Regular expression
A regular expression (shortened as regex or regexp;[1] also referred to as rational expression)[2][3] is a sequence of characters that define a search pattern. Usually such patterns are used by string-searching algorithms for "find" or "find and replace" operations on strings, or for input validation. It is a technique developed in theoretical computer science and formal language theory.

(?<=\.) {2,}(?=[A-Z])

The concept arose in the 1950s when the American mathematician Stephen Cole Kleene formalized the description of a regular language. The concept came into common use with Unix text-processing utilities. Different syntaxes for writing regular expressions have existed since the 1980s, one being the POSIX standard and another, widely used, being the Perl syntax.
Regular expressions are used in search engines, search and replace dialogs of word processors and text editors, in text processing utilities such as sed and AWK and in lexical analysis. Many programming languages provide regex capabilities either built-in or via libraries.
Patterns
The phrase regular expressions, also called regexes, is often used to mean the specific, standard textual syntax for representing patterns for matching text, as distinct from the mathematical notation described below. Each character in a regular expression (that is, each character in the string describing its pattern) is either a metacharacter, having a special meaning, or a regular character that has a literal meaning. For example, in the regex a., a is a literal character which matches just 'a', while '.' is a metacharacter that matches every character except a newline. Therefore, this regex matches, for example, 'a ', or 'ax', or 'a0'. Together, metacharacters and literal characters can be used to identify text of a given pattern, or process a number of instances of it. Pattern matches may vary from a precise equality to a very general similarity, as controlled by the metacharacters. For example, . is a very general pattern, [a-z] (match all lower case letters from 'a' to 'z') is less general and a is a precise pattern (matches just 'a'). The metacharacter syntax is designed specifically to represent prescribed targets in a concise and flexible way to direct the automation of text processing of a variety of input data, in a form easy to type using a standard ASCII keyboard.
A very simple case of a regular expression in this syntax is to locate a word spelled two different ways in a text editor, the regular expression seriali[sz]e matches both "serialise" and "serialize". Wildcards also achieve this, but are more limited in what they can pattern, as they have fewer metacharacters and a simple language-base.
The usual context of wildcard characters is in globbing similar names in a list of files, whereas regexes are usually employed in applications that pattern-match text strings in general. For example, the regex ^[ \t]+|[ \t]+$ matches excess whitespace at the beginning or end of a line. An advanced regular expression that matches any numeral is [+-]?(\d+(\.\d+)?|\.\d+)([eE][+-]?\d+)?.
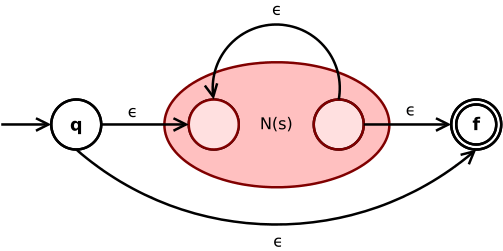
(s* means 'zero or more of s ')
A regex processor translates a regular expression in the above syntax into an internal representation which can be executed and matched against a string representing the text being searched in. One possible approach is the Thompson's construction algorithm to construct a nondeterministic finite automaton (NFA), which is then made deterministic and the resulting deterministic finite automaton (DFA) is run on the target text string to recognize substrings that match the regular expression.
The picture shows the NFA scheme N(s*) obtained from the regular expression s*, where s denotes a simpler regular expression in turn, which has already been recursively translated to the NFA N(s).
History
Regular expressions originated in 1951, when mathematician Stephen Cole Kleene described regular languages using his mathematical notation called regular events.[4][5] These arose in theoretical computer science, in the subfields of automata theory (models of computation) and the description and classification of formal languages. Other early implementations of pattern matching include the SNOBOL language, which did not use regular expressions, but instead its own pattern matching constructs.
Regular expressions entered popular use from 1968 in two uses: pattern matching in a text editor[6] and lexical analysis in a compiler.[7] Among the first appearances of regular expressions in program form was when Ken Thompson built Kleene's notation into the editor QED as a means to match patterns in text files.[6][8][9][10] For speed, Thompson implemented regular expression matching by just-in-time compilation (JIT) to IBM 7094 code on the Compatible Time-Sharing System, an important early example of JIT compilation.[11] He later added this capability to the Unix editor ed, which eventually led to the popular search tool grep's use of regular expressions ("grep" is a word derived from the command for regular expression searching in the ed editor: g/re/p meaning "Global search for Regular Expression and Print matching lines"[12]). Around the same time when Thompson developed QED, a group of researchers including Douglas T. Ross implemented a tool based on regular expressions that is used for lexical analysis in compiler design.[7]
Many variations of these original forms of regular expressions were used in Unix[10] programs at Bell Labs in the 1970s, including vi, lex, sed, AWK, and expr, and in other programs such as Emacs. Regexes were subsequently adopted by a wide range of programs, with these early forms standardized in the POSIX.2 standard in 1992.
In the 1980s the more complicated regexes arose in Perl, which originally derived from a regex library written by Henry Spencer (1986), who later wrote an implementation of Advanced Regular Expressions for Tcl.[13] The Tcl library is a hybrid NFA/DFA implementation with improved performance characteristics. Software projects that have adopted Spencer's Tcl regular expression implementation include PostgreSQL.[14] Perl later expanded on Spencer's original library to add many new features.[15] Part of the effort in the design of Raku is to improve Perl's regex integration, and to increase their scope and capabilities to allow the definition of parsing expression grammars.[16] The result is a mini-language called Raku rules, which are used to define Raku grammar as well as provide a tool to programmers in the language. These rules maintain existing features of Perl 5.x regexes, but also allow BNF-style definition of a recursive descent parser via sub-rules.
The use of regexes in structured information standards for document and database modeling started in the 1960s and expanded in the 1980s when industry standards like ISO SGML (precursored by ANSI "GCA 101-1983") consolidated. The kernel of the structure specification language standards consists of regexes. Its use is evident in the DTD element group syntax.
Starting in 1997, Philip Hazel developed PCRE (Perl Compatible Regular Expressions), which attempts to closely mimic Perl's regex functionality and is used by many modern tools including PHP and Apache HTTP Server.
Today, regexes are widely supported in programming languages, text processing programs (particularly lexers), advanced text editors, and some other programs. Regex support is part of the standard library of many programming languages, including Java and Python, and is built into the syntax of others, including Perl and ECMAScript. Implementations of regex functionality is often called a regex engine, and a number of libraries are available for reuse. In the late 2010s, several companies started to offer hardware, FPGA,[17] GPU[18] implementations of PCRE compatible regex engines that are faster compared to CPU implementations.
Basic concepts
A regular expression, often called a pattern, specifies a set of strings required for a particular purpose. A simple way to specify a finite set of strings is to list its elements or members. However, there are often more concise ways: for example, the set containing the three strings "Handel", "Händel", and "Haendel" can be specified by the pattern H(ä|ae?)ndel; we say that this pattern matches each of the three strings. In most formalisms, if there exists at least one regular expression that matches a particular set then there exists an infinite number of other regular expressions that also match it—the specification is not unique. Most formalisms provide the following operations to construct regular expressions.
- Boolean "or"
- A vertical bar separates alternatives. For example,
gray|greycan match "gray" or "grey". - Grouping
- Parentheses are used to define the scope and precedence of the operators (among other uses). For example,
gray|greyandgr(a|e)yare equivalent patterns which both describe the set of "gray" or "grey". - Quantification
- A quantifier after a token (such as a character) or group specifies how often that a preceding element is allowed to occur. The most common quantifiers are the question mark
?, the asterisk*(derived from the Kleene star), and the plus sign+(Kleene plus). ?The question mark indicates zero or one occurrences of the preceding element. For example, colou?rmatches both "color" and "colour".*The asterisk indicates zero or more occurrences of the preceding element. For example, ab*cmatches "ac", "abc", "abbc", "abbbc", and so on.+The plus sign indicates one or more occurrences of the preceding element. For example, ab+cmatches "abc", "abbc", "abbbc", and so on, but not "ac".{n}[19]The preceding item is matched exactly n times. {min,}[19]The preceding item is matched min or more times. {min,max}[19]The preceding item is matched at least min times, but not more than max times. - Wildcard
The wildcard . matches any character. For example, a.b matches any string that contains an "a", then any other character and then "b", a.*b matches any string that contains an "a", and then the character "b" at some later point.
These constructions can be combined to form arbitrarily complex expressions, much like one can construct arithmetical expressions from numbers and the operations +, −, ×, and ÷. For example, H(ae?|ä)ndel and H(a|ae|ä)ndel are both valid patterns which match the same strings as the earlier example, H(ä|ae?)ndel.
The precise syntax for regular expressions varies among tools and with context; more detail is given in § Syntax.
Formal language theory
Regular expressions describe regular languages in formal language theory. They have the same expressive power as regular grammars.
Formal definition
Regular expressions consist of constants, which denote sets of strings, and operator symbols, which denote operations over these sets. The following definition is standard, and found as such in most textbooks on formal language theory.[20][21] Given a finite alphabet Σ, the following constants are defined as regular expressions:
- (empty set) ∅ denoting the set ∅.
- (empty string) ε denoting the set containing only the "empty" string, which has no characters at all.
- (literal character)
ain Σ denoting the set containing only the character a.
Given regular expressions R and S, the following operations over them are defined to produce regular expressions:
- (concatenation) RS denotes the set of strings that can be obtained by concatenating a string in R and a string in S. For example, let R = {"ab", "c"}, and S = {"d", "ef"}. Then, RS = {"abd", "abef", "cd", "cef"}.
- (alternation) R | S denotes the set union of sets described by R and S. For example, if R describes {"ab", "c"} and S describes {"ab", "d", "ef"}, expression R | S describes {"ab", "c", "d", "ef"}.
- (Kleene star) R* denotes the smallest superset of the set described by R that contains ε and is closed under string concatenation. This is the set of all strings that can be made by concatenating any finite number (including zero) of strings from the set described by R. For example, {"0","1"}* is the set of all finite binary strings (including the empty string), and {"ab", "c"}* = {ε, "ab", "c", "abab", "abc", "cab", "cc", "ababab", "abcab", ... }.
To avoid parentheses it is assumed that the Kleene star has the highest priority, then concatenation and then alternation. If there is no ambiguity then parentheses may be omitted. For example, (ab)c can be written as abc, and a|(b(c*)) can be written as a|bc*.
Many textbooks use the symbols ∪, +, or ∨ for alternation instead of the vertical bar.
Examples:
a|b*denotes {ε, "a", "b", "bb", "bbb", ...}(a|b)*denotes the set of all strings with no symbols other than "a" and "b", including the empty string: {ε, "a", "b", "aa", "ab", "ba", "bb", "aaa", ...}ab*(c|ε)denotes the set of strings starting with "a", then zero or more "b"s and finally optionally a "c": {"a", "ac", "ab", "abc", "abb", "abbc", ...}(0|(1(01*0)*1))*denotes the set of binary numbers that are multiples of 3: { ε, "0", "00", "11", "000", "011", "110", "0000", "0011", "0110", "1001", "1100", "1111", "00000", ... }
Expressive power and compactness
The formal definition of regular expressions is minimal on purpose, and avoids defining ? and +—these can be expressed as follows: a+ = aa*, and a? = (a|ε). Sometimes the complement operator is added, to give a generalized regular expression; here Rc matches all strings over Σ* that do not match R. In principle, the complement operator is redundant, because it doesn't grant any more expressive power. However, it can make a regular expression much more concise—eliminating all complement operators from a regular expression can cause a double exponential blow-up of its length.[22][23]
Regular expressions in this sense can express the regular languages, exactly the class of languages accepted by deterministic finite automata. There is, however, a significant difference in compactness. Some classes of regular languages can only be described by deterministic finite automata whose size grows exponentially in the size of the shortest equivalent regular expressions. The standard example here is the languages Lk consisting of all strings over the alphabet {a,b} whose kth-from-last letter equals a. On one hand, a regular expression describing L4 is given by .

Generalizing this pattern to Lk gives the expression:

On the other hand, it is known that every deterministic finite automaton accepting the language Lk must have at least 2k states. Luckily, there is a simple mapping from regular expressions to the more general nondeterministic finite automata (NFAs) that does not lead to such a blowup in size; for this reason NFAs are often used as alternative representations of regular languages. NFAs are a simple variation of the type-3 grammars of the Chomsky hierarchy.[20]
In the opposite direction, there are many languages easily described by a DFA that are not easily described a regular expression. For instance, determining the validity of a given ISBN requires computing the modulus of the integer base 11, and can be easily implemented with an 11-state DFA. However, a regular expression to answer the same problem of divisibility by 11 is at least multiple megabytes in length.
Given a regular expression, Thompson's construction algorithm computes an equivalent nondeterministic finite automaton. A conversion in the opposite direction is achieved by Kleene's algorithm.
Finally, it is worth noting that many real-world "regular expression" engines implement features that cannot be described by the regular expressions in the sense of formal language theory; rather, they implement regexes. See below for more on this.
Deciding equivalence of regular expressions
As seen in many of the examples above, there is more than one way to construct a regular expression to achieve the same results.
It is possible to write an algorithm that, for two given regular expressions, decides whether the described languages are equal; the algorithm reduces each expression to a minimal deterministic finite state machine, and determines whether they are isomorphic (equivalent).
Algebraic laws for regular expressions can be obtained using a method by Gischer which is best explained along an example: In order to check whether (X+Y)* and (X* Y*)* denote the same regular language, for all regular expressions X, Y, it is necessary and sufficient to check whether the particular regular expressions (a+b)* and (a* b*)* denote the same language over the alphabet Σ={a,b}. More generally, an equation E=F between regular-expression terms with variables holds if, and only if, its instantiation with different variables replaced by different symbol constants holds.[24][25]
The redundancy can be eliminated by using Kleene star and set union to find an interesting subset of regular expressions that is still fully expressive, but perhaps their use can be restricted. This is a surprisingly difficult problem. As simple as the regular expressions are, there is no method to systematically rewrite them to some normal form. The lack of axiom in the past led to the star height problem. In 1991, Dexter Kozen axiomatized regular expressions as a Kleene algebra, using equational and Horn clause axioms.[26] Already in 1964, Redko had proved that no finite set of purely equational axioms can characterize the algebra of regular languages.[27]
Syntax
A regex pattern matches a target string. The pattern is composed of a sequence of atoms. An atom is a single point within the regex pattern which it tries to match to the target string. The simplest atom is a literal, but grouping parts of the pattern to match an atom will require using ( ) as metacharacters. Metacharacters help form: atoms; quantifiers telling how many atoms (and whether it is a greedy quantifier or not); a logical OR character, which offers a set of alternatives, and a logical NOT character, which negates an atom's existence; and backreferences to refer to previous atoms of a completing pattern of atoms. A match is made, not when all the atoms of the string are matched, but rather when all the pattern atoms in the regex have matched. The idea is to make a small pattern of characters stand for a large number of possible strings, rather than compiling a large list of all the literal possibilities.
Depending on the regex processor there are about fourteen metacharacters, characters that may or may not have their literal character meaning, depending on context, or whether they are "escaped", i.e. preceded by an escape sequence, in this case, the backslash \. Modern and POSIX extended regexes use metacharacters more often than their literal meaning, so to avoid "backslash-osis" or leaning toothpick syndrome it makes sense to have a metacharacter escape to a literal mode; but starting out, it makes more sense to have the four bracketing metacharacters ( ) and { } be primarily literal, and "escape" this usual meaning to become metacharacters. Common standards implement both. The usual metacharacters are {}[]()^$.|*+? and \. The usual characters that become metacharacters when escaped are dswDSW and N.
Delimiters
When entering a regex in a programming language, they may be represented as a usual string literal, hence usually quoted; this is common in C, Java, and Python for instance, where the regex re is entered as "re". However, they are often written with slashes as delimiters, as in /re/ for the regex re. This originates in ed, where / is the editor command for searching, and an expression /re/ can be used to specify a range of lines (matching the pattern), which can be combined with other commands on either side, most famously g/re/p as in grep ("global regex print"), which is included in most Unix-based operating systems, such as Linux distributions. A similar convention is used in sed, where search and replace is given by s/re/replacement/ and patterns can be joined with a comma to specify a range of lines as in /re1/,/re2/. This notation is particularly well known due to its use in Perl, where it forms part of the syntax distinct from normal string literals. In some cases, such as sed and Perl, alternative delimiters can be used to avoid collision with contents, and to avoid having to escape occurrences of the delimiter character in the contents. For example, in sed the command s,/,X, will replace a / with an X, using commas as delimiters.
Standards
The IEEE POSIX standard has three sets of compliance: BRE (Basic Regular Expressions),[28] ERE (Extended Regular Expressions), and SRE (Simple Regular Expressions). SRE is deprecated,[29] in favor of BRE, as both provide backward compatibility. The subsection below covering the character classes applies to both BRE and ERE.
BRE and ERE work together. ERE adds ?, +, and |, and it removes the need to escape the metacharacters ( ) and { }, which are required in BRE. Furthermore, as long as the POSIX standard syntax for regexes is adhered to, there can be, and often is, additional syntax to serve specific (yet POSIX compliant) applications. Although POSIX.2 leaves some implementation specifics undefined, BRE and ERE provide a "standard" which has since been adopted as the default syntax of many tools, where the choice of BRE or ERE modes is usually a supported option. For example, GNU grep has the following options: "grep -E" for ERE, and "grep -G" for BRE (the default), and "grep -P" for Perl regexes.
Perl regexes have become a de facto standard, having a rich and powerful set of atomic expressions. Perl has no "basic" or "extended" levels. As in POSIX EREs, ( ) and { } are treated as metacharacters unless escaped; other metacharacters are known to be literal or symbolic based on context alone. Additional functionality includes lazy matching, backreferences, named capture groups, and recursive patterns.
POSIX basic and extended
In the POSIX standard, Basic Regular Syntax (BRE) requires that the metacharacters ( ) and { } be designated \(\) and \{\}, whereas Extended Regular Syntax (ERE) does not.
| Metacharacter | Description |
|---|---|
^ |
Matches the starting position within the string. In line-based tools, it matches the starting position of any line. |
. |
Matches any single character (many applications exclude newlines, and exactly which characters are considered newlines is flavor-, character-encoding-, and platform-specific, but it is safe to assume that the line feed character is included). Within POSIX bracket expressions, the dot character matches a literal dot. For example, a.c matches "abc", etc., but [a.c] matches only "a", ".", or "c". |
[ ] |
A bracket expression. Matches a single character that is contained within the brackets. For example, [abc] matches "a", "b", or "c". [a-z] specifies a range which matches any lowercase letter from "a" to "z". These forms can be mixed: [abcx-z] matches "a", "b", "c", "x", "y", or "z", as does [a-cx-z].
The |
[^ ] |
Matches a single character that is not contained within the brackets. For example, [^abc] matches any character other than "a", "b", or "c". [^a-z] matches any single character that is not a lowercase letter from "a" to "z". Likewise, literal characters and ranges can be mixed. |
$ |
Matches the ending position of the string or the position just before a string-ending newline. In line-based tools, it matches the ending position of any line. |
( ) |
Defines a marked subexpression. The string matched within the parentheses can be recalled later (see the next entry, \n). A marked subexpression is also called a block or capturing group. BRE mode requires \( \). |
\n |
Matches what the nth marked subexpression matched, where n is a digit from 1 to 9. This construct is vaguely defined in the POSIX.2 standard. Some tools allow referencing more than nine capturing groups. Also known as a backreference. |
* |
Matches the preceding element zero or more times. For example, ab*c matches "ac", "abc", "abbbc", etc. [xyz]* matches "", "x", "y", "z", "zx", "zyx", "xyzzy", and so on. (ab)* matches "", "ab", "abab", "ababab", and so on. |
{m,n} |
Matches the preceding element at least m and not more than n times. For example, a{3,5} matches only "aaa", "aaaa", and "aaaaa". This is not found in a few older instances of regexes. BRE mode requires \{m,n\}. |
Examples:
.atmatches any three-character string ending with "at", including "hat", "cat", and "bat".[hc]atmatches "hat" and "cat".[^b]atmatches all strings matched by.atexcept "bat".[^hc]atmatches all strings matched by.atother than "hat" and "cat".^[hc]atmatches "hat" and "cat", but only at the beginning of the string or line.[hc]at$matches "hat" and "cat", but only at the end of the string or line.\[.\]matches any single character surrounded by "[" and "]" since the brackets are escaped, for example: "[a]" and "[b]".s.*matches s followed by zero or more characters, for example: "s" and "saw" and "seed".
POSIX extended
The meaning of metacharacters escaped with a backslash is reversed for some characters in the POSIX Extended Regular Expression (ERE) syntax. With this syntax, a backslash causes the metacharacter to be treated as a literal character. So, for example, \( \) is now ( ) and \{ \} is now { }. Additionally, support is removed for \n backreferences and the following metacharacters are added:
| Metacharacter | Description |
|---|---|
? |
Matches the preceding element zero or one time. For example, ab?c matches only "ac" or "abc". |
+ |
Matches the preceding element one or more times. For example, ab+c matches "abc", "abbc", "abbbc", and so on, but not "ac". |
| |
The choice (also known as alternation or set union) operator matches either the expression before or the expression after the operator. For example, abc|def matches "abc" or "def". |
Examples:
[hc]?atmatches "at", "hat", and "cat".[hc]*atmatches "at", "hat", "cat", "hhat", "chat", "hcat", "cchchat", and so on.[hc]+atmatches "hat", "cat", "hhat", "chat", "hcat", "cchchat", and so on, but not "at".cat|dogmatches "cat" or "dog".
POSIX Extended Regular Expressions can often be used with modern Unix utilities by including the command line flag -E.
Character classes
The character class is the most basic regex concept after a literal match. It makes one small sequence of characters match a larger set of characters. For example, [A-Z] could stand for the uppercase alphabet in the English language, and \d could mean any digit. Character classes apply to both POSIX levels.
When specifying a range of characters, such as [a-Z] (i.e. lowercase a to uppercase Z), the computer's locale settings determine the contents by the numeric ordering of the character encoding. They could store digits in that sequence, or the ordering could be abc…zABC…Z, or aAbBcC…zZ. So the POSIX standard defines a character class, which will be known by the regex processor installed. Those definitions are in the following table:
| POSIX | Non-standard | Perl/Tcl | Vim | Java | ASCII | Description |
|---|---|---|---|---|---|---|
[:ascii:][30] |
\p{ASCII} |
[\x00-\x7F] |
ASCII characters | |||
[:alnum:] |
\p{Alnum} |
[A-Za-z0-9] |
Alphanumeric characters | |||
[:word:][30] |
\w |
\w |
\w |
[A-Za-z0-9_] |
Alphanumeric characters plus "_" | |
\W |
\W |
\W |
[^A-Za-z0-9_] |
Non-word characters | ||
[:alpha:] |
\a |
\p{Alpha} |
[A-Za-z] |
Alphabetic characters | ||
[:blank:] |
\s |
\p{Blank} |
[ \t] |
Space and tab | ||
\b |
\< \> |
\b |
(?<=\W)(?=\w)|(?<=\w)(?=\W) |
Word boundaries | ||
\B |
(?<=\W)(?=\W)|(?<=\w)(?=\w) |
Non-word boundaries | ||||
[:cntrl:] |
\p{Cntrl} |
[\x00-\x1F\x7F] |
Control characters | |||
[:digit:] |
\d |
\d |
\p{Digit} or \d |
[0-9] |
Digits | |
\D |
\D |
\D |
[^0-9] |
Non-digits | ||
[:graph:] |
\p{Graph} |
[\x21-\x7E] |
Visible characters | |||
[:lower:] |
\l |
\p{Lower} |
[a-z] |
Lowercase letters | ||
[:print:] |
\p |
\p{Print} |
[\x20-\x7E] |
Visible characters and the space character | ||
[:punct:] |
\p{Punct} |
[][!"#$%&'()*+,./:;<=>?@\^_`{|}~-] |
Punctuation characters | |||
[:space:] |
\s |
\_s |
\p{Space} or \s |
[ \t\r\n\v\f] |
Whitespace characters | |
\S |
\S |
\S |
[^ \t\r\n\v\f] |
Non-whitespace characters | ||
[:upper:] |
\u |
\p{Upper} |
[A-Z] |
Uppercase letters | ||
[:xdigit:] |
\x |
\p{XDigit} |
[A-Fa-f0-9] |
Hexadecimal digits |
POSIX character classes can only be used within bracket expressions. For example, [[:upper:]ab] matches the uppercase letters and lowercase "a" and "b".
An additional non-POSIX class understood by some tools is [:word:], which is usually defined as [:alnum:] plus underscore. This reflects the fact that in many programming languages these are the characters that may be used in identifiers. The editor Vim further distinguishes word and word-head classes (using the notation \w and \h) since in many programming languages the characters that can begin an identifier are not the same as those that can occur in other positions: numbers are generally excluded, so an identifier would look like \h\w* or [[:alpha:]_][[:alnum:]_]* in POSIX notation.
Note that what the POSIX regex standards call character classes are commonly referred to as POSIX character classes in other regex flavors which support them. With most other regex flavors, the term character class is used to describe what POSIX calls bracket expressions.
Perl and PCRE
Because of its expressive power and (relative) ease of reading, many other utilities and programming languages have adopted syntax similar to Perl's — for example, Java, JavaScript, Julia, Python, Ruby, Qt, Microsoft's .NET Framework, and XML Schema. Some languages and tools such as Boost and PHP support multiple regex flavors. Perl-derivative regex implementations are not identical and usually implement a subset of features found in Perl 5.0, released in 1994. Perl sometimes does incorporate features initially found in other languages. For example, Perl 5.10 implements syntactic extensions originally developed in PCRE and Python.[31]
Lazy matching
In Python and some other implementations (e.g. Java), the three common quantifiers (*, + and ?) are greedy by default because they match as many characters as possible.[32] The regex ".+" (including the double-quotes) applied to the string
"Ganymede," he continued, "is the largest moon in the Solar System."
matches the entire line (because the entire line begins and ends with a double-quote) instead of matching only the first part, "Ganymede,". The aforementioned quantifiers may, however, be made lazy or minimal or reluctant, matching as few characters as possible, by appending a question mark: ".+?" matches only "Ganymede,".[32]
However, the whole sentence can still be matched in some circumstances. The question-mark operator does not change the meaning of the dot operator, so this still can match the double-quotes in the input. A pattern like ".*?" EOF will still match the whole input if this is the string:
"Ganymede," he continued, "is the largest moon in the Solar System." EOF
To ensure that the double-quotes cannot be part of the match, the dot has to be replaced (e.g. "[^"]*"). This will match a quoted text part without additional double-quotes in it. (By removing possibilities for a fixed suffix to be matched, one also transforms the lazy-match to a greedy-match.)
Possessive matching
In Java, quantifiers may be made possessive by appending a plus sign, which disables backing off (in a backtracking engine), even if doing so would allow the overall match to succeed:[33] While the regex ".*" applied to the string
"Ganymede," he continued, "is the largest moon in the Solar System."
matches the entire line, the regex ".*+" does not match at all, because .*+ consumes the entire input, including the final ". Thus, possessive quantifiers are most useful with negated character classes, e.g. "[^"]*+", which matches "Ganymede," when applied to the same string.
Another common extension serving the same function is atomic grouping, which disables backtracking for a parenthesized group. The typical syntax is (?>group). For example, while ^(wi|w)i$ matches both wi and wii, ^(?>wi|w)i$ only matches wii because the engine is forbidden from backtracking and try with setting the group as "w".[34]
Possessive quantifiers are easier to implement than greedy and lazy quantifiers, and are typically more efficient at runtime.[33]
Patterns for non-regular languages
Many features found in virtually all modern regular expression libraries provide an expressive power that exceeds the regular languages. For example, many implementations allow grouping subexpressions with parentheses and recalling the value they match in the same expression (backreferences). This means that, among other things, a pattern can match strings of repeated words like "papa" or "WikiWiki", called squares in formal language theory. The pattern for these strings is (.+)\1.
The language of squares is not regular, nor is it context-free, due to the pumping lemma. However, pattern matching with an unbounded number of backreferences, as supported by numerous modern tools, is still context sensitive.[35] The general problem of matching any number of backreferences is NP-complete, growing exponentially by the number of backref groups used.[36]
However, many tools, libraries, and engines that provide such constructions still use the term regular expression for their patterns. This has led to a nomenclature where the term regular expression has different meanings in formal language theory and pattern matching. For this reason, some people have taken to using the term regex, regexp, or simply pattern to describe the latter. Larry Wall, author of the Perl programming language, writes in an essay about the design of Raku:
"Regular expressions" […] are only marginally related to real regular expressions. Nevertheless, the term has grown with the capabilities of our pattern matching engines, so I'm not going to try to fight linguistic necessity here. I will, however, generally call them "regexes" (or "regexen", when I'm in an Anglo-Saxon mood).[16]
| Assertion | Lookbehind | Lookahead |
|---|---|---|
| Positive | (?<=pattern) | (?=pattern) |
| Negative | (?<!pattern) | (?!pattern) |
| Look-behind and look-ahead assertions in Perl regular expressions | ||
Other features not found in describing regular languages include assertions. These include the ubiquitous ^ and $, as well as some more sophiscated extensions like lookaround. They define the surrounding of a match and don't spill into the match itself, a feature only relevant for the use-case of string searching. Some of them can be simulated in a regular language by treating the surroundings as a part of the language as well.[37]
Implementations and running times
There are at least three different algorithms that decide whether and how a given regex matches a string.
The oldest and fastest relies on a result in formal language theory that allows every nondeterministic finite automaton (NFA) to be transformed into a deterministic finite automaton (DFA). The DFA can be constructed explicitly and then run on the resulting input string one symbol at a time. Constructing the DFA for a regular expression of size m has the time and memory cost of O(2m), but it can be run on a string of size n in time O(n). Note that the size of the expression is the size after abbreviations, such as numeric quantifiers, have been expanded.
An alternative approach is to simulate the NFA directly, essentially building each DFA state on demand and then discarding it at the next step. This keeps the DFA implicit and avoids the exponential construction cost, but running cost rises to O(mn). The explicit approach is called the DFA algorithm and the implicit approach the NFA algorithm. Adding caching to the NFA algorithm is often called the "lazy DFA" algorithm, or just the DFA algorithm without making a distinction. These algorithms are fast, but using them for recalling grouped subexpressions, lazy quantification, and similar features is tricky.[38][39] Modern implementations include the re1-re2-sregex family based on Cox's code.
The third algorithm is to match the pattern against the input string by backtracking. This algorithm is commonly called NFA, but this terminology can be confusing. Its running time can be exponential, which simple implementations exhibit when matching against expressions like (a|aa)*b that contain both alternation and unbounded quantification and force the algorithm to consider an exponentially increasing number of sub-cases. This behavior can cause a security problem called Regular expression Denial of Service (ReDoS).
Although backtracking implementations only give an exponential guarantee in the worst case, they provide much greater flexibility and expressive power. For example, any implementation which allows the use of backreferences, or implements the various extensions introduced by Perl, must include some kind of backtracking. Some implementations try to provide the best of both algorithms by first running a fast DFA algorithm, and revert to a potentially slower backtracking algorithm only when a backreference is encountered during the match. GNU grep (and the underlying gnulib DFA) uses such a strategy.[40]
Sublinear runtime algorithms have been achieved using Boyer-Moore (BM) based algorithms and related DFA optimization techniques such as the reverse scan.[41] GNU grep, which supports a wide variety of POSIX syntaxes and extensions, uses BM for a first-pass prefiltering, and then uses an implicit DFA. Wu agrep, which implements approximate matching, combines the prefiltering into the DFA in BDM (backward DAWG matching). NR-grep's BNDM extends the BDM technique with Shift-Or bit-level parallelism.[42]
A few theoretical alternatives to backtracking for backreferences exist, and their "exponents" are tamer in that they are only related to the number of backreferences, a fixed property of some regexp languages such as POSIX. One naive method that duplicates a non-backtracking NFA for each backreference note has a complexity of time and space for a haystack of length n and k backreferences in the RegExp.[43] A very recent theoretical work based on memory automata gives a tighter bound based on "active" variable nodes used, and a polynomial possibility for some backreferenced regexps.[44]


Unicode
In theoretical terms, any token set can be matched by regular expressions as long as it is pre-defined. In terms of historical implementations, regexes were originally written to use ASCII characters as their token set though regex libraries have supported numerous other character sets. Many modern regex engines offer at least some support for Unicode. In most respects it makes no difference what the character set is, but some issues do arise when extending regexes to support Unicode.
- Supported encoding. Some regex libraries expect to work on some particular encoding instead of on abstract Unicode characters. Many of these require the UTF-8 encoding, while others might expect UTF-16, or UTF-32. In contrast, Perl and Java are agnostic on encodings, instead operating on decoded characters internally.
- Supported Unicode range. Many regex engines support only the Basic Multilingual Plane, that is, the characters which can be encoded with only 16 bits. Currently (as of 2016) only a few regex engines (e.g., Perl's and Java's) can handle the full 21-bit Unicode range.
- Extending ASCII-oriented constructs to Unicode. For example, in ASCII-based implementations, character ranges of the form
[x-y]are valid wherever x and y have code points in the range [0x00,0x7F] and codepoint(x) ≤ codepoint(y). The natural extension of such character ranges to Unicode would simply change the requirement that the endpoints lie in [0x00,0x7F] to the requirement that they lie in [0x0000,0x10FFFF]. However, in practice this is often not the case. Some implementations, such as that of gawk, do not allow character ranges to cross Unicode blocks. A range like [0x61,0x7F] is valid since both endpoints fall within the Basic Latin block, as is [0x0530,0x0560] since both endpoints fall within the Armenian block, but a range like [0x0061,0x0532] is invalid since it includes multiple Unicode blocks. Other engines, such as that of the Vim editor, allow block-crossing but the character values must not be more than 256 apart.[45] - Case insensitivity. Some case-insensitivity flags affect only the ASCII characters. Other flags affect all characters. Some engines have two different flags, one for ASCII, the other for Unicode. Exactly which characters belong to the POSIX classes also varies.
- Cousins of case insensitivity. As ASCII has case distinction, case insensitivity became a logical feature in text searching. Unicode introduced alphabetic scripts without case like Devanagari. For these, case sensitivity is not applicable. For scripts like Chinese, another distinction seems logical: between traditional and simplified. In Arabic scripts, insensitivity to initial, medial, final, and isolated position may be desired. In Japanese, insensitivity between hiragana and katakana is sometimes useful.
- Normalization. Unicode has combining characters. Like old typewriters, plain letters can be followed by one or more non-spacing symbols (usually diacritics like accent marks) to form a single printing character, but also provides precomposed characters, i.e. characters that already include one or more combining characters. A sequence of a character + combining character should be matched with the identical single precomposed character. The process of standardizing sequences of characters + combining characters is called normalization.
- New control codes. Unicode introduced amongst others, byte order marks and text direction markers. These codes might have to be dealt with in a special way.
- Introduction of character classes for Unicode blocks, scripts, and numerous other character properties. Block properties are much less useful than script properties, because a block can have code points from several different scripts, and a script can have code points from several different blocks.[46] In Perl and the
java.util.regexlibrary, properties of the form\p{InX}or\p{Block=X}match characters in block X and\P{InX}or\P{Block=X}matches code points not in that block. Similarly,\p{Armenian},\p{IsArmenian}, or\p{Script=Armenian}matches any character in the Armenian script. In general,\p{X}matches any character with either the binary property X or the general category X. For example,\p{Lu},\p{Uppercase_Letter}, or\p{GC=Lu}matches any uppercase letter. Binary properties that are not general categories include\p{White_Space},\p{Alphabetic},\p{Math}, and\p{Dash}. Examples of non-binary properties are\p{Bidi_Class=Right_to_Left},\p{Word_Break=A_Letter}, and\p{Numeric_Value=10}.
Uses
Regexes are useful in a wide variety of text processing tasks, and more generally string processing, where the data need not be textual. Common applications include data validation, data scraping (especially web scraping), data wrangling, simple parsing, the production of syntax highlighting systems, and many other tasks.
While regexes would be useful on Internet search engines, processing them across the entire database could consume excessive computer resources depending on the complexity and design of the regex. Although in many cases system administrators can run regex-based queries internally, most search engines do not offer regex support to the public. Notable exceptions: Google Code Search, Exalead. Google Code Search has been shut down as of January 2012.[47] It used a trigram index to speed queries.[48]
Examples
The specific syntax rules vary depending on the specific implementation, programming language, or library in use. Additionally, the functionality of regex implementations can vary between versions.
Because regexes can be difficult to both explain and understand without examples, interactive websites for testing regexes are a useful resource for learning regexes by experimentation. This section provides a basic description of some of the properties of regexes by way of illustration.
The following conventions are used in the examples.[49]
metacharacter(s) ;; the metacharacters column specifies the regex syntax being demonstrated
=~ m// ;; indicates a regex match operation in Perl
=~ s/// ;; indicates a regex substitution operation in Perl
Also worth noting is that these regexes are all Perl-like syntax. Standard POSIX regular expressions are different.
Unless otherwise indicated, the following examples conform to the Perl programming language, release 5.8.8, January 31, 2006. This means that other implementations may lack support for some parts of the syntax shown here (e.g. basic vs. extended regex, \( \) vs. (), or lack of \d instead of POSIX [:digit:]).
The syntax and conventions used in these examples coincide with that of other programming environments as well.[50]
| Metacharacter(s) | Description | Example[51] |
|---|---|---|
. |
Normally matches any character except a newline. Within square brackets the dot is literal. |
$string1 = "Hello World\n";
if ($string1 =~ m/...../) {
print "$string1 has length >= 5.\n";
}
Output: Hello World
has length >= 5.
|
( ) |
Groups a series of pattern elements to a single element. When you match a pattern within parentheses, you can use any of $1, $2, ... later to refer to the previously matched pattern. |
$string1 = "Hello World\n";
if ($string1 =~ m/(H..).(o..)/) {
print "We matched '$1' and '$2'.\n";
}
Output: We matched 'Hel' and 'o W'.
|
+ |
Matches the preceding pattern element one or more times. | $string1 = "Hello World\n";
if ($string1 =~ m/l+/) {
print "There are one or more consecutive letter \"l\"'s in $string1.\n";
}
Output: There are one or more consecutive letter "l"'s in Hello World.
|
? |
Matches the preceding pattern element zero or one time. | $string1 = "Hello World\n";
if ($string1 =~ m/H.?e/) {
print "There is an 'H' and a 'e' separated by ";
print "0-1 characters (e.g., He Hue Hee).\n";
}
Output: There is an 'H' and a 'e' separated by 0-1 characters (e.g., He Hue Hee).
|
? |
Modifies the *, +, ? or {M,N}'d regex that comes before to match as few times as possible. |
$string1 = "Hello World\n";
if ($string1 =~ m/(l.+?o)/) {
print "The non-greedy match with 'l' followed by one or ";
print "more characters is 'llo' rather than 'llo Wo'.\n";
}
Output: The non-greedy match with 'l' followed by one or more characters is 'llo' rather than 'llo Wo'.
|
* |
Matches the preceding pattern element zero or more times. | $string1 = "Hello World\n";
if ($string1 =~ m/el*o/) {
print "There is an 'e' followed by zero to many ";
print "'l' followed by 'o' (e.g., eo, elo, ello, elllo).\n";
}
Output: There is an 'e' followed by zero to many 'l' followed by 'o' (e.g., eo, elo, ello, elllo).
|
{M,N} |
Denotes the minimum M and the maximum N match count. N can be omitted and M can be 0: {M} matches "exactly" M times; {M,} matches "at least" M times; {0,N} matches "at most" N times.x* y+ z? is thus equivalent to x{0,} y{1,} z{0,1}. |
$string1 = "Hello World\n";
if ($string1 =~ m/l{1,2}/) {
print "There exists a substring with at least 1 ";
print "and at most 2 l's in $string1\n";
}
Output: There exists a substring with at least 1 and at most 2 l's in Hello World
|
[…] |
Denotes a set of possible character matches. | $string1 = "Hello World\n";
if ($string1 =~ m/[aeiou]+/) {
print "$string1 contains one or more vowels.\n";
}
Output: Hello World
contains one or more vowels.
|
| |
Separates alternate possibilities. | $string1 = "Hello World\n";
if ($string1 =~ m/(Hello|Hi|Pogo)/) {
print "$string1 contains at least one of Hello, Hi, or Pogo.";
}
Output: Hello World
contains at least one of Hello, Hi, or Pogo.
|
\b |
Matches a zero-width boundary between a word-class character (see next) and either a non-word class character or an edge; same as
|
$string1 = "Hello World\n";
if ($string1 =~ m/llo\b/) {
print "There is a word that ends with 'llo'.\n";
}
Output: There is a word that ends with 'llo'.
|
\w |
Matches an alphanumeric character, including "_"; same as [A-Za-z0-9_] in ASCII, and
in Unicode,[46] where the |
$string1 = "Hello World\n";
if ($string1 =~ m/\w/) {
print "There is at least one alphanumeric ";
print "character in $string1 (A-Z, a-z, 0-9, _).\n";
}
Output: There is at least one alphanumeric character in Hello World
(A-Z, a-z, 0-9, _).
|
\W |
Matches a non-alphanumeric character, excluding "_"; same as [^A-Za-z0-9_] in ASCII, and
in Unicode. |
$string1 = "Hello World\n";
if ($string1 =~ m/\W/) {
print "The space between Hello and ";
print "World is not alphanumeric.\n";
}
Output: The space between Hello and World is not alphanumeric.
|
\s |
Matches a whitespace character, which in ASCII are tab, line feed, form feed, carriage return, and space; in Unicode, also matches no- |
$string1 = "Hello World\n";
if ($string1 =~ m/\s.*\s/) {
print "In $string1 there are TWO whitespace characters, which may";
print " be separated by other characters.\n";
}
Output: In Hello World
there are TWO whitespace characters, which may be separated by other characters.
|
\S |
Matches anything but a whitespace. | $string1 = "Hello World\n";
if ($string1 =~ m/\S.*\S/) {
print "In $string1 there are TWO non-whitespace characters, which";
print " may be separated by other characters.\n";
}
Output: In Hello World
there are TWO non-whitespace characters, which may be separated by other characters.
|
\d |
Matches a digit; same as [0-9] in ASCII; in Unicode, same as the \p{Digit} or \p{GC=Decimal_Number} property, which itself the same as the \p{Numeric_Type=Decimal} property. |
$string1 = "99 bottles of beer on the wall.";
if ($string1 =~ m/(\d+)/) {
print "$1 is the first number in '$string1'\n";
}
Output: 99 is the first number in '99 bottles of beer on the wall.'
|
\D |
Matches a non-digit; same as [^0-9] in ASCII or \P{Digit} in Unicode. |
$string1 = "Hello World\n";
if ($string1 =~ m/\D/) {
print "There is at least one character in $string1";
print " that is not a digit.\n";
}
Output: There is at least one character in Hello World
that is not a digit.
|
^ |
Matches the beginning of a line or string. | $string1 = "Hello World\n";
if ($string1 =~ m/^He/) {
print "$string1 starts with the characters 'He'.\n";
}
Output: Hello World
starts with the characters 'He'.
|
$ |
Matches the end of a line or string. | $string1 = "Hello World\n";
if ($string1 =~ m/rld$/) {
print "$string1 is a line or string ";
print "that ends with 'rld'.\n";
}
Output: Hello World
is a line or string that ends with 'rld'.
|
\A |
Matches the beginning of a string (but not an internal line). | $string1 = "Hello\nWorld\n";
if ($string1 =~ m/\AH/) {
print "$string1 is a string ";
print "that starts with 'H'.\n";
}
Output: Hello
World
is a string that starts with 'H'.
|
\z |
Matches the end of a string (but not an internal line).[52] | $string1 = "Hello\nWorld\n";
if ($string1 =~ m/d\n\z/) {
print "$string1 is a string ";
print "that ends with 'd\\n'.\n";
}
Output: Hello
World
is a string that ends with 'd\n'.
|
[^…] |
Matches every character except the ones inside brackets. | $string1 = "Hello World\n";
if ($string1 =~ m/[^abc]/) {
print "$string1 contains a character other than ";
print "a, b, and c.\n";
}
Output: Hello World
contains a character other than a, b, and c.
|
Induction
Regular expressions can often be created ("induced" or "learned") based on a set of example strings. This is known as the induction of regular languages, and is part of the general problem of grammar induction in computational learning theory. Formally, given examples of strings in a regular language, and perhaps also given examples of strings not in that regular language, it is possible to induce a grammar for the language, i.e., a regular expression that generates that language. Not all regular languages can be induced in this way (see language identification in the limit), but many can. For example, the set of examples {1, 10, 100}, and negative set (of counterexamples) {11, 1001, 101, 0} can be used to induce the regular expression 1⋅0* (1 followed by zero or more 0s).
See also
- Comparison of regular-expression engines
- Extended Backus–Naur form
- Matching wildcards
- Regular tree grammar
- Thompson's construction – converts a regular expression into an equivalent nondeterministic finite automaton (NFA)
Notes
- Goyvaerts, Jan. "Regular Expression Tutorial - Learn How to Use Regular Expressions". www.regular-expressions.info.
- Ruslan Mitkov (2003). The Oxford Handbook of Computational Linguistics. Oxford University Press. p. 754. ISBN 978-0-19-927634-9.
- Mark V. Lawson (17 September 2003). Finite Automata. CRC Press. pp. 98–100. ISBN 978-1-58488-255-8.
- Kleene 1951.
- Leung, Hing (16 September 2010). "Regular Languages and Finite Automata" (PDF). New Mexico State University. Archived from the original (pdf) on 5 December 2013. Retrieved 13 August 2019.
The concept of regular events was introduced by Kleene via the definition of regular expressions.
- Thompson 1968.
- Johnson et al. 1968.
- Kernighan, Brian (2007-08-08). "A Regular Expressions Matcher". Beautiful Code. O'Reilly Media. pp. 1–2. ISBN 978-0-596-51004-6. Retrieved 2013-05-15.
- Ritchie, Dennis M. "An incomplete history of the QED Text Editor". Archived from the original on 1999-02-21. Retrieved 9 October 2013.
- Aho & Ullman 1992, 10.11 Bibliographic Notes for Chapter 10, p. 589.
- Aycock 2003, 2. JIT Compilation Techniques, 2.1 Genesis, p. 98.
- Raymond, Eric S. citing Dennis Ritchie (2003). "Jargon File 4.4.7: grep".
- "New Regular Expression Features in Tcl 8.1". Retrieved 2013-10-11.
- "PostgreSQL 9.3.1 Documentation: 9.7. Pattern Matching". Retrieved 2013-10-12.
- Wall, Larry and the Perl 5 development team (2006). "perlre: Perl regular expressions".
- Wall (2002)
- "GROVF | Big Data Analytics Acceleration". grovf.com. Retrieved 2019-10-22.
- "CUDA grep". bkase.github.io. Retrieved 2019-10-22.
- grep(1) man page
- Hopcroft, Motwani & Ullman (2000)
- Sipser (1998)
- Gelade & Neven (2008)
- Gruber & Holzer (2008)
- Jay L. Gischer (1984). (Title unknown) (Technical Report). Stanford Univ., Dept. of Comp. Sc.
- John E. Hopcroft and Rajeev Motwani and Jeffrey D. Ullman (2003). Introduction to Automata Theory, Languages, and Computation. Upper Saddle River/NJ: Addison Wesley. ISBN 978-0-201-44124-6. Here: Sect.3.4.6, p.117-120. — This property need not hold for extended regular expressions, even if they describe no larger class than regular languages; cf. p.121.
- Kozen (1991)
- V.N. Redko (1964). "On defining relations for the algebra of regular events". Ukrainskii Matematicheskii Zhurnal. 16 (1): 120–126. (In Russian)
- ISO/IEC 9945-2:1993 Information technology – Portable Operating System Interface (POSIX) – Part 2: Shell and Utilities, successively revised as ISO/IEC 9945-2:2002 Information technology – Portable Operating System Interface (POSIX) – Part 2: System Interfaces, ISO/IEC 9945-2:2003, and currently ISO/IEC/IEEE 9945:2009 Information technology – Portable Operating System Interface (POSIX®) Base Specifications, Issue 7
- The Single Unix Specification (Version 2)
- "33.3.1.2 Character Classes — Emacs lisp manual — Version 25.1". gnu.org. 2016. Retrieved 2017-04-13.
- "Perl Regular Expression Documentation". perldoc.perl.org. Retrieved January 8, 2012.
- "Regular Expression Syntax". Python 3.5.0 documentation. Python Software Foundation. Retrieved 10 October 2015.
- "Essential classes: Regular Expressions: Quantifiers: Differences Among Greedy, Reluctant, and Possessive Quantifiers". The Java Tutorials. Oracle. Retrieved 23 December 2016.
- "Atomic Grouping". Regex Tutorial. Retrieved 24 November 2019.
- Cezar Câmpeanu and Kai Salomaa, and Sheng Yu (Dec 2003). "A Formal Study of Practical Regular Expressions". International Journal of Foundations of Computer Science. 14 (6): 1007–1018. doi:10.1142/S012905410300214X. Theorem 3 (p.9)
- "Perl Regular Expression Matching is NP-Hard". perl.plover.com.
- Wandering Logic. "How to simulate lookaheads and lookbehinds in finite state automata?". Computer Science Stack Exchange. Retrieved 24 November 2019.
- Cox (2007)
- Laurikari (2009)
- "gnulib/lib/dfa.c".
If the scanner detects a transition on backref, it returns a kind of "semi-success" indicating that the match will have to be verified with a backtracking matcher.
- Kearns, Steven (August 2013). "Sublinear Matching With Finite Automata Using Reverse Suffix Scanning". arXiv:1308.3822.
- Navarro, Gonzalo (10 November 2001). "NR‐grep: a fast and flexible pattern‐matching tool" (PDF). Software: Practice and Experience. 31 (13): 1265–1312. doi:10.1002/spe.411.
- "travisdowns/polyregex". 5 July 2019.
- Schmid, Markus L. (March 2019). "Regular Expressions with Backreferences: Polynomial-Time Matching Techniques". arXiv:1903.05896.
- "Vim documentation: pattern". Vimdoc.sourceforge.net. Retrieved 2013-09-25.
- "UTS#18 on Unicode Regular Expressions, Annex A: Character Blocks". Retrieved 2010-02-05.
- Horowitz, Bradley (24 October 2011). "A fall sweep". Google Blog. Retrieved 4 May 2019.
- Cox, Russ (January 2012). "Regular Expression Matching with a Trigram Index, or How Google Code Search Worked". swtch.com. Retrieved 4 May 2019.
- The character 'm' is not always required to specify a Perl match operation. For example,
m/[^abc]/could also be rendered as/[^abc]/. The 'm' is only necessary if the user wishes to specify a match operation without using a forward-slash as the regex delimiter. Sometimes it is useful to specify an alternate regex delimiter in order to avoid "delimiter collision". See 'perldoc perlre' for more details. - E.g., see Java in a Nutshell, p. 213; Python Scripting for Computational Science, p. 320; Programming PHP, p. 106.
- Note that all the if statements return a TRUE value
- Conway, Damian (2005). "Regular Expressions, End of String". Perl Best Practices. O'Reilly. p. 240. ISBN 978-0-596-00173-5.
References
- Aho, Alfred V. (1990). van Leeuwen, Jan (ed.). Algorithms for finding patterns in strings. Handbook of Theoretical Computer Science, volume A: Algorithms and Complexity. The MIT Press. pp. 255–300.CS1 maint: ref=harv (link)
- Aho, Alfred V.; Ullman, Jeffrey D. (1992). "Chapter 10. Patterns, Automata, and Regular Expressions" (PDF). Foundations of Computer Science.
- "Regular Expressions". The Single UNIX ® Specification, Version 2. The Open Group. 1997.CS1 maint: ref=harv (link)
- "Chapter 9: Regular Expressions". The Open Group Base Specifications. The Open Group (6). 2004. IEEE Std 1003.1, 2004 Edition.CS1 maint: ref=harv (link)
- Cox, Russ (2007). "Regular Expression Matching Can Be Simple and Fast".CS1 maint: ref=harv (link)
- Forta, Ben (2004). Sams Teach Yourself Regular Expressions in 10 Minutes. Sams. ISBN 978-0-672-32566-3.
- Friedl, Jeffrey E. F. (2002). Mastering Regular Expressions. O'Reilly. ISBN 978-0-596-00289-3.
- Gelade, Wouter; Neven, Frank (2008). Succinctness of the Complement and Intersection of Regular Expressions. Proceedings of the 25th International Symposium on Theoretical Aspects of Computer Science (STACS 2008). pp. 325–336. arXiv:0802.2869.CS1 maint: ref=harv (link)
- Goyvaerts, Jan; Levithan, Steven (2009). Regular Expressions Cookbook. [O'reilly]. ISBN 978-0-596-52068-7.
- Gruber, Hermann; Holzer, Markus (2008). Finite Automata, Digraph Connectivity, and Regular Expression Size (PDF). Proceedings of the 35th International Colloquium on Automata, Languages and Programming (ICALP 2008). 5126. pp. 39–50. doi:10.1007/978-3-540-70583-3_4.CS1 maint: ref=harv (link)
- Habibi, Mehran (2004). Real World Regular Expressions with Java 1.4. Springer. ISBN 978-1-59059-107-9.
- Hopcroft, John E.; Motwani, Rajeev; Ullman, Jeffrey D. (2000). Introduction to Automata Theory, Languages, and Computation (2nd ed.). Addison-Wesley.
- Johnson, Walter L.; Porter, James H.; Ackley, Stephanie I.; Ross, Douglas T. (1968). "Automatic generation of efficient lexical processors using finite state techniques". Communications of the ACM. 11 (12): 805–813. doi:10.1145/364175.364185.
- Kleene, Stephen C. (1951). Shannon, Claude E.; McCarthy, John (eds.). Representation of Events in Nerve Nets and Finite Automata (PDF). Automata Studies. Princeton University Press. pp. 3–42.CS1 maint: ref=harv (link)
- Kozen, Dexter (1991). A Completeness Theorem for Kleene Algebras and the Algebra of Regular Events. Proceedings of the 6th Annual IEEE Symposium on Logic in Computer Science (LICS 1991). pp. 214–225. doi:10.1109/LICS.1991.151646. hdl:1813/6963. ISBN 978-0-8186-2230-4.CS1 maint: ref=harv (link)
- Laurikari, Ville (2009). "TRE library 0.7.6".
- Liger, François; McQueen, Craig; Wilton, Paul (2002). Visual Basic .NET Text Manipulation Handbook. Wrox Press. ISBN 978-1-86100-730-8.
- Sipser, Michael (1998). "Chapter 1: Regular Languages". Introduction to the Theory of Computation. PWS Publishing. pp. 31–90. ISBN 978-0-534-94728-6.CS1 maint: ref=harv (link)
- Stubblebine, Tony (2003). Regular Expression Pocket Reference. O'Reilly. ISBN 978-0-596-00415-6.
- Thompson, Ken (1968). "Programming Techniques: Regular expression search algorithm". Communications of the ACM. 11 (6): 419–422. doi:10.1145/363347.363387.
- Wall, Larry (2002). "Apocalypse 5: Pattern Matching".
External links
| Wikibooks has a book on the topic of: Regular Expressions |
| The Wikibook R Programming has a page on the topic of: Text Processing |
| Look up regular expression in Wiktionary, the free dictionary. |

- Regular Expressions at Curlie
- ISO/IEC 9945-2:1993 Information technology – Portable Operating System Interface (POSIX) – Part 2: Shell and Utilities
- ISO/IEC 9945-2:2002 Information technology – Portable Operating System Interface (POSIX) – Part 2: System Interfaces
- ISO/IEC 9945-2:2003 Information technology – Portable Operating System Interface (POSIX) – Part 2: System Interfaces
- ISO/IEC/IEEE 9945:2009 Information technology – Portable Operating System Interface (POSIX®) Base Specifications, Issue 7
- Regular Expression, IEEE Std 1003.1-2017, Open Group
| Authority control |
|
|---|