The Search for a Search - Measuring the Information Cost of Higher Level Search
"The Search for a Search - Measuring the Information Cost of Higher Level Search" is an article by William Dembski and Robert Marks which appeared in the Journal of Advanced Computational Intelligence and Intelligent Informatics [2](abstract, full text) The article is a follow-up to Conservation of Information in Search: Measuring the Cost of Success which appeared in Ieee Transactions On Systems, Man, and Cybernetics. [3]
| The divine comedy Creationism |
| Running gags |
| Jokes aside |
| Blooper reel |
|
v - t - e |
“”Intellectual Standards. Are we holding ourselves to high intellectual standards? Are we in the least self-critical about our work? Are we sober or immodest about our work? Do we demand precision and rigor from our each other? Do we examine each other's work with intense critical scrutiny and speak our minds freely in assessing it? Or do we try to keep all our interactions civil, gentlemanly, and diplomatic (perhaps so as not to give the appearance of dissension in our ranks)? Does the mood of our movement alternate between the smug and the indignant -- smug when we hold the upper hand, indignant when we are criticized? Do we react to adverse criticism like first-time novelists who are dismayed to discover that their masterpiece has been trashed by the critics? Or do we take adverse criticism as an occasion for tightening and improving our work? |
| —William Dembski, 2002[1] |
The gist of the article is that Dembski and Marks attempt to demonstrate some difficulties with information searches, building on the existing "no free lunch" theorem, which states (colloquially) that no process for optimizing a search is "better" than any other when applied to all searches. Dembski extends this idea further, and though he does not touch on intelligent design in this paper, he has elsewhere made it clear that he interprets NFL as supporting intelligent design,[4] an idea that has been strongly criticized by no less than David Wolpert, one of the authors of the original NFL paper.[5]
| Original Text | Annotations |
|---|---|
|
Abstract: Needle-in-the-haystack problems look for small targets in large spaces. In such cases, blind search stands no hope of success. Conservation of information dictates any search technique will work, on average, as well as blind search. Success requires an assisted search. But whence the assistance required for a search to be successful? To pose the question this way suggests that successful searches do not emerge spontaneously but need themselves to be discovered via a search. The question then naturally arises whether such a higher-level “search for a search” is any easier than the original search. We prove two results: (1) The Horizontal No Free Lunch Theorem, which shows that average relative performance of searches never exceeds unassisted or blind searches, and (2) The Vertical No Free Lunch Theorem, which shows that the difficulty of searching for a successful search increases exponentially with respect to the minimum allowable active information being sought. |
We will occupy ourselves with the Horizontal No Free Lunch Theorem and show how its assumptions - and its proof - are seriously flawed. |
Introduction
| Original Text | Annotations |
|---|---|
|
[...] Endogenous and active information together allow for a precise characterization of the conservation of information. The average active information, or active entropy, of an unassisted search is zero when no assumption is made concerning the search target. If any assumption is made concerning the target, the active entropy becomes negative. This is the Horizontal NFLT presented in Section 3.2. It states that an arbitrary search space structure will, on average, result in a worse search than assuming nothing and simply performing an unassisted search. [...] |
This is a very surprising claim in the light of the conventional No Free Lunch Theorems (NFL): given the usual assumptions of the NFL, we would expect any search to be as good (or as bad) as random search. And an unassisted search seems to be a random search...
To make our ideas clearer, we will introduce a simple example: a Shell Game, using one, two or even three peas. In the language of Dembski and Marks, our search space is |
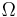 . Judging from the examples they used in their earlier papers, Dembski and Marks do not mind that the player knows the size of the target - so we can assume that exactly one pea is used in the game. (A random number of peas would provide a new puzzle: how would it to be determined? We could put under each shell a pea with a probability p, and repeat this process if no pea was placed - as the authors don't allow for the empty target. Or we could first decide how many peas to place, and then hide them at random, resulting in another distribution... Though it seems to be far-fetched, we have to come back to this little problem later on.)
. Judging from the examples they used in their earlier papers, Dembski and Marks do not mind that the player knows the size of the target - so we can assume that exactly one pea is used in the game. (A random number of peas would provide a new puzzle: how would it to be determined? We could put under each shell a pea with a probability p, and repeat this process if no pea was placed - as the authors don't allow for the empty target. Or we could first decide how many peas to place, and then hide them at random, resulting in another distribution... Though it seems to be far-fetched, we have to come back to this little problem later on.)Information in Search
| Original Text | Annotations |
|---|---|
|
All but the most trivial searches require information about the search environment (e.g., smooth landscapes) or target location (e.g., fitness measures) if they are to be successful. Conservation of information theorems[6][7][8] show that one search algorithm will, on average, perform as well as any other and thus that no search algorithm will, on average, outperform an unassisted, or blind, search. But clearly, many of the searches that arise in practice do outperform blind unassisted search. How, then, do such searches arise and where do they obtain the information that enables them to be successful? |
These are good questions, but unfortunately, Dembski and Marks will not answer them. But let us at first formulate our search problem in the language of the No Free Lunch Theorems: these are generally about minimizing a (somewhat) unknown function f over a space 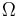 , that is, you know that a function f belongs to a set of functions , that is, you know that a function f belongs to a set of functions 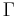 and you are allowed to evaluate the function at any element of . As any evaluation is costly in the world of computer science, you try to keep the number of evaluations low. A search is a special form of minimization: imagine the set consisting from three functions and you are allowed to evaluate the function at any element of . As any evaluation is costly in the world of computer science, you try to keep the number of evaluations low. A search is a special form of minimization: imagine the set consisting from three functions 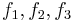 from from 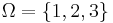 into the set into the set 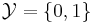 , such that , such that
This is the set of functions matching our problem of looking for a single pea under three shells! Now look at
This set isn't c.u.p.: Take the permutation
Clearly not a member of
Of course, this set of functions is very artificial, but all the interesting minimization problems we find in nature are of the non-c.u.p. kind. |

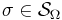 and each function
and each function 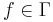 we find that
we find that 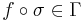 , too. This is the kind of sets for which the No Free Lunch theorems hold: you cannot find a strategy beating random search without repetition when playing this game: if you are allowed to guess once, your chance will be 1/3, if you allowed to guess twice, your chance will be 2/3, and if you are allowed to guess three times (this may happen in the world of mathematics!), your chance is 1 to find the pea - under any strategy you can imagine!
, too. This is the kind of sets for which the No Free Lunch theorems hold: you cannot find a strategy beating random search without repetition when playing this game: if you are allowed to guess once, your chance will be 1/3, if you allowed to guess twice, your chance will be 2/3, and if you are allowed to guess three times (this may happen in the world of mathematics!), your chance is 1 to find the pea - under any strategy you can imagine! , consisting form the three functions
, consisting form the three functions 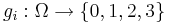

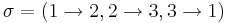 and look at
and look at 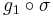 :
:
Blind and Assisted Queries and Searches
| Original Text | Annotations |
|---|---|
|
Let |
Interestingly, at the NFL theorems, such a uniformity of probability is assumed - though it is certainly possible to formulate the theorems for a family of distributions - as long as this family is c.u.p. again. But keep in mind that assuming that the events have equal probability doesn't make it true. What does this mean for our shell game? If we assume that the pea is hidden under each shell with probability 1/3, it is okay for us to pick a shell at random - or stick with picking a certain shell. But if the man who hides the pea has a preference for one shell, a random guess will still result in a success-rate of 1/3 - while other strategies may have other rates of success: greater than 1/3 if it shares the proclivity of the master of the game, less than 1/3 if it doesn't! |
|
Consider Q queries (samples) from
The requirement of sampling without replacement requires
where
From Eqs. (2) and (3), we have
|
These innocuous notations are the main reason of all the trouble to come. Let us first have a look how a deterministic minimization algorithm is described in the language of the No Free Lunch theorems: at the n-th step, you have evaluated the function f (n-1) times, thus you know a sequence  . Considering this knowledge, you will chose a new element . Considering this knowledge, you will chose a new element 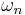 where you will evaluate the function. Formally, a strategy for solving a minimization problem is a funcion where you will evaluate the function. Formally, a strategy for solving a minimization problem is a funcion 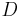 which will map sequence of length 0 up to which will map sequence of length 0 up to 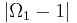 to elements of to elements of 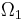 (with (with 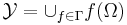 ): ):
With If our functions Such search strategies are completely determined by the elements - and not the values of the functions. And so, the clumsy writing of
These deterministic 0-1 strategy of length Q can be easily randomized by choosing one of these strategies according to a probability measure on the set of the strategies. Such a measure will be called randomized 0-1 strategy of length Q - or just 0-1 strategy of length Q. So, what Dembski and Marks see as augmented search-space, we regard as the set of deterministic search strategies... |
|
There appears, at first flush, to be knowledge about the search space |
Nothing wrong about this! |
|
Keeping track of Q subscripts and exhaustively contracted perturbation search spaces is distracting. As such, let |
Well, we will keep track with the subscripts and the different spaces! For instance, guessing twice in our shell game results in |
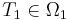 denote a target in a search space,
denote a target in a search space, 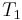 to that of
to that of 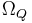 , consists of
all sequences of length Q chosen from
, consists of
all sequences of length Q chosen from 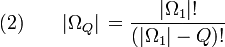
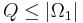 . If nothing is known about the location or
the target, then, from Bernoulli’s PrOIR, any element of
. If nothing is known about the location or
the target, then, from Bernoulli’s PrOIR, any element of 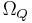 is as likely to contain the target as any other element.
is as likely to contain the target as any other element.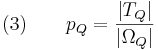
 consists of all the elements containing the original target,
consists of all the elements containing the original target,  . When, for example,
. When, for example,  ) and there is no knowledge about the search space structure or target location, then
) and there is no knowledge about the search space structure or target location, then 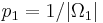 and
and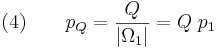
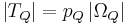
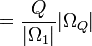

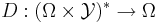
 , we get a new sequence
, we get a new sequence  and can go on.
and can go on.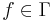 only take to values, 0 if the element is the minimum, i.e., it is found, and 1 otherwise, we can drop the second element in each pair as it doesn't have any influence on our considerations: if the element is the minimum, fine, we are done and carry on the same way we would have done without finding it - we have already a winning sequence.
only take to values, 0 if the element is the minimum, i.e., it is found, and 1 otherwise, we can drop the second element in each pair as it doesn't have any influence on our considerations: if the element is the minimum, fine, we are done and carry on the same way we would have done without finding it - we have already a winning sequence. 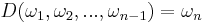 can be abbreviated to
can be abbreviated to 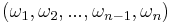 . We will call this a 0-1 strategy and summarize:
. We will call this a 0-1 strategy and summarize: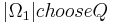 such strategies.
such strategies.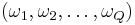 is successful in finding a target
is successful in finding a target  if
if 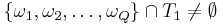
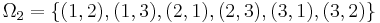 . A search is now guessing an element of
. A search is now guessing an element of 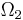 , and a search is successful if our chosen element lies in the target - a subset
, and a search is successful if our chosen element lies in the target - a subset 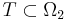 . But be careful: the target the pea is under shell 1 is represented now by
. But be careful: the target the pea is under shell 1 is represented now by  .
.Active Information and No Free Lunch
| Original Text | Annotations |
|---|---|
|
Define an assisted query as any choice from
|
Here, |
|
Let q denote the probability of success of an assisted search. We assume that we can always do at least as well as uniform random sampling. The question is, how much better can we do? Given a small target T in |
So, Dembski's and Marks's uniform random sampling takes an element of |
|
An instructive way to characterize the effectiveness of assisted search in relation to blind search is with the likelihood ratio |
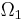 that provides more information about the search environment or candidate solutions than a blind search. Gauging the effectiveness of assisted search in relation to blind search is our next task. Random sampling with respect to the uniform probability U sets a baseline for the effectiveness of blind search. For a finite search space with
that provides more information about the search environment or candidate solutions than a blind search. Gauging the effectiveness of assisted search in relation to blind search is our next task. Random sampling with respect to the uniform probability U sets a baseline for the effectiveness of blind search. For a finite search space with 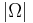 elements, the probability of locating the target T has uniform probability given by Eq. (3) without the subscripts:
elements, the probability of locating the target T has uniform probability given by Eq. (3) without the subscripts: 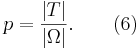
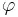 characterizing blind and assisted search respectively, assisted search will be more effective than blind search when p < q, as effective if p = q, and less effective if p > q. In other words, an assisted search can be more likely to locate T than blind search, equally likely, or less likely. If less likely, the assisted search is counterproductive, actually doing worse than blind search. For instance, we might imagine an Easter egg hunt where one is told “warmer” if one is moving away from an egg and “colder” if one is moving toward it. If one acts on this guidance, one will be less likely to find the egg than if one simply did a blind search. Because the assisted search is in this instance misleading, it actually undermines the success of the search.
characterizing blind and assisted search respectively, assisted search will be more effective than blind search when p < q, as effective if p = q, and less effective if p > q. In other words, an assisted search can be more likely to locate T than blind search, equally likely, or less likely. If less likely, the assisted search is counterproductive, actually doing worse than blind search. For instance, we might imagine an Easter egg hunt where one is told “warmer” if one is moving away from an egg and “colder” if one is moving toward it. If one acts on this guidance, one will be less likely to find the egg than if one simply did a blind search. Because the assisted search is in this instance misleading, it actually undermines the success of the search. is chosen with probability 1/6. How could a
is chosen with probability 1/6. How could a 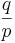 . This ratio achieves a maximum of
. This ratio achieves a maximum of 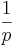 when q = 1, in which case the assisted search is guaranteed to succeed. The assisted search is better at locating T than blind search provided the ratio is bigger than 1, equivalent to blind search when it is equal to 1, and worse than blind search when it is less than 1. Finally, this ratio achieves a minimum value of 0 when q = 0, indicating that the assisted search is guaranteed to fail.
when q = 1, in which case the assisted search is guaranteed to succeed. The assisted search is better at locating T than blind search provided the ratio is bigger than 1, equivalent to blind search when it is equal to 1, and worse than blind search when it is less than 1. Finally, this ratio achieves a minimum value of 0 when q = 0, indicating that the assisted search is guaranteed to fail.Active Information
| Original Text | Annotations |
|---|---|
|
Let U denote a uniform distribution on
|
Of course, we can define such a quantity. But does it make sense? Does it even exist? We will see... |
|
Active information measures the effectiveness of assisted search in relation to blind search using a conventional information measure. It[12] characterizes the amount of information[13] that |
As the NFL theorems are stating that a search which outperforms blind search only exists if there is a non-c.u.p. set of functions, |
|
The maximum value that active information can attain
is |
So, here we find to examples for assisted searches, the perfect search and its evil twin, the search which is doomed to fail. So, what do the (nonuniform) measures on |
|
[...] |
|
|
Active information can also be measured with respect to other reference points. We therefore define the active information more generally as:
for |
Again, this can be defined: but what is it meaning? |
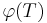 denote the probability over the target set
denote the probability over the target set 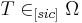 . Define the active information of the assisted search as
. Define the active information of the assisted search as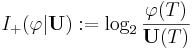
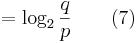
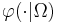 will just be the uniform probability...)
will just be the uniform probability...)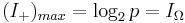 indicating an assisted search
guaranteed to succeed (i.e., a perfect search)
indicating an assisted search
guaranteed to succeed (i.e., a perfect search)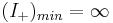 , indicating an assisted search guaranteed to fail.
, indicating an assisted search guaranteed to fail.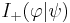
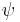 arbitrary probability measures over the compact metric space
arbitrary probability measures over the compact metric space 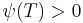 .
.3.2. Horizontal No Free Lunch
| Original Text | Annotations | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
The following No Free Lunch theorem (NFLT) underscores the parity of average search performance. |
|||||||||||||
|
Theorem 1: Horizontal No Free Lunch. Let
Then |
This is as true as it is meaningless:
Generally, for a search of two or more guesses, there is no meaningful way to get the partition
This strategy works well if the pea is under the first shell - or the second one (target |
||||||||||||
|
In our opinion, the problem arises from the elegant - but unfortunately invalid - identification of the search space and the space of the searches: For our set of deterministic 0-1 strategies, each measure introduces a randomized strategy. For each such strategy, we can calculate the probability to find a target in the original space. Let's go back to our two-guesses shell game. The deterministic 0-1 strategies are:
Dembski's and Marks's uniform distribution U leads to choosing one of these searches with probability 1/6. If the pea is hidden without any preference for any of the shells, this strategy gets a success rate of 2/3. As does any other randomized 0-1 strategy - because it is the success rate of the deterministic strategies! And that is no surprise at all, as the formulation of the searches introduced a set of c.u.p. functions. If there is a preference for - for instance - the first shell, the picture changes: Suddenly, there are preferable strategies: sticking with |
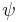 be arbitrary probability measures and let
be arbitrary probability measures and let 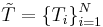 be an exhaustive partition of
be an exhaustive partition of 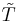 as
as
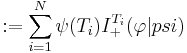

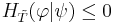 with equality if and only if
with equality if and only if  for
for 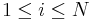 .
.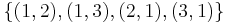 . Let our strategy be
. Let our strategy be 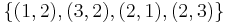 ), and fails for the third one (target
), and fails for the third one (target  ). But these three targets aren't looked at by the theorem: they don't form a partition of
). But these three targets aren't looked at by the theorem: they don't form a partition of  .
. 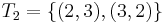 are the elements left. But what does it mean to search successfully for
are the elements left. But what does it mean to search successfully for 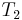 : it means that we have to find two peas - one under the second and another under the third shell!
On
: it means that we have to find two peas - one under the second and another under the third shell!
On 
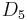
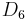
See also
References
- Becoming a Disciplined Science: Prospects, Pitfalls, and a Reality Check for ID, William Dembski, Keynote address delivered at RAPID Conference (Research and Progress in Intelligent Design), Biola University, La Mirada, California, 25 October 2002
- Journal of Advanced Computational Intelligence and Intelligent Informatics, Vol.14, No.5, 2010, pp. 475-486
- Ieee Transactions On Systems, Man, and Cybernetics—Part A: Systems And Humans, Vol. 39, No. 5, September 2009.
- Dembski, W. A. (2002) No Free Lunch, Rowman & Littlefield
- Wolpert, D. (2003) "William Dembski's treatment of the No Free Lunch theorems is written in jello".
- C. Schaffer, “A conservation law for generalization performance,” Proc. Eleventh Int. Conf. on Machine Learning, H. Willian and W. Cohen, San Francisco: Morgan Kaufmann, pp. 295-265, 1994.
- T. M. English, “Some information theoretic results on evolutionary optimization,” Proc. of the 1999 Congress on Evolutionary Computation, 1999, CEC 99, Vol.1, pp. 6-9, July 1999.
- D. Wolpert and W. G. Macready, “No free lunch theorems for optimization,” IEEE Trans. Evolutionary Computation, Vol.1, No.1, pp. 67-82, 1997.
- W. A. Dembski and R. J. Marks II, “Bernoulli’s Principle of Insufficient Reason and Conservation of Information in Computer Search,” Proceedings of the 2009 IEEE Int. Conf. on Systems, Man, and Cybernetics, San Antonio, TX, USA, pp. 2647-2652, October 2009.
- J. Bernoulli, “Ars Conjectandi (The Art of Conjecturing),” Tractatus De Seriebus Infinitis, 1713.
- A. Papoulis, “Probability, Random Variables, and Stochastic Processes,” 3rd ed., New York: McGraw-Hill, 1991.
- W. A. Dembski and R. J. Marks II, “Conservation of Information in Search: Measuring the Cost of Success,” IEEE Trans. on Systems, Man and Cybernetics A, Systems and Humans, Vol.39, No.5, pp. 1051-1061, September 2009.
- T. M. Cover and J. A. Thomas, “Elements of Information Theory,” 2nd Edition, Wiley-Interscience, 2006.