Maximum likelihood estimation
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of a probability distribution by maximizing a likelihood function, so that under the assumed statistical model the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate.[1] The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.[2][3][4]
If the likelihood function is differentiable, the derivative test for determining maxima can be applied. In some cases, the first-order conditions of the likelihood function can be solved explicitly; for instance, the ordinary least squares estimator maximizes the likelihood of the linear regression model.[5] Under most circumstances, however, numerical methods will be necessary to find the maximum of the likelihood function.
From the vantage point of Bayesian inference, MLE is a special case of maximum a posteriori estimation (MAP) that assumes a uniform prior distribution of the parameters. In frequentist inference, MLE is a special case of an extremum estimator, with the objective function being the likelihood.
Principles
From a statistical standpoint, a given set of observations are a random sample from an unknown population. The goal of maximum likelihood estimation is to make inferences about the population that is most likely to have generated the sample,[6] specifically the joint probability distribution of the random variables , not necessarily independent and identically distributed. Associated with each probability distribution is a unique vector of parameters that index the probability distribution within a parametric family , where is called the parameter space, a finite-dimensional subset of Euclidean space. Evaluating the joint density at the observed data sample gives a real-valued function,






which is called the likelihood function. For independent and identically distributed random variables, will be the product of univariate density functions.

The goal of maximum likelihood estimation is to find the values of the model parameters that maximize the likelihood function over the parameter space,[6] that is

Intuitively, this selects the parameter values that make the observed data most probable. The specific value that maximizes the likelihood function is called the maximum likelihood estimate. Further, if the function so defined is measurable, then it is called the maximum likelihood estimator. It is generally a function defined over the sample space, i.e. taking a given sample as its argument. A sufficient but not necessary condition for its existence is for the likelihood function to be continuous over a parameter space that is compact.[7] For an open the likelihood function may increase without ever reaching a supremum value.



In practice, it is often convenient to work with the natural logarithm of the likelihood function, called the log-likelihood:

Since the logarithm is a monotonic function, the maximum of occurs at the same value of as does the maximum of .[8] If is differentiable in , the necessary conditions for the occurrence of a maximum (or a minimum) are



known as the likelihood equations. For some models, these equations can be explicitly solved for , but in general no closed-form solution to the maximization problem is known or available, and an MLE can only be found via numerical optimization. Another problem is that in finite samples, there may exist multiple roots for the likelihood equations.[9] Whether the identified root of the likelihood equations is indeed a (local) maximum depends on whether the matrix of second-order partial and cross-partial derivatives,


known as the Hessian matrix is negative semi-definite at , which indicates local concavity. Conveniently, most common probability distributions—in particular the exponential family—are logarithmically concave.[10][11]
Restricted parameter space
While the domain of the likelihood function—the parameter space—is generally a finite-dimensional subset of Euclidean space, additional restrictions sometimes need to be incorporated into the estimation process. The parameter space can be expressed as
- ,

where is a vector-valued function mapping into . Estimating the true parameter belonging to then, as a practical matter, means to find the maximum of the likelihood function subject to the constraint .




Theoretically, the most natural approach to this constrained optimization problem is the method of substitution, that is "filling out" the restrictions to a set in such a way that is a one-to-one function from to itself, and reparameterize the likelihood function by setting .[12] Because of the invariance of the maximum likelihood estimator, the properties of the MLE apply to the restricted estimates also.[13] For instance, in a multivariate normal distribution the covariance matrix must be positive-definite; this restriction can be imposed by replacing , where is a real upper triangular matrix and is its transpose.[14]








In practice, restrictions are usually imposed using the method of Lagrange which, given the constraints as defined above, leads to the restricted likelihood equations
- and ,

where is a column-vector of Lagrange multipliers and is the k × r Jacobian matrix of partial derivatives.[12] Naturally, if the constraints are nonbinding at the maximum, the Lagrange multipliers should be zero.[15] This in turn allows for a statistical test of the "validity" of the constraint, known as the Lagrange multiplier test.


Properties
A maximum likelihood estimator is an extremum estimator obtained by maximizing, as a function of θ, the objective function . If the data are independent and identically distributed, then we have


this being the sample analogue of the expected log-likelihood , where this expectation is taken with respect to the true density.

Maximum-likelihood estimators have no optimum properties for finite samples, in the sense that (when evaluated on finite samples) other estimators may have greater concentration around the true parameter-value.[16] However, like other estimation methods, maximum likelihood estimation possesses a number of attractive limiting properties: As the sample size increases to infinity, sequences of maximum likelihood estimators have these properties:
- Consistency: the sequence of MLEs converges in probability to the value being estimated.
- Functional Invariance: If is the maximum likelihood estimator for , and if is any transformation of , then the maximum likelihood estimator for is .
- Efficiency, i.e. it achieves the Cramér–Rao lower bound when the sample size tends to infinity. This means that no consistent estimator has lower asymptotic mean squared error than the MLE (or other estimators attaining this bound), which also means that MLE has asymptotic normality.
- Second-order efficiency after correction for bias.




Consistency
Under the conditions outlined below, the maximum likelihood estimator is consistent. The consistency means that if the data were generated by and we have a sufficiently large number of observations n, then it is possible to find the value of θ0 with arbitrary precision. In mathematical terms this means that as n goes to infinity the estimator converges in probability to its true value:


Under slightly stronger conditions, the estimator converges almost surely (or strongly):

In practical applications, data is never generated by . Rather, is a model, often in idealized form, of the process that generated by the data. It is a common aphorism in statistics that all models are wrong. Thus, true consistency does not occur in practical applications. Nevertheless, consistency is often considered to be a desirable property for an estimator to have.
To establish consistency, the following conditions are sufficient.[17]
- Identification of the model:
In other words, different parameter values θ correspond to different distributions within the model. If this condition did not hold, there would be some value θ1 such that θ0 and θ1 generate an identical distribution of the observable data. Then we would not be able to distinguish between these two parameters even with an infinite amount of data—these parameters would have been observationally equivalent.
The identification condition is absolutely necessary for the ML estimator to be consistent. When this condition holds, the limiting likelihood function ℓ(θ|·) has unique global maximum at θ0. - Compactness: the parameter space Θ of the model is compact.
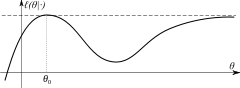
The identification condition establishes that the log-likelihood has a unique global maximum. Compactness implies that the likelihood cannot approach the maximum value arbitrarily close at some other point (as demonstrated for example in the picture on the right).
Compactness is only a sufficient condition and not a necessary condition. Compactness can be replaced by some other conditions, such as:
- both concavity of the log-likelihood function and compactness of some (nonempty) upper level sets of the log-likelihood function, or
- existence of a compact neighborhood N of θ0 such that outside of N the log-likelihood function is less than the maximum by at least some ε > 0.
- Continuity: the function ln f(x | θ) is continuous in θ for almost all values of x:
- Dominance: there exists D(x) integrable with respect to the distribution f(x | θ0) such that
By the uniform law of large numbers, the dominance condition together with continuity establish the uniform convergence in probability of the log-likelihood:




The dominance condition can be employed in the case of i.i.d. observations. In the non-i.i.d. case, the uniform convergence in probability can be checked by showing that the sequence is stochastically equicontinuous.

If one wants to demonstrate that the ML estimator converges to θ0 almost surely, then a stronger condition of uniform convergence almost surely has to be imposed:

Additionally, if (as assumed above) the data were generated by , then under certain conditions, it can also be shown that the maximum likelihood estimator converges in distribution to a normal distribution. Specifically,[18]

where I is the Fisher information matrix.
Functional invariance
The maximum likelihood estimator selects the parameter value which gives the observed data the largest possible probability (or probability density, in the continuous case). If the parameter consists of a number of components, then we define their separate maximum likelihood estimators, as the corresponding component of the MLE of the complete parameter. Consistent with this, if is the MLE for , and if is any transformation of , then the MLE for is by definition[19]

It maximizes the so-called profile likelihood:

The MLE is also invariant with respect to certain transformations of the data. If where is one to one and does not depend on the parameters to be estimated, then the density functions satisfy



and hence the likelihood functions for and differ only by a factor that does not depend on the model parameters.


For example, the MLE parameters of the log-normal distribution are the same as those of the normal distribution fitted to the logarithm of the data.
Efficiency
As assumed above, the data were generated by , then under certain conditions, it can also be shown that the maximum likelihood estimator converges in distribution to a normal distribution. It is √n -consistent and asymptotically efficient, meaning that it reaches the Cramér–Rao bound. Specifically,[18]

where is the Fisher information matrix:


In particular, it means that the bias of the maximum likelihood estimator is equal to zero up to the order 1⁄√n .
Second-order efficiency after correction for bias
However, when we consider the higher-order terms in the expansion of the distribution of this estimator, it turns out that θmle has bias of order 1⁄n. This bias is equal to (componentwise)[20]

where denotes the (j,k)-th component of the inverse Fisher information matrix , and



Using these formulae it is possible to estimate the second-order bias of the maximum likelihood estimator, and correct for that bias by subtracting it:

This estimator is unbiased up to the terms of order 1⁄n, and is called the bias-corrected maximum likelihood estimator.
This bias-corrected estimator is second-order efficient (at least within the curved exponential family), meaning that it has minimal mean squared error among all second-order bias-corrected estimators, up to the terms of the order 1⁄n2 . It is possible to continue this process, that is to derive the third-order bias-correction term, and so on. However the maximum likelihood estimator is not third-order efficient.[21]
Relation to Bayesian inference
A maximum likelihood estimator coincides with the most probable Bayesian estimator given a uniform prior distribution on the parameters. Indeed, the maximum a posteriori estimate is the parameter θ that maximizes the probability of θ given the data, given by Bayes' theorem:

where is the prior distribution for the parameter θ and where is the probability of the data averaged over all parameters. Since the denominator is independent of θ, the Bayesian estimator is obtained by maximizing with respect to θ. If we further assume that the prior is a uniform distribution, the Bayesian estimator is obtained by maximizing the likelihood function . Thus the Bayesian estimator coincides with the maximum likelihood estimator for a uniform prior distribution .





Application of maximum-likelihood estimation in Bayes decision theory
In many practical applications in machine learning, maximum-likelihood estimation is used as the model for parameter estimation.
The Bayesian Decision theory is about designing a classifier that minimizes total expected risk, especially, when the costs (the loss function) associated with different decisions are equal, the classifier is minimizing the error over the whole distribution.[22]
Thus, the Bayes Decision Rule is stated as "decide if ; otherwise ", where , are predictions of different classes. From a perspective of minimizing error, it can also be stated as , where if we decide and if we decide .






By applying Bayes' theorem : , and if we further assume the zero/one loss function, which is a same loss for all errors, the Bayes Decision rule can be reformulated as:

, where is the prediction and is the priori probability.



Relation to minimizing Kullback–Leibler divergence and cross entropy
Finding that maximizes the likelihood is asymptotically equivalent to finding the that defines a probability distribution () that has a minimal distance, in terms of Kullback–Leibler divergence, to the real probability distribution from which our data was generated (i.e., generated by ).[23] In an ideal world, P and Q are the same (and the only thing unknown is that defines P), but even if they are not and the model we use is misspecified, still the MLE will give us the "closest" distribution (within the restriction of a model Q that depends on ) to the real distribution .[24]


| Proof. |
|
For simplicity of notation, let's assume that P=Q. Let there be n i.i.d data sample from some probability , that we try to estimate by finding that will maximize the likelihood using , then: Where . Using h helps see how we are using the law of large numbers to move from the average of h(x) to the expectancy of it using the law of the unconscious statistician. The first several transitions has to do with laws of logarithm and that finding that maximizes some function will also be the one that maximizes some monotonic transformation of that function (i.e.: adding/multiplying by a constant). |




Since cross entropy is just Shannon's Entropy plus KL divergence, and since the Entropy of is constant, then the MLE is also asymptotically minimizing cross entropy.[25]
Examples
Discrete uniform distribution
Consider a case where n tickets numbered from 1 to n are placed in a box and one is selected at random (see uniform distribution); thus, the sample size is 1. If n is unknown, then the maximum likelihood estimator of n is the number m on the drawn ticket. (The likelihood is 0 for n < m, 1⁄n for n ≥ m, and this is greatest when n = m. Note that the maximum likelihood estimate of n occurs at the lower extreme of possible values {m, m + 1, ...}, rather than somewhere in the "middle" of the range of possible values, which would result in less bias.) The expected value of the number m on the drawn ticket, and therefore the expected value of , is (n + 1)/2. As a result, with a sample size of 1, the maximum likelihood estimator for n will systematically underestimate n by (n − 1)/2.

Discrete distribution, finite parameter space
Suppose one wishes to determine just how biased an unfair coin is. Call the probability of tossing a ‘head’ p. The goal then becomes to determine p.
Suppose the coin is tossed 80 times: i.e. the sample might be something like x1 = H, x2 = T, ..., x80 = T, and the count of the number of heads "H" is observed.
The probability of tossing tails is 1 − p (so here p is θ above). Suppose the outcome is 49 heads and 31 tails, and suppose the coin was taken from a box containing three coins: one which gives heads with probability p = 1⁄3, one which gives heads with probability p = 1⁄2 and another which gives heads with probability p = 2⁄3. The coins have lost their labels, so which one it was is unknown. Using maximum likelihood estimation, the coin that has the largest likelihood can be found, given the data that were observed. By using the probability mass function of the binomial distribution with sample size equal to 80, number successes equal to 49 but for different values of p (the "probability of success"), the likelihood function (defined below) takes one of three values:

The likelihood is maximized when p = 2⁄3, and so this is the maximum likelihood estimate for p.
Discrete distribution, continuous parameter space
Now suppose that there was only one coin but its p could have been any value 0 ≤ p ≤ 1. The likelihood function to be maximised is

and the maximisation is over all possible values 0 ≤ p ≤ 1.
One way to maximize this function is by differentiating with respect to p and setting to zero:

This is a product of three terms. The first term is 0 when p = 0. The second is 0 when p = 1. The third is zero when p = 49⁄80. The solution that maximizes the likelihood is clearly p = 49⁄80 (since p = 0 and p = 1 result in a likelihood of 0). Thus the maximum likelihood estimator for p is 49⁄80.
This result is easily generalized by substituting a letter such as s in the place of 49 to represent the observed number of 'successes' of our Bernoulli trials, and a letter such as n in the place of 80 to represent the number of Bernoulli trials. Exactly the same calculation yields s⁄n which is the maximum likelihood estimator for any sequence of n Bernoulli trials resulting in s 'successes'.
Continuous distribution, continuous parameter space
For the normal distribution which has probability density function


the corresponding probability density function for a sample of n independent identically distributed normal random variables (the likelihood) is

This family of distributions has two parameters: θ = (μ, σ); so we maximize the likelihood, , over both parameters simultaneously, or if possible, individually.

Since the logarithm function itself is a continuous strictly increasing function over the range of the likelihood, the values which maximize the likelihood will also maximize its logarithm (the log-likelihood itself is not necessarily strictly increasing). The log-likelihood can be written as follows:

(Note: the log-likelihood is closely related to information entropy and Fisher information.)
We now compute the derivatives of this log-likelihood as follows.

where is the sample mean. This is solved by


This is indeed the maximum of the function, since it is the only turning point in μ and the second derivative is strictly less than zero. Its expected value is equal to the parameter μ of the given distribution,

which means that the maximum likelihood estimator is unbiased.

Similarly we differentiate the log-likelihood with respect to σ and equate to zero:

which is solved by

Inserting the estimate we obtain


To calculate its expected value, it is convenient to rewrite the expression in terms of zero-mean random variables (statistical error) . Expressing the estimate in these variables yields


Simplifying the expression above, utilizing the facts that and , allows us to obtain



This means that the estimator is biased. However, is consistent.

Formally we say that the maximum likelihood estimator for is


In this case the MLEs could be obtained individually. In general this may not be the case, and the MLEs would have to be obtained simultaneously.
The normal log-likelihood at its maximum takes a particularly simple form:

This maximum log-likelihood can be shown to be the same for more general least squares, even for non-linear least squares. This is often used in determining likelihood-based approximate confidence intervals and confidence regions, which are generally more accurate than those using the asymptotic normality discussed above.
Non-independent variables
It may be the case that variables are correlated, that is, not independent. Two random variables and are independent only if their joint probability density function is the product of the individual probability density functions, i.e.



Suppose one constructs an order-n Gaussian vector out of random variables , where each variable has means given by . Furthermore, let the covariance matrix be denoted by . The joint probability density function of these n random variables is then follows a multivariate normal distribution given by:




In the bivariate case, the joint probability density function is given by:

In this and other cases where a joint density function exists, the likelihood function is defined as above, in the section "principles," using this density.
Example
are counts in cells / boxes 1 up to m; each box has a different probability (think of the boxes being bigger or smaller) and we fix the number of balls that fall to be :. The probability of each box is , with a constraint: . This is a case in which the s are not independent, the joint probability of a vector is called the multinomial and has the form:








Each box taken separately against all the other boxes is a binomial and this is an extension thereof.
The log-likelihood of this is:

The constraint has to be taken into account and use the Lagrange multipliers:

By posing all the derivatives to be 0, the most natural estimate is derived

Maximizing log likelihood, with and without constraints, can be an unsolvable problem in closed form, then we have to use iterative procedures.
Iterative procedures
Except for special cases, the likelihood equations

cannot be solved explicitly for an estimator . Instead, they need to be solved iteratively: starting from an initial guess of (say ), one seeks to obtain a convergent sequence . Many methods for this kind of optimization problem are available,[26][27] but the most commonly used ones are algorithms based on an updating formula of the form




where the vector indicates the descent direction of the rth "step," and the scalar captures the "step length,"[28][29] also known as the learning rate.[30]


Gradient descent method
(Note: here it is a maximization problem, so the sign before gradient is flipped)
- that is small enough for convergence and


Gradient descent method requires to calculate the gradient at the rth iteration, but no need to calculate the inverse of second-order derivative, i.e., the Hessian matrix. Therefore, it is computationally faster than Newton-Raphson method.
Newton–Raphson method
- and


where is the score and is the inverse of the Hessian matrix of the log-likelihood function, both evaluated the rth iteration.[31][32] But because the calculation of the Hessian matrix is computationally costly, numerous alternatives have been proposed. The popular Berndt–Hall–Hall–Hausman algorithm approximates the Hessian with the outer product of the expected gradient, such that



Quasi-Newton methods
Other quasi-Newton methods use more elaborate secant updates to give approximation of Hessian matrix.
Davidon–Fletcher–Powell formula
DFP formula finds a solution that is symmetric, positive-definite and closest to the current approximate value of second-order derivative:

where



Broyden–Fletcher–Goldfarb–Shanno algorithm
BFGS also gives a solution that is symmetric and positive-definite:

where
BFGS method is not guaranteed to converge unless the function has a quadratic Taylor expansion near an optimum. However, BFGS can have acceptable performance even for non-smooth optimization instances
Fisher's scoring
Another popular method is to replace the Hessian with the Fisher information matrix, , giving us the Fisher scoring algorithm. This procedure is standard in the estimation of many methods, such as generalized linear models.

Although popular, quasi-Newton methods may converge to a stationary point that is not necessarily a local or global maximum,[33] but rather a local minimum or a saddle point. Therefore, it is important to assess the validity of the obtained solution to the likelihood equations, by verifying that the Hessian, evaluated at the solution, is both negative definite and well-conditioned.[34]
History

Early users of maximum likelihood were Carl Friedrich Gauss, Pierre-Simon Laplace, Thorvald N. Thiele, and Francis Ysidro Edgeworth.[35][36] However, its widespread use rose between 1912 and 1922 when Ronald Fisher recommended, widely popularized, and carefully analyzed maximum-likelihood estimation (with fruitless attempts at proofs).[37]
Maximum-likelihood estimation finally transcended heuristic justification in a proof published by Samuel S. Wilks in 1938, now called Wilks' theorem.[38] The theorem shows that the error in the logarithm of likelihood values for estimates from multiple independent observations is asymptotically χ 2-distributed, which enables convenient determination of a confidence region around any estimate of the parameters. The only difficult part of Wilks’ proof depends on the expected value of the Fisher information matrix, which is provided by a theorem proven by Fisher.[39] Wilks continued to improve on the generality of the theorem throughout his life, with his most general proof published in 1962.[40]
Reviews of the development of maximum likelihood estimation have been provided by a number of authors.[41][42][43][44][45][46][47][48]
See also
Other estimation methods
- Generalized method of moments are methods related to the likelihood equation in maximum likelihood estimation
- M-estimator, an approach used in robust statistics
- Maximum a posteriori (MAP) estimator, for a contrast in the way to calculate estimators when prior knowledge is postulated
- Maximum spacing estimation, a related method that is more robust in many situations
- Maximum entropy estimation
- Method of moments (statistics), another popular method for finding parameters of distributions
- Method of support, a variation of the maximum likelihood technique
- Minimum distance estimation
- Partial likelihood methods for panel data
- Quasi-maximum likelihood estimator, an MLE estimator that is misspecified, but still consistent
- Restricted maximum likelihood, a variation using a likelihood function calculated from a transformed set of data
Related concepts
- Akaike information criterion, a criterion to compare statistical models, based on MLE
- Extremum estimator, a more general class of estimators to which MLE belongs
- Fisher information, information matrix, its relationship to covariance matrix of ML estimates
- Mean squared error, a measure of how 'good' an estimator of a distributional parameter is (be it the maximum likelihood estimator or some other estimator)
- RANSAC, a method to estimate parameters of a mathematical model given data that contains outliers
- Rao–Blackwell theorem, which yields a process for finding the best possible unbiased estimator (in the sense of having minimal mean squared error); the MLE is often a good starting place for the process
- Wilks’ theorem provides a means of estimating the size and shape of the region of roughly equally-probable estimates for the population's parameter values, using the information from a single sample, using a chi-squared distribution
References
- Rossi, Richard J. (2018). Mathematical Statistics : An Introduction to Likelihood Based Inference. New York: John Wiley & Sons. p. 227. ISBN 978-1-118-77104-4.
- Hendry, David F.; Nielsen, Bent (2007). Econometric Modeling: A Likelihood Approach. Princeton: Princeton University Press. ISBN 978-0-691-13128-3.
- Chambers, Raymond L.; Steel, David G.; Wang, Suojin; Welsh, Alan (2012). Maximum Likelihood Estimation for Sample Surveys. Boca Raton: CRC Press. ISBN 978-1-58488-632-7.
- Ward, Michael Don; Ahlquist, John S. (2018). Maximum Likelihood for Social Science : Strategies for Analysis. New York: Cambridge University Press. ISBN 978-1-107-18582-1.
- Press, W. H.; Flannery, B. P.; Teukolsky, S. A.; Vetterling, W. T. (1992). "Least Squares as a Maximum Likelihood Estimator". Numerical Recipes in FORTRAN: The Art of Scientific Computing (2nd ed.). Cambridge: Cambridge University Press. pp. 651–655. ISBN 0-521-43064-X.
- Myung, I. J. (2003). "Tutorial on Maximum Likelihood Estimation". Journal of Mathematical Psychology. 47 (1): 90–100. doi:10.1016/S0022-2496(02)00028-7.
- Gourieroux, Christian; Monfort, Alain (1995). Statistics and Econometrics Models. Cambridge University Press. p. 161. ISBN 0-521-40551-3.
- Kane, Edward J. (1968). Economic Statistics and Econometrics. New York: Harper & Row. p. 179.
- Small, Christoper G.; Wang, Jinfang (2003). "Working with Roots". Numerical Methods for Nonlinear Estimating Equations. Oxford University Press. pp. 74–124. ISBN 0-19-850688-0.
- Kass, Robert E.; Vos, Paul W. (1997). Geometrical Foundations of Asymptotic Inference. New York: John Wiley & Sons. p. 14. ISBN 0-471-82668-5.
- Papadopoulos, Alecos (September 25, 2013). "Why we always put log() before the joint pdf when we use MLE (Maximum likelihood Estimation)?". Stack Exchange.
- Silvey, S. D. (1975). Statistical Inference. London: Chapman and Hall. p. 79. ISBN 0-412-13820-4.
- Olive, David (2004). "Does the MLE Maximize the Likelihood?" (PDF). Cite journal requires
|journal=(help) - Schwallie, Daniel P. (1985). "Positive Definite Maximum Likelihood Covariance Estimators". Economics Letters. 17 (1–2): 115–117. doi:10.1016/0165-1765(85)90139-9.
- Magnus, Jan R. (2017). Introduction to the Theory of Econometrics. Amsterdam: VU University Press. pp. 64–65. ISBN 978-90-8659-766-6.
- Pfanzagl (1994, p. 206)
- By Theorem 2.5 in Newey, Whitney K.; McFadden, Daniel (1994). "Chapter 36: Large sample estimation and hypothesis testing". In Engle, Robert; McFadden, Dan (eds.). Handbook of Econometrics, Vol.4. Elsevier Science. pp. 2111–2245. ISBN 978-0-444-88766-5.
- By Theorem 3.3 in Newey, Whitney K.; McFadden, Daniel (1994). "Chapter 36: Large sample estimation and hypothesis testing". In Engle, Robert; McFadden, Dan (eds.). Handbook of Econometrics, Vol.4. Elsevier Science. pp. 2111–2245. ISBN 978-0-444-88766-5.
- Zacks, Shelemyahu (1971). The Theory of Statistical Inference. New York: John Wiley & Sons. p. 223. ISBN 0-471-98103-6.
- See formula 20 in Cox, David R.; Snell, E. Joyce (1968). "A general definition of residuals". Journal of the Royal Statistical Society, Series B. 30 (2): 248–275. JSTOR 2984505.
- Kano, Yutaka (1996). "Third-order efficiency implies fourth-order efficiency". Journal of the Japan Statistical Society. 26: 101–117. doi:10.14490/jjss1995.26.101.CS1 maint: ref=harv (link)
- Christensen, Henrik I., Bayesian Decision Theory - CS 7616 - Pattern Recognition (PDF) (presentation)
- cmplx96 (https://stats.stackexchange.com/users/177679/cmplx96), Kullback–Leibler divergence, URL (version: 2017-11-18): https://stats.stackexchange.com/q/314472 (at the youtube video, look at minutes 13 to 25)
- Introduction to Statistical Inference | Stanford (Lecture 16 — MLE under model misspecification)
- Sycorax says Reinstate Monica (https://stats.stackexchange.com/users/22311/sycorax-says-reinstate-monica), the relationship between maximizing the likelihood and minimizing the cross-entropy, URL (version: 2019-11-06): https://stats.stackexchange.com/q/364237
- Fletcher, R. (1987). Practical Methods of Optimization (Second ed.). New York: John Wiley & Sons. ISBN 0-471-91547-5.
- Nocedal, Jorge; Wright, Stephen J. (2006). Numerical Optimization (Second ed.). New York: Springer. ISBN 0-387-30303-0.
- Daganzo, Carlos (1979). Multinomial Probit : The Theory and its Application to Demand Forecasting. New York: Academic Press. pp. 61–78. ISBN 0-12-201150-3.
- Gould, William; Pitblado, Jeffrey; Poi, Brian (2010). Maximum Likelihood Estimation with Stata (Fourth ed.). College Station: Stata Press. pp. 13–20. ISBN 978-1-59718-078-8.
- Murphy, Kevin P. (2012). Machine Learning: A Probabilistic Perspective. Cambridge: MIT Press. p. 247. ISBN 978-0-262-01802-9.
- Amemiya, Takeshi (1985). Advanced Econometrics. Cambridge: Harvard University Press. pp. 137–138. ISBN 0-674-00560-0.
- Sargan, Denis (1988). "Methods of Numerical Optimization". Lecture Notes on Advanced Econometric Theory. Oxford: Basil Blackwell. pp. 161–169. ISBN 0-631-14956-2.
- See theorem 10.1 in Avriel, Mordecai (1976). Nonlinear Programming: Analysis and Methods. Englewood Cliffs: Prentice-Hall. pp. 293–294. ISBN 9780486432274.
- Gill, Philip E.; Murray, Walter; Wright, Margaret H. (1981). Practical Optimization. London: Academic Press. pp. 312–313. ISBN 0-12-283950-1.
- Edgeworth, Francis Y. (Sep 1908). "On the probable errors of frequency-constants". Journal of the Royal Statistical Society. 71 (3): 499–512. doi:10.2307/2339293. JSTOR 2339293.
- Edgeworth, Francis Y. (Dec 1908). "On the probable errors of frequency-constants". Journal of the Royal Statistical Society. 71 (4): 651–678. doi:10.2307/2339378. JSTOR 2339378.
- Pfanzagl, Johann, with the assistance of R. Hamböker (1994). Parametric Statistical Theory. Walter de Gruyter. pp. 207–208. ISBN 978-3-11-013863-4.CS1 maint: multiple names: authors list (link)
- Wilks, S. S. (1938). "The Large-Sample Distribution of the Likelihood Ratio for Testing Composite Hypotheses". Annals of Mathematical Statistics. 9: 60–62. doi:10.1214/aoms/1177732360.
- Owen, Art B. (2001). Empirical Likelihood. London: Chapman & Hall/Boca Raton, FL: CRC Press. ISBN 978-1584880714.
- Wilks, Samuel S. (1962), Mathematical Statistics, New York: John Wiley & Sons. ISBN 978-0471946502.
- Savage, Leonard J. (1976). "On rereading R. A. Fisher". The Annals of Statistics. 4 (3): 441–500. doi:10.1214/aos/1176343456. JSTOR 2958221.
- Pratt, John W. (1976). "F. Y. Edgeworth and R. A. Fisher on the efficiency of maximum likelihood estimation". The Annals of Statistics. 4 (3): 501–514. doi:10.1214/aos/1176343457. JSTOR 2958222.
- Stigler, Stephen M. (1978). "Francis Ysidro Edgeworth, statistician". Journal of the Royal Statistical Society, Series A. 141 (3): 287–322. doi:10.2307/2344804. JSTOR 2344804.
- Stigler, Stephen M. (1986). The history of statistics: the measurement of uncertainty before 1900. Harvard University Press. ISBN 978-0-674-40340-6.
- Stigler, Stephen M. (1999). Statistics on the table: the history of statistical concepts and methods. Harvard University Press. ISBN 978-0-674-83601-3.
- Hald, Anders (1998). A history of mathematical statistics from 1750 to 1930. New York, NY: Wiley. ISBN 978-0-471-17912-2.
- Hald, Anders (1999). "On the history of maximum likelihood in relation to inverse probability and least squares". Statistical Science. 14 (2): 214–222. doi:10.1214/ss/1009212248. JSTOR 2676741.
- Aldrich, John (1997). "R. A. Fisher and the making of maximum likelihood 1912–1922". Statistical Science. 12 (3): 162–176. doi:10.1214/ss/1030037906. MR 1617519.
Further reading
- Cramer, J. S. (1986). Econometric Applications of Maximum Likelihood Methods. New York: Cambridge University Press. ISBN 0-521-25317-9.
- Eliason, Scott R. (1993). Maximum Likelihood Estimation : Logic and Practice. Newbury Park: Sage. ISBN 0-8039-4107-2.
- King, Gary (1989). Unifying Political Methodology : the Likehood Theory of Statistical Inference. Cambridge University Press. ISBN 0-521-36697-6.
- Le Cam, Lucien (1990). "Maximum likelihood : An Introduction". ISI Review. 58 (2): 153–171. JSTOR 1403464.
- Magnus, Jan R. (2017). "Maximum Likelihood". Introduction to the Theory of Econometrics. Amsterdam: VU University Press. pp. 53–68. ISBN 978-90-8659-766-6.
- Millar, Russell B. (2011). Maximum Likelihood Estimation and Inference. Hoboken: Wiley. ISBN 978-0-470-09482-2.
- Pickles, Andrew (1986). An Introduction to Likelihood Analysis. Norwich: W. H. Hutchins & Sons. ISBN 0-86094-190-6.
- Severini, Thomas A. (2000). Likelihood Methods in Statistics. New York: Oxford University Press. ISBN 0-19-850650-3.
- Ward, Michael D.; Ahlquist, John S. (2018). Maximum Likelihood for Social Science : Strategies for Analysis. Cambridge University Press. ISBN 978-1-316-63682-4.
External links
- "Maximum-likelihood method", Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Purcell, S. "Maximum Likelihood Estimation".
- Sargent, Thomas; Stachurski, John. "Maximum Likelihood Estimation". Quantitative Economics with Python.
- Toomet, Ott; Henningsen, Arne (2019-05-19). "maxLik: A package for maximum likelihood estimation in R".