Glottal stop (letter)
The character ⟨ʔ⟩, called glottal stop, is an alphabetic letter in some Latin alphabets, most notable in several languages of Canada where it indicates a glottal stop sound. Such usage derives from phonetic transcription, for example the International Phonetic Alphabet (IPA), that use this letter for the glottal stop sound. The letter derives graphically from use of the apostrophe ⟨ʼ⟩ for glottal stop.
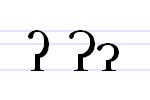
Graphic variants

Where ⟨ʔ⟩ is not available, not being in the basic Latin alphabet, it is sometimes replaced by a question mark ⟨?⟩, which is its official representation in the SAMPA transcription scheme. In Skwomesh or Squamish, ⟨ʔ⟩ may be replaced by the digit ⟨7⟩ (see image at right).
In Unicode, four graphic variants of the glottal stop letter are available.
- Unicase ⟨ʔ⟩ (U+0294 ʔ LATIN LETTER GLOTTAL STOP) is provided for the International Phonetic Alphabet and Americanist phonetic notation. It is found in a number of orthographies that use the IPA/APA symbol, such as those of several Salishan languages.
- A case pair, uppercase ⟨Ɂ⟩ (U+0241 Ɂ LATIN CAPITAL LETTER GLOTTAL STOP) and lowercase ⟨ɂ⟩ (U+0242 ɂ LATIN SMALL LETTER GLOTTAL STOP), is provided for the orthographies of several Athabaskan languages. Uppercase ⟨Ɂ⟩ may be slightly wider than unicase ⟨ʔ⟩ in fonts that distinguish them.
- Superscript ⟨ˀ⟩ (U+02C0 ˀ MODIFIER LETTER GLOTTAL STOP) that is used in the IPA and the Uralic Phonetic Alphabet.
Other common symbols for the glottal stop sound are variants of the punctuation mark apostrophe that was the historical basis of the glottal stop letters. These include the 9-shaped modifier letter apostrophe, ⟨ʼ⟩, which is probably the most common (and the direct ancestor of ⟨ʔ⟩), the 6-shaped ʻokina of Hawaiian, ⟨ʻ⟩, and the straight-apostrophe shaped saltillo of many languages of Mexico, which has the case forms ⟨Ꞌ ꞌ⟩.
Usage
Technical transcription
- Americanist phonetic notation and the International Phonetic Alphabet — unicase ʔ or superscript ˀ
- Transcription of Australian Aboriginal languages — occasionally unicase ʔ
- Uralic Phonetic Alphabet — superscript ˀ only
Vernacular orthographies
- Languages of Canada
- Chipewyan — uppercase Ɂ and lowercase ɂ
- Dogrib — uppercase Ɂ and lowercase ɂ
- Kootenai — unicase ʔ
- Musqueam language — unicase ʔ
- Nootka — unicase ʔ
- Slavey — uppercase Ɂ and lowercase ɂ
- Nitinaht — unicase ʔ
- Thompson — unicase ʔ
- Lushootseed — unicase ʔ
- Squamish language, where it is sometimes represented with ⟨7⟩.
Computing codes
In Unicode 1.0, only the unicase and superscript variants were included. In version 4.1 (2005), an uppercase character was added, and the existing unicase character was redefined as its lowercase. Then, in version 5.0 (2006), it was decided to separate the cased and caseless usages by adding a dedicated lowercase letter. The IPA character is first from left, while the extended Latin alphabet characters are third and fourth from left.[1]
| Character | ʔ | ˀ | Ɂ | ɂ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | LATIN LETTER GLOTTAL STOP | MODIFIER LETTER GLOTTAL STOP | LATIN CAPITAL LETTER GLOTTAL STOP | LATIN SMALL LETTER GLOTTAL STOP | ||||
| Character encoding | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 660 | 0294 | 704 | 02C0 | 577 | 0241 | 578 | 0242 |
| UTF-8 | 202 148 | CA 94 | 203 128 | CB 80 | 201 129 | C9 81 | 201 130 | C9 82 |
| Numeric character reference | ʔ | ʔ | ˀ | ˀ | Ɂ | Ɂ | ɂ | ɂ |
See also
- Glottal stop#Writing
- ʾ (Modifier letter right half ring)
- ʕ (Voiced pharyngeal fricative in IPA)
- ʡ (Epiglottal stop in IPA)
- ʢ (Voiced epiglottal trill in IPA)
- ʖ and ƾ (Obsolete and nonstandard symbols in the International Phonetic Alphabet)
- ˤ (Pharyngealization in IPA)
- ʻOkina
- Aleph
- Apostrophe
- Hamza
- Saltillo (letter)
- Sokuon
- Spiritus lenis
References
- "Proposal to add LATIN SMALL LETTER GLOTTAL STOP to the UCS" (PDF). 2005-08-10. Retrieved 2013-11-04.
| Wikimedia Commons has media related to Glottal stop letters. |