TeraScale (microarchitecture)
TeraScale is the codename for a family of graphics processing unit microarchitectures developed by ATI Technologies/AMD and their second microarchitecture implementing the unified shader model following Xenos. TeraScale replaced the old fixed-pipeline microarchitectures and competed directly with Nvidia's first unified shader microarchitecture named Tesla.[1][2]
TeraScale was used in HD 2000 manufactured in 80 nm and 65 nm, HD 3000 manufactured in 65 nm and 55 nm, HD 4000 manufactured in 55 nm and 40 nm, HD 5000 and HD 6000 manufactured in 40 nm. TeraScale was also used in the AMD Accelerated Processing Units code-named "Brazos", "Llano", "Trinity" and "Richland". TeraScale is even found in some of the succeeding graphics cards brands.
TeraScale is a VLIW SIMD architecture, while Tesla is a RISC SIMD architecture, similar to TeraScale's successor Graphics Core Next. TeraScale implements HyperZ.[3]
An LLVM code generator (i.e. a compiler back-end) is available for TeraScale,[4] but it seems to be missing in LLVM's matrix.[5] E.g. Mesa 3D makes use of it.
TeraScale 1
| Release date | May 2007 |
|---|---|
| History | |
| Predecessor | Not publicly known |
| Successor | TeraScale 2 |
At SIGGRAPH 08 in December 2008 AMD employee Mike Houston described some of the TeraScale microarchitecture.[6]
At FOSDEM09 Matthias Hopf from AMDs technology partner SUSE Linux presented a slide regarding the programming of open-source driver for the R600.[7]
Unified shaders
Previous GPU architectures implemented fixed-pipelines, i.e. there were distinct shader processors for each type of shader. TeraScale leverages many flexible shader processors which can be scheduled to process a variety of shader types, thereby significantly increasing GPU throughput (dependent on application instruction mix as noted below). The R600 core processes vertex, geometry, and pixel shaders as outlined by the Direct3D 10.0 specification for Shader Model 4.0 in addition to full OpenGL 3.0 support.[8]
The new unified shader functionality is based upon a very long instruction word (VLIW) architecture in which the core executes operations in parallel.[9]
A shader cluster is organized into 5 stream processing units. Each stream processing unit can retire a finished single precision floating point MAD (or ADD or MUL) instruction per clock, dot product (DP, and special cased by combining ALUs), and integer ADD.[10] The 5th unit is more complex and can additionally handle special transcendental functions such as sine and cosine.[10] Each shader cluster can execute 6 instructions per clock cycle (peak), consisting of 5 shading instructions plus 1 branch.[10]
Notably, the VLIW architecture brings with it some classic challenges inherent to VLIW designs, namely that of maintaining optimal instruction flow.[9] Additionally, the chip cannot co-issue instructions when one is dependent on the results of the other. Performance of the GPU is highly dependent on the mixture of instructions being used by the application and how well the real-time compiler in the driver can organize said instructions.[10]
R600 core includes 64 shader clusters, while RV610 and RV630 cores have 8 and 24 shader clusters respectively.
Hardware tessellation
TeraScale includes multiple units capable of carrying out tessellation. Those are similar to the programmable units of the Xenos GPU which is used in the Xbox 360.
Tessellation was officially specified in the major API's only starting with DirectX 11 and OpenGL 4, while TeraScale 1 and 2 based GPU's (HD 2000, 3000 and 4000 series) are only conformant to Direct3D 10 and OpenGL 3.3. The TeraScale 3 based GPU's (starting with the Radeon HD 5000 series) were the first to conform with both Direct3D 11 and OpenGL 4.0, supporting the tesselation feature as de facto.
The TeraScale tessellator units allow the developers to take a simple polygon mesh and subdivide it using a curved surface evaluation function. There are different tessellation forms, such as Bézier surfaces with N-patches, B-splines and NURBS, and also some subdivision techniques of the surface, which usually includes displacement map some kind of a texture.[11] Essentially, this allows a simple, low-polygon model to be increased dramatically in polygon density in real-time with very small impact on the performance. Scott Wasson of Tech Report noted during an AMD demo that the resulting model was so dense with millions of polygons that it appeared to be solid.[9]
The TeraScale tessellator is reminiscent of ATI TruForm, the brand name of an early hardware tessellation unit used initially in the Radeon 8500.[12]
While this tessellation hardware was not part of the OpenGL 3.3 or Direct3D 10.0 requirements, and competitors such as the GeForce 8 series lacked similar hardware, Microsoft has added the tessellation feature as part of their DirectX 10.1 future plans.[13]
ATI TruForm received little attention from software developers. A few games (such as Madden NFL 2004, Serious Sam, Unreal Tournament 2003 and 2004, and unofficially Morrowind), had the support for the ATI's tesselation technology included. Such a slow adaptation has to do with the fact that it was not a feature shared with NVIDIA GPUs, since those had implemented a competing tessellation solution using Quintic-RT patches which had achieved even less support from the major game developers.[14] Since the Xbox 360's GPU is based on the ATI's architecture, Microsoft saw the hardware-accelerated surface tessellation as a major GPU feature. A couple of years later the tesselation feature became mandatory with the release of the DirectX 11 in 2009.[11][13]
GCN geometric processor is the AMD's (which acquired the ATI's GPU business) most current solution for carrying out the tessellation using the GPU.
Ultra threaded dispatch processor
Although the R600 is a significant departure from previous designs, it still shares many features with its predecessor, the Radeon R520.[9] The Ultra-Threaded Dispatch Processor is a major architectural component of the R600 core, just as it was with the Radeon X1000 GPUs. This processor manages a large number of in-flight threads of three distinct types (vertex, geometry, and pixel shaders) and switches amongst them as needed.[9] With a large number of threads being managed simultaneously it is possible to reorganize thread order to optimally utilize the shaders. In other words, the dispatch processor evaluates what goes in the other parts of the R600 and attempts to keep processing efficiency as high as possible. There are lower levels of management as well; each SIMD array of 80 stream processors has its own sequencer and arbiter. The arbiter decides which thread to process next, while the sequencer attempts to reorder instructions for best possible performance within each thread.[9]
Texturing and anti-aliasing
Texturing and final output aboard the R600 core is similar but also distinct from R580. R600 is equipped with 4 texture units that are decoupled (independent) from the shader core, like in the R520 and R580 GPUs.[9] The render output units (ROPs) of Radeon HD 2000 series now performs the task of Multisample anti-aliasing (MSAA) with programmable sample grids and maximum of 8 sample points, instead of using pixel shaders as in Radeon X1000 series. Also new is the capability to filter FP16 textures, popular with HDR lighting, at full-speed. ROP can also perform trilinear and anisotropic filtering on all texture formats. On R600, this totals 16 pixels per clock for FP16 textures, while higher precision FP32 textures filter at half-speed (8 pixels per clock).[9]
Anti-aliasing capabilities are more robust on R600 than on the R520 series. In addition to the ability to perform 8× MSAA, up from 6× MSAA on the R300 through R580, R600 has a new custom filter anti-aliasing (CFAA) mode. CFAA refers to an implementation of non-box filters that look at pixels around the particular pixel being processed in order to calculate the final color and anti-alias the image.[10] CFAA is performed by shader, instead of in the ROPs. This brings greatly enhanced programmability because the filters can be customized, but may also bring potential performance issues because of the use of shader resources. As of launch of R600, CFAA utilizes wide and narrow tent filters. With these, samples from outside the pixel being processed are weighted linearly based upon their distance from the centroid of that pixel, with the linear function adjusted based on the wide or narrow filter chosen.[10]
Memory controllers
Memory controllers are connected via internal bi-directional ring bus wrapped around the processor. In Radeon HD 2900, it is a 1,024-bit bi-directional ring bus (512-bit read and 512-bit write), with 8 64-bit memory channels for a total bus width of 512-bits on the 2900 XT.;[9] in Radeon HD 3800, it is a 512-bit ring bus; in Radeon HD 2600 and HD 3600, it is a 256-bit ring bus; In Radeon HD 2400 and HD 3400, there is no ring bus.
Half-generation update
The series saw a half-generation update with die shrink (55 nm) variants: RV670, RV635 and RV620. All variants support PCI Express 2.0, DirectX 10.1 with Shader Model 4.1 features, dedicated ATI Unified Video Decoder (UVD) for all models[15] and PowerPlay technology for desktop video cards.[16]
Except the Radeon HD 3800 series, all variants supported 2 integrated DisplayPort outputs, supporting 24- and 30-bit displays for resolutions up to 2,560×1,600. Each output included 1, 2, or 4 lanes per output, with data rate up to 2.7 Gbit/s per lane.
ATI claimed that the support of DirectX 10.1 can bring improved performance and processing efficiency with reduced rounding error (0.5 ULP compared with average error 1.0 ULP as tolerable error), better image details and quality, global illumination (a technique used in animated films, and more improvements to consumer gaming systems therefore giving more realistic gaming experience.[17] )
Video cards
- Radeon HD 2000 series
- Radeon HD 3000 Series
- Radeon HD 4000 series
(see list of chips in those pages)
TeraScale 2 "Evergreen"-family
| Release date | September 2009 |
|---|---|
| History | |
| Predecessor | TeraScale 1 |
| Successor | TeraScale 3 |
TeraScale 2 (VLIW5) was introduced with the Radeon HD 5000 Series GPUs baptized "Evergreen".
At HPG10 Mark Fowler presented the "Evergreen" and stated that e.g. 5870 (Cypress), 5770 (Juniper) and 5670 (Redwood) support max resolution of the 6 times 2560×1600 pixels, while the 5470 (Cedar) supports 4 times 2560×1600 pixels, important for AMD Eyefinity multi-monitor support.[18]
With the release of Cypress, the Terascale graphics engine architecture has been upgraded with twice the number of stream cores, texture units and ROP units compared to the RV770. The architecture of stream cores is largely unchanged, but adds support for DirectX 11/DirectCompute 11 capabilities with new instructions.[19] Also similar to RV770, four texture units are tied to 16 stream cores (each have five processing elements, making a total of 80 processing elements). This combination of is referred to as a SIMD core.
Unlike the predecessor Radeon R700, as DirectX 11 mandates full developer control over interpolation, dedicated interpolators were removed, relying instead on the SIMD cores. The stream cores can handle the higher rounding precision fused multiply–add (FMA) instruction in both single and double precision which increases precision over multiply–add (MAD) and is compliant to IEEE 754-2008 standard.[20] The instruction sum of absolute differences (SAD) has been natively added to the processors. This instruction can be used to greatly improve the performance of some processes, such as video encoding and transcoding on the 3D engine. Each SIMD core is equipped with 32 KiB local data share and 8 kiB of L1 cache,[19] while all SIMD cores share 64 KiB global data share.
Memory controller
Each memory controller ties to two quad ROPs, one per 64-bit channel, and dedicated 512 KiB L2 cache.[19] Redwood has one quad ROP per 256-bit channel.
Power saving
AMD PowerPlay is supported, see there.
Chips
- Evergreen chips:
- Cedar RV810
- Redwood RV830
- Juniper RV840
- Cypress RV870
- Hemlock R800
- Turks RV930
- Barts RV940
- Caïcos RV910
- APU that include a TeraScale 2 IGP:
- Ontario
- Zacate
- Llano
TeraScale 3 "Northern Islands"-family
| Release date | October 2010 |
|---|---|
| History | |
| Predecessor | TeraScale 2 |
| Successor | Graphics Core Next 1 |
TeraScale 3 (VLIW4) replaces the previous 5-way VLIW designs with a 4-way VLIW design. The new design also incorporates an additional tessellation unit to improve Direct3D 11 performance.
TeraScale 3 is implemented in the Radeon HD 6900-branded graphics cards and also in the Trinity and Richland APUs. The chips are baptized as the "Northern Islands" family.
Power saving
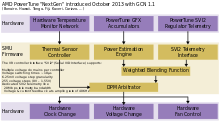
AMD PowerTune, dynamic frequency scaling for GPUs, was introduced with Radeon HD 6900 on December 15, 2010 and has been prone to further development ever since, like a couple of reviews by AnandTech document.[21][22][23][24]
Chips
- Northern Islands chips:
- Cayman RV970
- Antilles R900
- Trinity and Richland include a TeraScale 3 IGP
Successor
At HPG11 in August 2011 AMD employees Michael Mantor (Senior Fellow Architect) and Mike Houston (Fellow Architect) presented Graphics Core Next, the microarchitecture succeeding TeraScale.[25]
References
- Kevin Parrish (March 9, 2011). "The TeraScale 3 architecture of the HD 6990". Tom's Hardware. Retrieved 2015-04-08.
- "Anatomy of AMD's TeraScale Graphics Engine" (PDF). Retrieved 2015-04-08.
- "Feature matrix of the free and open-source "Radeon" graphics device driver". Retrieved 2014-07-09.
- "[LLVMdev] RFC: R600, a new backend for AMD GPUs".
- Target-specific Implementation Notes: Target Feature Matrix // The LLVM Target-Independent Code Generator, LLVM site.
- "Anatomy of AMD's TeraScale microarchitecture" (pdf). 2008-12-12.
- http://www.vis.uni-stuttgart.de/~hopf/pub/Fosdem_2009_r600demo_Slides.pdf
- AMD OpenGL 3.0 driver release on Jan 28, 2009
- Wasson, Scott. AMD Radeon HD 2900 XT graphics processor: R600 revealed, Tech Report, May 14, 2007
- Beyond3D review: AMD R600 Architecture and GPU Analysis, retrieved June 2, 2007.
- ExtremeTech review
- Witheiler, Matthew (2001-05-29). "ATI TruForm – Powering the next generation Radeon". AnandTech. Retrieved 2016-01-30.
- The Future of DirectX Archived 2013-06-16 at the Wayback Machine presentation, slide 24-29
- nVidia GeForce3 SDK WhitePaper
- "RV670 Cards & Specs Revealed". VR-Zone. August 22, 2007.
- (in Spanish) MadboxPC coverage Archived 2012-10-18 at the Wayback Machine, retrieved November 10, 2007
- ATI DirectX 10.1 whitepaper Archived 2010-03-07 at the Wayback Machine, retrieved December 7, 2007
- "Presenting Radeon HD 5000" (PDF).
- DirectX 11 in the Open: ATI Radeon HD 5870 Review Archived 2009-09-27 at the Wayback Machine
- Report: AMD Radeon HD 5870 and 5850
- "Redefining TDP With PowerTune". AnandTech. 2010-12-15. Retrieved 2015-04-30.
- "Introducing PowerTune Technology With Boost". AnandTech. 2012-06-22. Retrieved 2015-04-30.
- "The New PowerTune: Adding Further States". AnandTech. 2013-03-22. Retrieved 2015-04-30.
- "PowerTune: Improved Flexibility & Fan Speed Throttling". AnandTech. 2014-10-23. Retrieved 2015-04-30.
- "AMD "Graphic Core Next": Low Power High Performance Graphics & Parallel Computer" (PDF). 2011-08-05. Retrieved 2014-07-06.