Efficient Per Query Information Extraction from a Hamming Oracle
Efficient Per Query Information Extraction from a Hamming Oracle is a magnificent paper illustrating the art of obfuscation disguised as "science."[1]
| The divine comedy Creationism |
| Running gags |
| Jokes aside |
| Blooper reel |
|
v - t - e |
On March 9, 2010, William Dembski announced in his blog Uncommon Descent a "New Peer Reviewed ID Paper - Deconstructing the Dawkins WEASEL."[2] Amusingly, Richard Dawkins isn't mentioned in the paper at all, or in its references (though those are at least not the usual sloppy copy-and-paste job we have seen in their earlier papers). No, the only hint that this has to do something with Richard Dawkins or evolution is the use of the phrase:
METHINKS*IT*IS*LIKE*A*WEASEL.
William Dembski — and his coauthors Winston Ewert, George Montañez, and Robert J. Marks II — seem to think that they are criticizing Darwinian evolution by using their secret catch phrase.
But the main sentiment when reading it is a sense of déjà vu - or even déjà fait.
If you hate math and technical crap, just skip to this section.
Press release
The inimitable Casey Luskin gets it all wrong when he arrives late to the party on Apr 8, 2010 with a press release[3] for the Discovery Institute:
“”This paper covers all of the known claims of operation of the WEASEL algorithm and shows that in all cases, active information is used. Dawkins’ algorithm can best be understood as using a “Hamming Oracle” as follows: “When a sequence of letters is presented to a Hamming oracle, the oracle responds with the Hamming distance equal to the number of letter mismatches in the sequence.” The authors find that this form of a search is very efficient at finding its target — but that is only because it is preprogrammed with large amounts of active information needed to quickly find the target. |
- Whatever algorithm is being examined in this paper is barred from changing in-place characters - which means it's not the weasel algorithm,
- the paper doesn't cover all of the known claims of operation of the WEASEL algorithm. Even the authors don't claim so,
- the Hamming Oracle is the fitness function the authors use for various algorithms - including Dawkins's weasel. To equate it with this algorithm highlights the depths of Luskin's lack of knowledge,
- the authors find that Dawkins's algorithm is comparatively inefficient,
- the efficiency or lack thereof of the weasel algorithm doesn't change the fact that it demonstrably works, and
- typically for ham-fisted creationist attempts to analogize information theory into biology, the term most central to Luskin's argument, active information, is not defined, making any claims about its nature or quantity quite irrelevant.
Abstract
Computer search often uses an oracle to determine the value of a proposed problem solution. Information is extracted from the oracle using repeated queries. Crafting a search algorithm to most efficiently extract this information is the job of the programmer. In many instances this is done using the programmer’s experience and knowledge of the problem being solved. For the Hamming oracle, we have the ability to assess the performance of various search algorithms using the currency of query count. Of the search procedures considered, blind search performs the worst. We show that evolutionary algorithms, although better than blind search, are a relatively inefficient method of information extraction. An algorithm methodically establishing and tracking the frequency of occurrence of alphabet characters performs even better. We also show that a search for he search for an optimal tree search, as suggested by our previous work, becomes computationally intensive.
Is there any surprise here? Evolutionary algorithms are somewhat inefficient. So why are they used?
- They are relatively simple to program
- They don't need much knowledge about the fitness function, so they work in many cases
- They are quite stable
But of course, the more you know about the search space, the better you can tailor your algorithm. But this wastes a lot of thinking, i.e., a much scarcer resource in most applications than computer time.
I. Introduction
In their earlier works Conservation of Information in Search - Measuring the Cost of Success and The Search for a Search - Measuring the Information Cost of Higher Level Search, the term oracle wasn't used even once. Now, you find it over twenty times in the introduction alone. Maybe, the numerous comments on threads at Uncommon Descent proposing this view have worked. Or, as DiEb put it in his blog on Aug 26, 2009:
“”...And that's rather a pity: W. Dembski is a guy who is interested in information, and the amount of information which is transferred from a[n] environment into the algorithm. He should be interested in the flow of this information: How is this information exchanged? The answer: Via the conversation with the oracle....[4] |
Another quote: Oracles can be used with relative degrees of efficiency. In the most simple of examples using a needle in a haystack oracle, blind sampling without replacement outperforms blind sampling with replacement in terms of average query count. This seems to be obvious, but it is a new insight for William Dembski - in his draft to The Search for a Search - Measuring the Information Cost of Higher Level Search he thought of both searches as equivalent. So this paper - currently in peer review - should have undergone some serious changes.
II. Information Measures
The authors present their definition of endogenous information 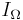 and active information per query
and active information per query 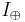 .
.
III. Markov Models for Evolutionary Search
Continuing Error: From wikipedia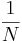 . Thus, the effective mutation rate for example C (Mutating Children With a Fixed Mutation Rate) as seen by an observer is
. Thus, the effective mutation rate for example C (Mutating Children With a Fixed Mutation Rate) as seen by an observer is 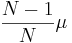 .
.
A. Markov Processes With an Absorbing State
Absolutely nothing new here. Everyone who does some analysis of Dawkins weasel- as Tom English or DiEb - came up with this. That is basic stuff. They shouldn't have stopped here, but calculate - for instance - the variances, too. It's not much harder...
B. Information Measures in Markov Searches
Again, is defined, in this time for a special case.
C. Markov Search
Now, several examples are given.
- (A) K children with a single mutation
One of the most annoying habits of W. Dembski and his friends is to use anything but the standard notation. Numerous times they were made aware of the theory of evolutionary strategies, which dates back into the neolithicum of computer science, the 1960s. And even the first reference[5] of their paper - a title the authors list with surprisingly few errors[6] - introduces this standard. So, their algorithm is just a variant of a 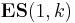 evolutionary strategy - one parent, k children. The authors give us the transition matrix for this case.
evolutionary strategy - one parent, k children. The authors give us the transition matrix for this case.
- (B) Ratchet Strategy
To everybody else known as 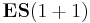 (the next generation exists from the parent and a single child). Again, the mutation is the change of exactly one element in the string, which is a little bit unusual, but works fine. Again, the transition matrix is calculated, a pic is drawn and even a conclusion is made:
(the next generation exists from the parent and a single child). Again, the mutation is the change of exactly one element in the string, which is a little bit unusual, but works fine. Again, the transition matrix is calculated, a pic is drawn and even a conclusion is made:
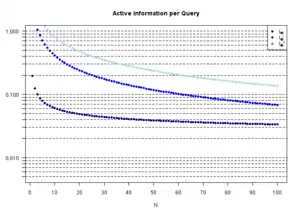
Results : Figure 2(B) shows the active information per query for the ratchet strategy given different alphabet sizes and message lengths. Increasing the message length does not appear to significantly change the efficiency of active information extraction. However, increasing the alphabet size has a rather noticeable effect.
Well, here the authors should really have used the exact solution instead of the numerical one: they came very close to it in an earlier paper (where they called this algorithm optimization by mutation with elitism), and it was stated here at RationalWiki:
The expected number of queries for this version of the is

- so that the average information per query is

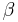 : rate of correct letters to start with
: rate of correct letters to start with k-th harmonic number
k-th harmonic number
- The effect of
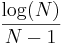 is noticeable, the effect of of
is noticeable, the effect of of  less so.
less so.
BTW: in their earlier paper, Dembski et al. looked at an alphabet with two elements,  . They toggled exactly one bit - getting the mutation rate right, then.
. They toggled exactly one bit - getting the mutation rate right, then.
- (C) Mutating Children With a Fixed Mutation Rate
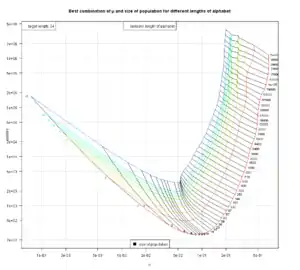
Again, a algorithm, this time the version which is generally agreed to be used in Dawkins weasel: the letters in the parent string are mutated with a fixed mutation rate for a couple of children, which are the next generation. The question which rate of mutation - and which size of a population - should be used for the case N=27 and L=28 has been answered - for instance - here. So the result of this section is - again - no surprise:
Results : As illustrated in Figure 2(C), this algorithm has a slow decline in information per query until it suddenly collapses when the mutation rate becomes too high. If, for example, we are within a single character of identifying a phrase, then a mutation rate that gives on average, say, 10 mutations will take a long time to take the final small step to perfection.
- (D) Optimizing the Mutating Schedule for Children
Something - slightly - new. The mutation rate is not fixed, but evaluated in dependence of the value of the fitness function. Of course, optimizing the mutation probability has always been of interest[7]. The concrete computation for every value from  seems to be quite labor-intensive, though.
seems to be quite labor-intensive, though.
IV. Frequency of Occurrence Hamming Oracle Algorithm
While all algorithms described in the earlier section were random algorithms, here a deterministic one is given. It fares much better than the evolutionary algorithms, at least for the concrete oracle. But as stated above, evolutionary algorithms often work under different circumstances. Imagine for instance an oracle which doesn't state the number of correct letters in a phrase, but the length of the longest correct subphrase. Or the number of correct letters in a row counted from the beginning of the phrase. Or the product of the number of correct consonants and the number of correct vowels and spaces: The algorithms of (A), (B), (C) will still get the result, and (D), too - though it looses its advantages over the other three. But the charmingly called FOOHO algorithm will fail.
But how does this FOOHO algorithm works? That's hard to know, as the authors described the initialization of the algorithm, and then stated:
The remainder of the FOOHOA is best explained by example.
Turns out: it isn't.
But let's approach the algorithm, starting with the with a single mutation per child, the ratchet strategy. The interesting thing about evolutionary strategies: they don't preserve the history - the only memory a new generation can build upon is the current generation. That's of course at odds with the modeling in examinations like the No Free Lunch theorem, which want to keep the searches finitely...
But the can be improved considerably if we allow for some external gathering of data (g.o.d.). That could be a list of the positions of letters which shouldn't altered anymore. Our algorithm  would then look as follows:
would then look as follows:
- start with an empty list and one random phrase
- create a child element by changing a letter at a position not on the g.o.d. list
- if the fitness value of the child differs from the value of the parent, at the position of the changed letter to the list
- if the fitness value equals the length of the phrase: STOP
- if the fitness value of the parent is smaller than the fitness value of the child, than the child is next generation's parent. Otherwise stick to the old parent.
- goto 2
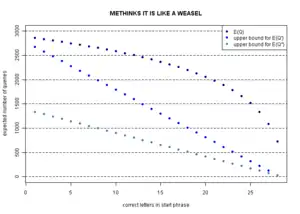
If the first phrase includes 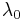 correct letters, that needed
correct letters, that needed  queries, while takes
queries, while takes  . (Why at most? Because
. (Why at most? Because Step 4 will often be reached before all the correct letters have been tested.
But we can put a little bit more thought into it, and reduce it to  . No additional memory is necessary, we just run through the letters not at random, but in a circular way: we chose our position for the letter and we take the next letter in alphabetical order (whatever this alphabet may look like).
. No additional memory is necessary, we just run through the letters not at random, but in a circular way: we chose our position for the letter and we take the next letter in alphabetical order (whatever this alphabet may look like).
As the number of correct letters in the start phrase follows the binomial distribution, we get
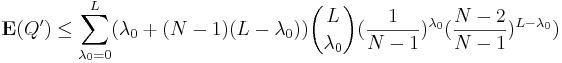 =
= 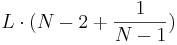 and - similarly -
and - similarly -

How much of g.o.d. is necessary? If we randomly chose the letter which should be changed, we need a field of L values of TRUE or FALSE, if we start at the beginning of the phrase, we only have to remember the position we are currently working at...
Dembski et al. take it a step further - but they need more g.o.d.: in (L-1) steps, they create a list of the number of occurrences of the different letters. Instead of checking the letters in an alphabetical order, they start with the most frequent, and work they way down - if the example is understood correctly. This should improve the algorithm especially for 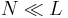 .
.
V. Optimal Hamming Search: A Search for the Search
This should have been the main part of the paper. Unfortunately, it is a little bit short, and though some numbers are stated, no calculations are given. It could have profited from definitions of the basic terms, like search. And some estimations would have be fine. So, it is just not much.
In the following the definitions introduced here are used.
A search in the sense of the paper equals a minimization of a function  , where
, where  - with
- with 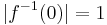 . The set of all these functions is
. The set of all these functions is 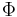 .
.
Perhaps the most simple example for a c.u.p. set F of functions of this type is 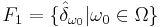 , where:
, where:
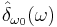

These functions correlate with a search where the only answers of the oracle are found and not found. Here, no clever search algorithm works, everything is at least as bad as blind search (without repetition, of course) - mathematically a result of the c.u.p property.
So, what's about the Hamming oracle? For a alphabet 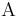 of N letters, and words of length L, we have
of N letters, and words of length L, we have 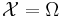
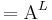
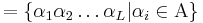 . Then
. Then 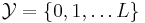 . The set
. The set 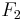 of functions is given by
of functions is given by 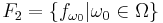
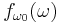
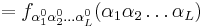
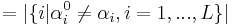 .
.
Interestingly  . But is c.u.p., too? Absolutely not! In fact
. But is c.u.p., too? Absolutely not! In fact 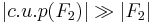 , where
, where 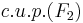 denotes the smallest c.u.p. set of function which contains
denotes the smallest c.u.p. set of function which contains 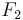 . (How to determine
. (How to determine  ? Think about it! The functions in
? Think about it! The functions in 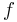 in are determined by their
in are determined by their 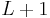 level-sets, i.e.,
level-sets, i.e., 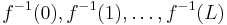 . How big are these?
. How big are these? 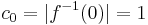 ,
, 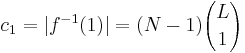 ,
, 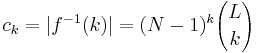 ,
, ,
,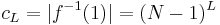 . Any function with level-sets of this size for the different values of the function is in the c.u.p. set a functions including . So, there are
. Any function with level-sets of this size for the different values of the function is in the c.u.p. set a functions including . So, there are
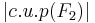
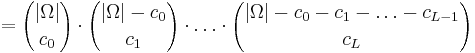
functions. BTW, the analogous calculation for 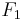 and the two level
and the two level  shows again that is c.u.p. : here,
shows again that is c.u.p. : here, 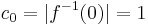 , and
, and 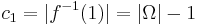 , therefore
, therefore
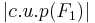

Let's have a look how large the sets are which we were talking about. We'll follow the author's lead and look at alphabets of size 2 - 6, and words of length 1 - 6:
| ↓ #Alphabet N | 1 | 2 | 3 | 4 | 5 | 6 | ← Length of Word L |
|---|---|---|---|---|---|---|---|
| 2 | 2 | 4 | 8 | 16 | 32 | 64 |  |
| 2 | 12 | 112 | 5.04 107 | 1.38 1018 | 5.88 1040 | | |
| 2 | 32 | 17496 | 1.72 1010 | 1.49 1023 | 6.76 1050 | 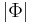 | |
| 3 | 3 | 9 | 27 | 81 | 243 | 749 | |
| 3 | 630 | 7.83 1011 | 4.21 1043 | 1.44 10148 | 4.18 10482 | | |
| 3 | 2304 | 6.86 1013 | 1.18 1050 | 3.44 10171 | 2.27 10569 | | |
| 4 | 4 | 16 | 64 | 256 | 1024 | 4096 | |
| 4 | 8.01 104 | 2.95 1027 | 1.01 10132 | 1.06 10591 | 7.18 102554 | | |
| 4 | 5.24 105 | 7.32 1032 | 8.58 10155 | 1.14 10718 | 1.39 103190 | | |
| 5 | 5 | 25 | 125 | 625 | 3125 | 15625 | |
| 5 | 1.83 107 | 2.50 1050 | 4.02 10300 | 3.13 101680 | 1.86 109101 | | |
| 5 | 4.19 108 | 1.82 1061 | 3.03 10378 | 1.19 102187 | 1.07 1012,162 | | |
| 6 | 6 | 36 | 216 | 1296 | 7776 | 46,656 | |
| 6 | 6.61 109 | 1.64 1081 | 1.07 10580 | 1.28 103899 | 4.37 1025,433 | | |
| 6 | 1.23 1012 | 8.23 10104 | 6.03 10782 | 2.41 105438 | 2.07 1036,309 | |
So, the functions based Hamming distance are only a minuscule part of all functions. And for these, the authors have calculated an optimal algorithm - at least for very small values of N and L. How so? They made an exhaustive inspection of all possible algorithms and looked for those who needed on average over all functions in the least steps to identify the function. Here are the values of the paper:
| ↓ #Alphabet N | 1 | 2 | 3 | 4 | 5 | 6 | ← Length of Word L |
|---|---|---|---|---|---|---|---|
| 2 | 1.000 | 1.500 | 2.250 | 2.750 | 3.375 | 3.875 | |
| 3 | 1.667 | 2.337 | 2.889 | 3.469 | - | - | |
| 4 | 2.250 | 3.125 | 3.822 | - | - | - | |
| 5 | 2.800 | 3.281 | - | - | - | - | |
| 6 | 3.333 | 4.611 | - | - | - | - |
The authors state that in general, a search for a search (S4S) is exponentially more computationally demanding than a search itself. But this is of course the search for an optimal search. In their paper A study of Some Implications of the No Free Lunch Theorem[8] the authors Andrea Valsecchi and Leonardo Vanneschi propose an algorithm to look for a quite good search. The next table is based on an implementation of their idea:
| ↓ #Alphabet N | 1 | 2 | 3 | 4 | 5 | 6 | ← Length of Word L |
|---|---|---|---|---|---|---|---|
| 2 | 1.000 | 1.500 | 2.250 | 2.875 | 3.500 | 4.013 | |
| 3 | 1.667 | 2.333 | 3.037 | 3.827 | 4.407 | 4.8779 | |
| 4 | 2.250 | 3.125 | 3.938 | 4.727 | 5.389 | 5.948 | |
| 5 | 2.800 | 3.880 | 4.776 | 5.608 | 6.369 | 7.037 | |
| 6 | 3.333 | 4.611 | 5.588 | 6.488 | 7.324 | - |
(italic: same value as in previous table)
The values are generally worse than those of Dembski et al.'s exhaustive inspection, but the algorithm to find them has only computational complexity of 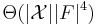
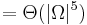 .
.
What has this all to do with the theory of evolution or intelligent design
Short answer: Nothing.
Dembski announced this article as deconstructing the Dawkin's weasel. Just one question: which algorithms were the easiest to program - and the easiest to evaluate? Yep, the weasel-type ones. Didn't take much intelligence to realize them, and that's—IMO—the main result.
Furthermore, evolution isn't about the survival of the fittest; it's about survival of the fittest present—and absolutely not survival of the theoretically fittest.
So, it's nice to see the lower bounds for the search algorithms. And though evolution brought forth optimal solutions for some problems—which are used in bionics
VI. Conclusions
By exploring a variety of algorithms we have demonstrated hat the simple Hamming oracle can be used with surprisingly different degrees of efficiency as measured by query count. The FOO Hamming oracle algorithm manages to extract approximately one bit of information per query indicating hat the oracle can be a significant source of information. In comparison, evolutionary search as modeled by Markov processes uses the Hamming oracle inefficiently. The success of a searches derives not from any intrinsic property of the search algorithm, but from the information available from the oracle as well as the efficiency of the search algorithm in the extraction of that information. A high level interactive simulation of algorithms showing their varying effectiveness in extracting active information using a Hamming oracle is available on line at www.evoinfo.org.
That doesn't seem to be so surprising. Amusingly, it is a consequence of Dembski's favourite No Free Lunch theorem, that an algorithm which outperforms all others for a certain oracle will be less efficient for other oracles. And it's a strength of simply-built evolutionary algorithms that they work well with a great class of sensible oracles.
See also
References
- Efficient Per Query Information Extraction from a Hamming Oracle, Winston Ewert, George Montañez, William A. Dembski, Robert J. Marks II (pdf)
- http://www.uncommondescent.com/evolution/new-peer-reviewed-id-paper-deconstructing-the-dawkins-weasel/
- William Dembski, Robert Marks, and the Evolutionary Informatics Lab Take on Dawkins’ “WEASEL” Simulation in New Peer-Reviewed Paper, Casey Luskin, April 8, 2010, Evolution: News and Views
- DiEbLog Aut 26, 2009
- Thomas Back, Evolutionary Algorithms in Theory and Practice: Evolution Strategies, Evolutionary Programming, Genetic Algorithms
- Thomas Back should be Thomas Bäck or Thomas Baeck, per German orthographic conventions.
- Global Properties of Evolution Processes (Appendix) by H. J. Bremermann, M. Rogson, S. Salaff in Natural Automata and Useful Simulations, H.H. Pattee, E.A.Edelsack, L.Fein, and A.B.Callahan (eds), Spartan Books, Washington D.C, 1966
- Andrea Valsecchi and Leonardo Vanneschi (2008), A study of Some Implications of the No Free Lunch Theorem, Applications of Evolutionary Computing, Volume 4974/2008, Springer Berlin/Heidelberg, pp. 634-635