Graphics Core Next
Graphics Core Next (GCN[1]) is the codename for both a series of microarchitectures as well as for an instruction set. GCN was developed by AMD for their GPUs as the successor to TeraScale microarchitecture/instruction set. The first product featuring GCN was launched on January 9, 2012.[2]
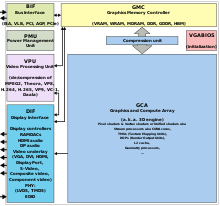
GCN is a RISC SIMD (or rather SIMT) microarchitecture contrasting the VLIW SIMD architecture of TeraScale. GCN requires considerably more transistors than TeraScale, but offers advantages for GPGPU computation. It makes the compiler simpler and should also lead to better utilization.
GCN graphics chips are fabricated with CMOS at 28 nm, and with FinFET at 14 nm (by Samsung Electronics and GlobalFoundries) and 7 nm (by TSMC), available on selected models in the Radeon HD 7000, HD 8000, 200, 300, 400, 500 and Vega series of AMD Radeon graphics cards, including the separately released Radeon VII. GCN is also used in the graphics portion of AMD Accelerated Processing Units (APU), such as in the PlayStation 4 and Xbox One APUs.
Instruction set
The GCN instruction set is owned by AMD (that also owns the X86-64 instruction set). The GCN instruction set has been developed specifically for GPUs (and GPGPU) and, for example, has no micro-operation for division.
Documentation is available for:
- the Graphics Core Next 1 instruction set
- the Graphics Core Next 2 instruction set
- the Graphics Core Next 3 instruction set
- the Graphics Core Next 4: Documentation for the GCN 4 instruction set is the same as for the 3rd generation.[3]
- the Graphics Core Next 5 instruction set (also known as Vega)
- the RDNA instruction set (AMD RDNA Architecture)
An LLVM code generator (a compiler back-end) is available for the GCN instruction set.[4] It is used by Mesa 3D.
The GNU Compiler Collection (GCC) supports GCN 3 (Fiji, Carrizo) and GCN 5 (Vega) since 2019 (GCC 9)[5] for single-threaded, stand-alone programs and with GCC 10 also offloading via OpenMP and OpenACC.[6]
MIAOW is an open-source RTL implementation of the AMD Southern Islands GPGPU instruction set (aka Graphics Core Next).
In November 2015, AMD announced the "Boltzmann Initiative". The AMD Boltzmann Initiative shall enable the porting of CUDA-based applications to a common C++ programming model.[7]
At the "Super Computing 15" AMD showed their Heterogeneous Compute Compiler (HCC), a headless Linux driver and HSA runtime infrastructure for cluster-class, High Performance Computing (HPC) and the Heterogeneous-compute Interface for Portability (HIP) tool for porting CUDA-based applications to a common C++ programming model.
Microarchitectures
As of July 2017, the family of microarchitectures implementing the identically called instruction set "Graphics Core Next" has seen five iterations. The differences in the instruction set are rather minimal and do not differentiate too much from one another. An exception is the fifth generation GCN architecture, which heavily modified the stream processors to improve performance and support the simultaneous processing of two lower precision numbers in place of a single higher precision number.[8]
Command processing

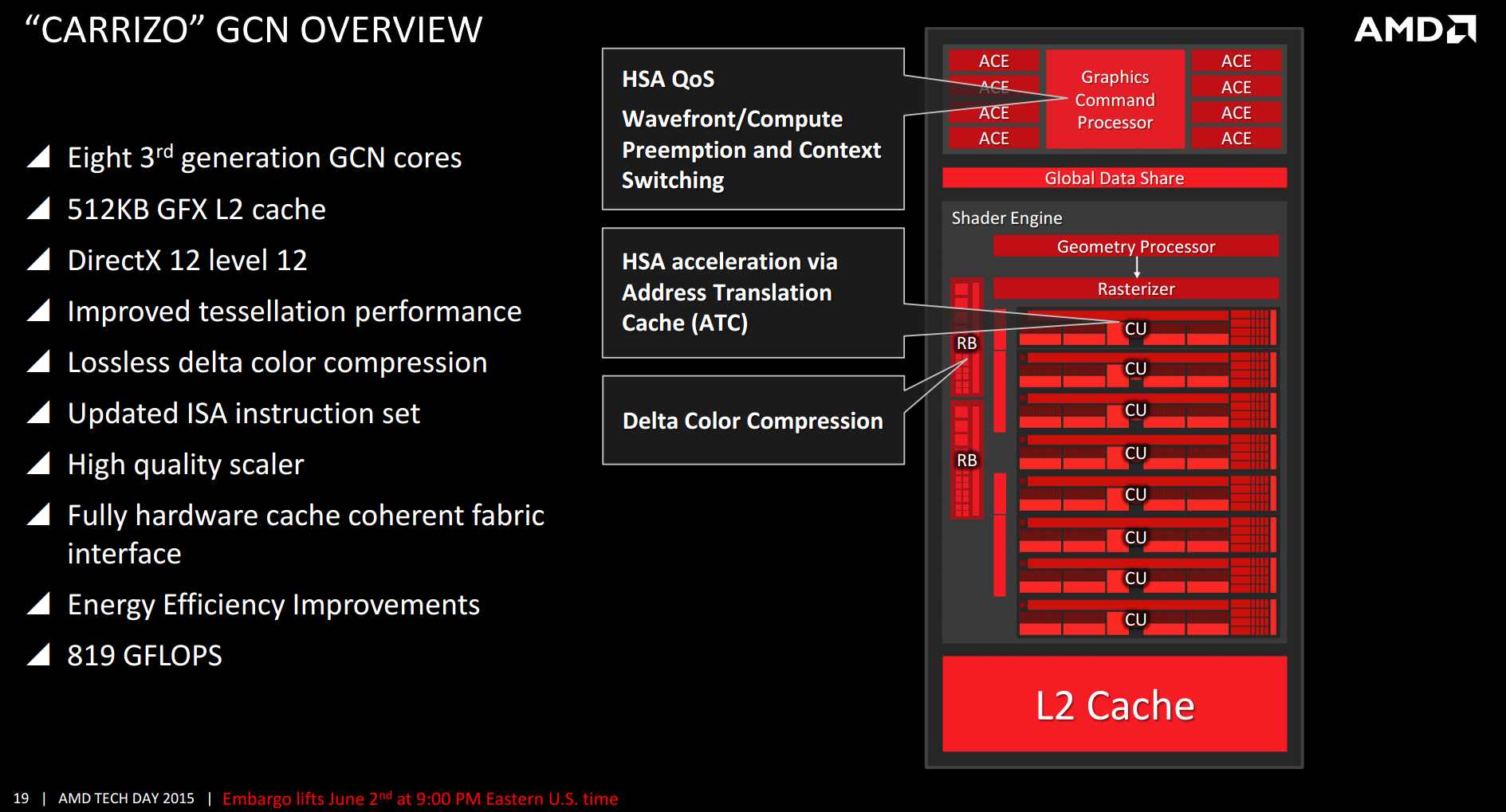
Graphics Command Processor
The "Graphics Command Processor" (GCP) is a functional unit of the GCN microarchitecture. Among other tasks, it is responsible for Asynchronous Shaders. The short video AMD Asynchronous Shaders visualizes the differences between "multi thread", "preemption" and "Asynchronous Shaders[9]".
Asynchronous Compute Engine
The Asynchronous Compute Engine (ACE) is a distinct functional block serving computing purposes. Its purpose is similar to that of the Graphics Command Processor.
Scheduler
Since the third iteration of GCN, the hardware contains two schedulers: One to schedule wavefronts during shader execution (CU Scheduler, see below) and a new one to schedule execution of draw and compute queues. The latter helps performance by executing compute operations when the CUs are underutilized because of graphics commands limited by fixed function pipeline speed or bandwidth limited. This functionality is known as Async Compute.
For a given shader, the GPU drivers also need to select a good instruction order, in order to minimize latency. This is done on cpu, and is sometimes referred as "Scheduling".
Geometric processor

The geometry processor contains the Geometry Assembler, the Tesselator and the Vertex Assembler.
The GCN Tesselator of the Geometry processor is capable of doing tessellation in hardware as defined by Direct3D 11 and OpenGL 4.5 (see AMD January 21, 2017).[10]
The GCN Tesselator is AMD's most current SIP block, earlier units were ATI TruForm and hardware tessellation in TeraScale.
Compute units
One compute unit combines 64 shader processors with 4 TMUs.[11][12] The compute unit is separate from, but feed into, the render output units (ROPs).[12] Each Compute Unit consists of a CU Scheduler, a Branch & Message Unit, 4 SIMD Vector Units (each 16-lane wide), 4 64KiB VGPR files, 1 scalar unit, a 4 KiB GPR file, a local data share of 64 KiB, 4 Texture Filter Units, 16 Texture Fetch Load/Store Units and a 16 KiB L1 Cache. Four Compute units are wired to share an Instruction Cache 16 KiB in size and a scalar data cache 32KiB in size. These are backed by the L2 cache. A SIMD-VU operates on 16 elements at a time (per cycle), while a SU can operate on one a time (one/cycle). In addition the SU handles some other operations like branching.[13]
Every SIMD-VU has some private memory where it stores its registers. There are two types of registers: scalar registers (s0, s1, etc.), which hold 4 bytes number each, and vector registers (v0, v1, etc.), which represent a set of 64 4 bytes numbers each. When you operate on the vector registers, every operation is done in parallel on the 64 numbers. Every time you do some work with them, you actually work with 64 inputs. For example, you work on 64 different pixels at a time (for each of them the inputs are slightly different, and thus you get slightly different color at the end).
Every SIMD-VU has room for 512 scalar registers and 256 vector registers.
CU scheduler
The CU scheduler is the hardware functional block choosing for the SIMD-VU which wavefronts to execute. It picks one SIMD-VU per cycle for scheduling. This is not to be confused with other schedulers, in hardware or software.
- Wavefront
- A 'shader' is a small program written in GLSL which performs graphics processing, and a 'kernel' is a small program written in OpenCL and doing GPGPU processing. These processes don't need that many registers, they need to load data from system or graphics memory. This operation comes with significant latency. AMD and Nvidia chose similar approaches to hide this unavoidable latency: the grouping of multiple threads. AMD calls such a group a wavefront, Nvidia calls it a warp. A group of threads is the most basic unit of scheduling of GPUs implementing this approach to hide latency, is minimum size of the data processed in SIMD fashion, the smallest executable unit of code, the way to processes a single instruction over all of the threads in it at the same time.
In all GCN-GPUs, a "wavefront" consists of 64 threads, and in all Nvidia GPUs a "warp" consists of 32 threads.
AMD's solution is to attribute multiple wavefronts to each SIMD-VU. The hardware distributes the registers to the different wavefronts, and when one wavefront is waiting on some result, which lies in memory, the CU Scheduler decides to make the SIMD-VU work on another wavefront. Wavefronts are attributed per SIMD-VU. SIMD-VUs do not exchange wavefronts. At max 10 wavefronts can be attributed per SIMD-VU (thus 40 per CU).
AMD CodeXL shows tables with the relationship between number of SGPRs and VGPRs to the number of wavefronts, but basically for SGPRS it is min(104, 512/numwavefronts) and VGPRS 256/numwavefronts.
Note that in conjunction with the SSE instructions this concept of most basic level of parallelism is often called a "vector width". The vector width is characterized by the total number of bits in it.
SIMD Vector Unit
Each SIMD Vector Unit has:
- a 16-lane integer and floating point vector Arithmetic Logic Unit (ALU)
- 64 KiB Vector General Purpose Register (VGPR) file
- A 48-bit Program Counter
- Instruction buffer for 10 wavefronts
- A wavefront is a group of 64 threads: the size of one logical VGPR
- A 64-thread wavefront issues to a 16-lane SIMD Unit over four cycles
Each SIMD-VU has 10 wavefront instruction buffer, and it takes 4 cycles to execute one wavefront.
Audio and video acceleration blocks
Many implementations of GCN are typically accompanied by several of AMD's other ASIC blocks. Including but not limited to the Unified Video Decoder, Video Coding Engine, and AMD TrueAudio.
Video Coding Engine
TrueAudio
Unified virtual memory
In a preview in 2011, AnandTech wrote about the unified virtual memory, supported by Graphics Core Next.[14]
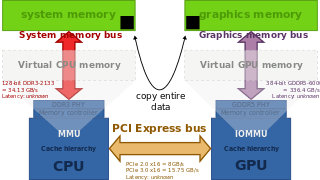 Classical desktop computer architecture with a distinct graphics card over PCI Express. CPU and GPU have their distinct physical memory, with different address spaces. The entire data needs to be copied over the PCIe bus. Note: the diagram shows bandwidths, but not the memory latency.
Classical desktop computer architecture with a distinct graphics card over PCI Express. CPU and GPU have their distinct physical memory, with different address spaces. The entire data needs to be copied over the PCIe bus. Note: the diagram shows bandwidths, but not the memory latency.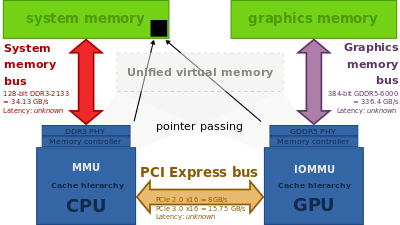
 Integrated graphics-solutions (and AMD APUs with TeraScale graphics) suffer under partitioned main memory: a part of the system memory is allocated to the GPU exclusively. Zero-copy is not possible, data has to be copied (over the system memory bus) from one partition to the other.
Integrated graphics-solutions (and AMD APUs with TeraScale graphics) suffer under partitioned main memory: a part of the system memory is allocated to the GPU exclusively. Zero-copy is not possible, data has to be copied (over the system memory bus) from one partition to the other.
Heterogeneous System Architecture (HSA)
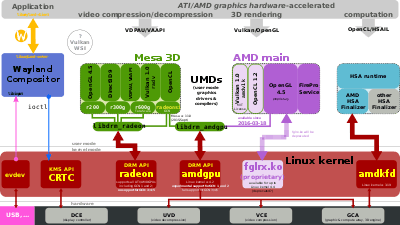
Some of the specific HSA features implemented in the hardware need support from the operating system's kernel (its subsystems) and/or from specific device drivers. For example, in July 2014 AMD published a set of 83 patches to be merged into Linux kernel mainline 3.17 for supporting their Graphics Core Next-based Radeon graphics cards. The special driver titled "HSA kernel driver" resides in the directory /drivers/gpu/hsa while the DRM-graphics device drivers reside in /drivers/gpu/drm[17] and augments the already existent DRM driver for Radeon cards.[18] This very first implementation focuses on a single "Kaveri" APU and works alongside the existing Radeon kernel graphics driver (kgd).
Lossless Delta Color Compression
Hardware schedulers
They are used to perform scheduling[19] and offload the assignment of compute queues to the ACEs from the driver to hardware by buffering these queues until there is at least one empty queue in at least one ACE, causing the HWS to immediately assign buffered queues to the ACEs until all queues are full or there are no more queues to safely assign.[20] Part of the scheduling work performed includes prioritized queues which allow critical tasks to run at a higher priority than other tasks without requiring the lower priority tasks to be preempted to run the high priority task, therefore allowing the tasks to run concurrently with the high priority tasks scheduled to hog the GPU as much as possible while letting other tasks use the resources that the high priority tasks are not using.[19] These are essentially Asynchronous Compute Engines that lack dispatch controllers.[19] They were first introduced in the fourth generation GCN microarchitecture,[19] but were present in the third generation GCN microarchitecture for internal testing purposes.[21] A driver update has enabled the hardware schedulers in third generation GCN parts for production use.[19]
Primitive Discard Accelerator
This unit discards degenerate triangles before they enter the vertex shader and triangles that do not cover any fragments before they enter the fragment shader.[22] This unit was introduced with the fourth generation GCN microarchitecture.[22]
Generations
Graphics Core Next 1
| Release date | January 2012 |
|---|---|
| History | |
| Predecessor | TeraScale 3 |
| Successor | Graphics Core Next 2 |
- support for 64-bit addressing (x86-64 address space) with unified address space for CPU and GPU[14]
- support for PCI-E 3.0[23]
- GPU sends interrupt requests to CPU on various events (such as page faults)
- support for Partially Resident Textures,[24] which enable virtual memory support through DirectX and OpenGL extensions
- AMD PowerTune support, which dynamically adjusts performance to stay within a specific TDP[25]
- support for Mantle (API)
There are Asynchronous Compute Engines controlling computation and dispatching.[13][26]
ZeroCore Power
ZeroCore Power is a long idle power saving technology, shutting off functional units of the GPU when not in use.[27] AMD ZeroCore Power technology supplements AMD PowerTune.
Chips
discrete GPUs (Southern Islands family):
- Oland
- Cape Verde
- Pitcairn
- Tahiti
Graphics Core Next 2
| Release date | September 2013 |
|---|---|
| History | |
| Predecessor | Graphics Core Next 1 |
| Successor | Graphics Core Next 3 |
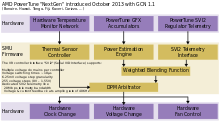
GCN 2nd generation was introduced with Radeon HD 7790 and is also found in Radeon HD 8770, R7 260/260X, R9 290/290X, R9 295X2, R7 360, R9 390/390X, as well as Steamroller-based Desktop Kaveri APUs and Mobile Kaveri APUs and in the Puma-based "Beema" and "Mullins" APUs. It has multiple advantages over the original GCN, including FreeSync support, AMD TrueAudio and a revised version of AMD PowerTune technology.
GCN 2nd generation introduced an entity called "Shader Engine" (SE). A Shader Engine comprises one geometry processor, up to 44 CUs (Hawaii chip), rasterizers, ROPs, and L1 cache. Not part of a Shader Engine is the Graphics Command Processor, the 8 ACEs, the L2 cache and memory controllers as well as the audio and video accelerators, the display controllers, the 2 DMA controllers and the PCIe interface.
The A10-7850K "Kaveri" contains 8 CUs (compute units) and 8 Asynchronous Compute Engines for independent scheduling and work item dispatching.[28]
At AMD Developer Summit (APU) in November 2013 Michael Mantor presented the Radeon R9 290X.[29]
Chips
discrete GPUs (Sea Islands family):
- Bonaire
- Hawaii
integrated into APUs:
- Temash
- Kabini
- Liverpool (i.e. the APU found in the PlayStation 4)
- Durango (i.e. the APU found in the Xbox One and Xbox One S)
- Kaveri
- Godavari
- Mullins
- Beema
- Carrizo-L
Graphics Core Next 3
| Release date | June 2015 |
|---|---|
| History | |
| Predecessor | Graphics Core Next 2 |
| Successor | Graphics Core Next 4 |
GCN 3rd generation[30] was introduced in 2014 with the Radeon R9 285 and R9 M295X, which have the "Tonga" GPU. It features improved tessellation performance, lossless delta color compression in order to reduce memory bandwidth usage, an updated and more efficient instruction set, a new high quality scaler for video, and a new multimedia engine (video encoder/decoder). Delta color compression is supported in Mesa.[31] However, its double precision performance is worse compared to previous generation.[32]
Chips
discrete GPUs:
- Tonga (Volcanic Islands family), comes with UVD 5.0 (Unified Video Decoder)
- Fiji (Pirate Islands family), comes with UVD 6.0 and High Bandwidth Memory (HBM 1)
integrated into APUs:
Graphics Core Next 4
| Release date | June 2016 |
|---|---|
| History | |
| Predecessor | Graphics Core Next 3 |
| Successor | Graphics Core Next 5 |
GPUs of the Arctic Islands-family were introduced in Q2 of 2016 with the AMD Radeon 400 series. The 3D-engine (i.e. GCA (Graphics and Compute array) or GFX) is identical to that found in the Tonga-chips.[34] But Polaris feature a newer Display Controller engine, UVD version 6.3, etc.
All Polaris-based chips other than the Polaris 30 are produced on the 14 nm FinFET process, developed by Samsung Electronics and licensed to GlobalFoundries.[35] The slightly newer refreshed Polaris 30 is built on the 12 nm LP FinFET process node, developed by Samsung and GlobalFoundries. The fourth generation GCN instruction set architecture is compatible with the third generation. It is an optimization for 14 nm FinFET process enabling higher GPU clock speeds than with the 3rd GCN generation.[36] Architectural improvements include new hardware schedulers, a new primitive discard accelerator, a new display controller, and an updated UVD that can decode HEVC at 4K resolutions at 60 frames per second with 10 bits per color channel.
Chips
discrete GPUs:[37]
- Polaris 10 (also codenamed Ellesmere) found on "Radeon RX 470"- and "Radeon RX 480"-branded graphics cards
- Polaris 11 (also codenamed Baffin) found on "Radeon RX 460"-branded graphics cards (also Radeon RX 560D)
- Polaris 12 (also codenamed Lexa) found on "Radeon RX 550" and "Radeon RX 540"-branded graphics cards
- Polaris 20, which is a refreshed (14 nm LPP Samsung/GloFo FinFET process) Polaris 10 with higher clocks, used for "Radeon RX 570" and "Radeon RX 580"-branded graphics cards[38]
- Polaris 21, which is a refreshed (14 nm LPP Samsung/GloFo FinFET process) Polaris 11, used for "Radeon RX 560"-branded graphics cards
- Polaris 22, found on "Radeon RX Vega M GH" and "Radeon RX Vega M GL"-branded graphics cards
- Polaris 30, which is a refreshed (12 nm LP GloFo FinFET process) Polaris 20 with higher clocks, used for "Radeon RX 590"-branded graphics cards[39]
Precision Performance
FP64 performance of all GCN 4th generation GPUs is 1/16 of FP32 performance.
Graphics Core Next 5
| Release date | June 2017 |
|---|---|
| History | |
| Predecessor | Graphics Core Next 4 |
| Successor | RDNA 1 |
AMD began releasing details of their next generation of GCN Architecture, termed the 'Next-Generation Compute Unit', in January 2017.[36][40][41] The new design was expected to increase instructions per clock, higher clock speeds, support for HBM2, a larger memory address space. The discrete graphics chipsets also include "HBCC (High Bandwidth Cache Controller)", but not when integrated into APUs.[42] Additionally, the new chips were expected to include improvements in the Rasterisation and Render output units. The stream processors are heavily modified from the previous generations to support packed math Rapid Pack Math technology for 8-bit, 16-bit, and 32-bit numbers. With this there is a significant performance advantage when lower precision is acceptable (for example: processing two half-precision numbers at the same rate as a single single precision number).
Nvidia introduced tile-based rasterization and binning with Maxwell,[43] and this was a big reason for Maxwell's efficiency increase. In January, AnandTech assumed that Vega would finally catch up with Nvidia regarding energy efficiency optimizations due to the new "DSBR (Draw Stream Binning Rasterizer)" to be introduced with Vega.[44]
It also added support for a new shader stage – Primitive Shaders.[45][46] Primitive shaders provide more flexible geometry processing and replace the vertex and geometry shaders in a rendering pipeline. As of December 2018, the Primitive shaders can't be used because required API changes are yet to be done.[47]
Vega 10 and Vega 12 use the 14 nm FinFET process, developed by Samsung Electronics and licensed to GlobalFoundries. Vega 20 uses the 7 nm FinFET process developed by TSMC.
Chips
discrete GPUs:
- Vega 10 (14 nm Samsung/GloFo FinFET process) (also codenamed Greenland[48]) found on "Radeon RX Vega 64", "Radeon RX Vega 56", "Radeon Vega Frontier Edition", "Radeon Pro V340", and Radeon Pro WX 8200 graphics cards[49]
- Vega 12 (14 nm Samsung/GloFo FinFET process) found on "Radeon Pro Vega 20" and "Radeon Pro Vega 16"-branded mobile graphics cards[50]
- Vega 20 (7 nm TSMC FinFET process) found on "Radeon Instinct MI50" and "Radeon Instinct MI60"-branded accelerator cards,[51] "Radeon Pro VegaII", and "Radeon VII"-branded graphics cards.[52]
integrated into APUs:
- Raven Ridge[53] came with VCN 1 which supersedes VCE and UVD and allows full fixed-function VP9 decode.
Precision Performance
Double-precision floating-point (FP64) performance of all GCN 5th generation GPUs, except for Vega 20, is 1/16 of FP32 performance. For Vega 20 this is 1/2 of FP32 performance.[54] All GCN 5th generation GPUs support half-precision floating-point (FP16) calculations which is double of FP32 performance.
External links
References
- AMD Developer Central (January 31, 2014). "GS-4106 The AMD GCN Architecture - A Crash Course, by Layla Mah". Slideshare.net.
- "AMD Launches World's Fastest Single-GPU Graphics Card – the AMD Radeon HD 7970" (Press release). AMD. December 22, 2011. Archived from the original on January 20, 2015. Retrieved January 20, 2015.
- "AMD community forums". Community.amd.com.
- "LLVM back-end amdgpu". Llvm.org.
- "GCC 9 Release Series Changes, New Features, and Fixes". Retrieved 13 November 2019.
- "AMD GCN Offloading Support". Retrieved 13 November 2019.
- "AMD Boltzmann Initiative – Heterogeneous-compute Interface for Portability (HIP)". November 16, 2015. Archived from the original on January 26, 2016. Retrieved December 8, 2019.
- Smith, Ryan (January 5, 2017). "The AMD Vega GPU Architecture Preview". Anandtech.com. Retrieved July 11, 2017.
- Smith, Ryan. "AMD Dives Deep On Asynchronous Shading". Anandtech.com.
- "The Khronos Group". Khronos.org. October 26, 2017.
- Compute Cores Whitepaper (PDF). AMD. 2014. p. 5.
- Smith, Ryan (December 21, 2011). "AMD's Graphics Core Next Preview". Anandtech.com. Retrieved April 18, 2017.
- Mantor, Michael; Houston, Mike (June 15, 2011). "AMD Graphics Core Next" (pdf). AMD. p. 40. Retrieved July 15, 2014.
Asynchronous Compute Engine (ACE)
- "Not Just A New Architecture, But New Features Too". AnandTech. December 21, 2011. Retrieved July 11, 2014.
- "Kaveri microarchitecture". SemiAccurate. January 15, 2014.
- Airlie, Dave (November 26, 2014). "Merge AMDKFD". freedesktop.org. Retrieved January 21, 2015.
- "/drivers/gpu/drm". Kernel.org.
- "[PATCH 00/83] AMD HSA kernel driver". LKML. July 10, 2014. Retrieved July 11, 2014.
- Angelini, Chris (June 29, 2016). "AMD Radeon RX 480 8GB Review". Tom's Hardware. p. 1. Retrieved August 11, 2016.
- "Dissecting the Polaris Architecture" (PDF). 2016. Archived from the original (PDF) on September 20, 2016. Retrieved August 12, 2016.
- Shrout, Ryan (June 29, 2016). "The AMD Radeon RX 480 Review - The Polaris Promise". PC Perspective. p. 2. Archived from the original on October 10, 2016. Retrieved August 12, 2016.
- Smith, Ryan (June 29, 2016). "The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark". AnandTech. p. 3. Retrieved August 11, 2016.
- "AMD Radeon HD 7000 Series to be PCI-Express 3.0 Compliant". TechPowerUp. Retrieved July 21, 2011.
- "AMD Details Next Gen. GPU Architecture". Retrieved August 3, 2011.
- Tony Chen, Jason Greaves, "AMD's Graphics Core Next (GCN) Architecture" (PDF), AMD, retrieved August 13, 2016CS1 maint: uses authors parameter (link)
- "AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute". AnandTech. December 21, 2011. Retrieved July 15, 2014.
AMD's new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing.
- "Managing Idle Power: Introducing ZeroCore Power". AnandTech.com. December 22, 2011. Retrieved April 29, 2015.
- "AMD's Kaveri A10-7850K tested". AnandTech. January 14, 2014. Retrieved July 7, 2014.
- "AMD Radeon R9-290X". November 21, 2013.
- "Carrizo Overview" (PNG). Images.anandtech.com. Retrieved 20 July 2018.
- "Add DCC Support". Freedesktop.org. October 11, 2015.
- Smith, Ryan (September 10, 2014). "AMD Radeon R9 285 Review". Anandtech.com. Retrieved March 13, 2017.
- Cutress, Ian (June 1, 2016). "AMD Announces 7th Generation APU". Anandtech.com. Retrieved June 1, 2016.
- "Radeon Feature Matrix: GCA".
- "Radeon Technologies Group - January 2016 - AMD Polaris Architecture". Guru3d.com.
- Smith, Ryan (January 5, 2017). "The AMD Vega Architecture Teaser: Higher IPC, Tiling, & More, coming in H1'2017". Anandtech.com. Retrieved January 10, 2017.
- WhyCry (March 24, 2016). "AMD confirms Polaris 10 is Ellesmere and Polaris 11 is Baffin". VideoCardz. Retrieved April 8, 2016.
- "Fast vollständige Hardware-Daten zu AMDs Radeon RX 500 Serie geleakt". www.3dcenter.org.
- Oh, Nate (November 15, 2018). "The AMD Radeon RX 590 Review, feat. XFX & PowerColor: Polaris Returns (Again)". anandtech.com. Retrieved November 24, 2018.
- Kampman, Jeff (January 5, 2017). "The curtain comes up on AMD's Vega architecture". TechReport.com. Retrieved January 10, 2017.
- Shrout, Ryan (January 5, 2017). "AMD Vega GPU Architecture Preview: Redesigned Memory Architecture". PC Perspective. Retrieved January 10, 2017.
- Kampman, Jeff (October 26, 2017). "AMD's Ryzen 7 2700U and Ryzen 5 2500U APUs revealed". Techreport.com. Retrieved October 26, 2017.
- Raevenlord (March 1, 2017). "On NVIDIA's Tile-Based Rendering". techPowerUp.
- "Vega Teaser: Draw Stream Binning Rasterizer". Anandtech.com.
- "Radeon RX Vega Revealed: AMD promises 4K gaming performance for $499 - Trusted Reviews". Trustedreviews.com. July 31, 2017.
- "The curtain comes up on AMD's Vega architecture". Techreport.com.
- Kampman, Jeff (January 23, 2018). "Radeon RX Vega primitive shaders will need API support". Techreport.com. Retrieved December 29, 2018.
- "ROCm-OpenCL-Runtime/libUtils.cpp at master · RadeonOpenCompute/ROCm-OpenCL-Runtime". github.com. May 3, 2017. Retrieved November 10, 2018.
- "The AMD Radeon RX Vega 64 & RX Vega 56 Review: Vega Burning Bright". Anandtech.com. August 14, 2017. Retrieved November 16, 2017.
- "AMD's Vega Mobile Lives: Vega Pro 20 & 16 in Updated MacBook Pros In November". Anandtech.com. October 30, 2018. Retrieved November 10, 2018.
- "AMD Announces Radeon Instinct MI60 & MI50 Accelerators: Powered By 7nm Vega". Anandtech.com. November 6, 2018. Retrieved November 10, 2018.
- "AMD Unveils World's First 7nm Gaming GPU – Delivering Exceptional Performance and Incredible Experiences for Gamers, Creators and Enthusiasts" (Press release). Las Vegas, Nevada: AMD. January 9, 2019. Retrieved January 12, 2019.
- Ferreira, Bruno (May 16, 2017). "Ryzen Mobile APUs are coming to a laptop near you". Tech Report. Retrieved May 16, 2017.
- "AMD Unveils World's First 7nm Datacenter GPUs -- Powering the Next Era of Artificial Intelligence, Cloud Computing and High Performance Computing (HPC) | AMD". AMD.com (Press release). November 6, 2018. Retrieved November 10, 2018.
{kind=link}