is sent to the physical layer as four 20-bit phits. Each flit contains an 8-bit CRC generated by the link layer transmitter and a 72-bit payload. If the link layer receiver detects a CRC error, the receiver notifies the transmitter via a flit on the return link of the pair and the transmitter resends the flit. The link layer implements flow control using a credit/debit scheme to prevent the receiver's buffer from overflowing. The link layer supports six different classes of message to permit the higher layers to distinguish data flits from non-data messages primarily for maintenance of cache coherence. In complex implementations of the QuickPath architecture, the link layer can be configured to maintain separate flows and flow control for the different classes. It is not clear if this is needed or implemented for single-processor and dual-processor implementations.
- Routing layer
- The routing layer sends a 72-bit unit consisting of an 8-bit header and a 64-bit payload. The header contains the destination and the message type. When the routing layer receives a unit, it examines its routing tables to determine if the unit has reached its destination. If so it is delivered to the next-higher layer. If not, it is sent on the correct outbound QPI. On a device with only one QPI, the routing layer is minimal. For more complex implementations, the routing layer's routing tables are more complex, and are modified dynamically to avoid failed QPI links.
- Transport layer
- The transport layer is not needed and is not present in devices that are intended for only point-to-point connections. This includes the Core i7. The transport layer sends and receives data across the QPI network from its peers on other devices that may not be directly connected (i.e., the data may have been routed through an intervening device.) the transport layer verifies that the data is complete, and if not, it requests retransmission from its peer.
- Protocol layer
- The protocol layer sends and receives packets on behalf of the device. A typical packet is a memory cache row. The protocol layer also participates in cache coherency maintenance by sending and receiving cache coherency messages.
See also
- Elastic interface bus
- Front side bus
- HyperTransport
- List of device bandwidths
- PCI Express
- RapidIO
References
- "An Introduction to the Intel QuickPath Interconnect" (PDF). Intel Corporation. January 30, 2009. Retrieved June 14, 2011.
- DailyTech report Archived 2013-10-17 at the Wayback Machine, retrieved August 21, 2007
- Eva Glass (May 16, 2007). "Intel CSI name revealed: Slow, slow, quick quick slow". The Inquirer. Retrieved September 13, 2013.
- David Kanter (2011-07-20). "Intel's Quick Path Evolved". Realworldtech.com. Retrieved 2014-01-21.
- SoftPedia: Intel Plans to Replace Xeon with Its New Skylake-Based “Purley” Super Platform
- Gabriel Torres (August 25, 2008). "Everything You Need to Know About The QuickPath Interconnect (QPI)". Hardware Secrets. Retrieved January 23, 2017.
- Charlie Demerjian (December 13, 2005). "Intel Intel gets knickers in a twist over Tanglewood". The Inquirer. Retrieved September 13, 2013.
- David Kanter (August 28, 2007). "The Common System Interface: Intel's Future Interconnect". Real World Tech. Retrieved August 14, 2014.
- Eva Glass (December 12, 2004). "Intel's Whitefield takes four core IA-32 shape". The Inquirer. Retrieved September 13, 2013.
- David Kanter (May 5, 2006). "Intel's Tukwila Confirmed to be Quad Core". Real World Tech. Archived from the original on May 10, 2012. Retrieved September 13, 2013.
- "Intel Demonstrates Industry's First 32nm Chip and Next-Generation Nehalem Microprocessor Architecture". Archived from the original on 2008-01-02. Retrieved 2007-12-31.
- Chris Angelini (2009-09-07). "QPI, Integrated Memory, PCI Express, And LGA 1156 - Intel Core i5 And Core i7: Intel's Mainstream Magnum Opus". Tomshardware.com. Retrieved 2014-01-21.
- Published on 25th January 2010 by Richard Swinburne (2010-01-25). "Feature - Intel GMA HD Graphics Performance". bit-tech.net. Retrieved 2014-01-21.
- "Intel Clarkdale 32nm CPU-and-GPU chip benchmarked (again) - CPU - Feature". HEXUS.net. 2009-09-25. Retrieved 2014-01-21.
- Oded Lempel (2013-07-28). "2nd Generation Intel Core Processor Family: Intel Core i7, i5 and i3" (PDF). hotchips.org. Retrieved 2014-01-21.
- Lily Looi, Stephan Jourdan, Transitioning the Intel® Next Generation Microarchitectures (Nehalem and Westmere) into the Mainstream, Hot Chips 21, August 24, 2009
External links
- An Introduction to the Intel QuickPath Interconnect
- Intel QuickPath Interconnect Overview (PDF)
- What you need to know about Intel’s Nehalem CPU, Ars Technica, April 9, 2008, by Jon Stokes
- First Look at Nehalem Microarchitecture: QPI Bus, November 2, 2008, by Ilya Gavrichenkov
- The Common System Interface: Intel’s Future Interconnect, August 28, 2007, by David Kanter
| General | |
|---|---|
| Standards |
|
| Storage | |
| Peripheral | |
| Audio | |
| Portable | |
| Embedded | |
Interfaces are listed by their speed in the (roughly) ascending order, so the interface at the end of each section should be the fastest. | |