Regular language
In theoretical computer science and formal language theory, a regular language (also called a rational language[1][2]) is a formal language that can be expressed using a regular expression, in the strict sense of the latter notion used in theoretical computer science (as opposed to many regular expressions engines provided by modern programming languages, which are augmented with features that allow recognition of languages that cannot be expressed by a classic regular expression).
Alternatively, a regular language can be defined as a language recognized by a finite automaton. The equivalence of regular expressions and finite automata is known as Kleene's theorem[3] (after American mathematician Stephen Cole Kleene). In the Chomsky hierarchy, regular languages are defined to be the languages that are generated by Type-3 grammars (regular grammars).
Regular languages are very useful in input parsing and programming language design.
Formal definition
The collection of regular languages over an alphabet Σ is defined recursively as follows:
- The empty language Ø, and the empty string language {ε} are regular languages.
- For each a ∈ Σ (a belongs to Σ), the singleton language {a} is a regular language.
- If A and B are regular languages, then A ∪ B (union), A • B (concatenation), and A* (Kleene star) are regular languages.
- No other languages over Σ are regular.
See regular expression for its syntax and semantics. Note that the above cases are in effect the defining rules of regular expression.
Examples
All finite languages are regular; in particular the empty string language {ε} = Ø* is regular. Other typical examples include the language consisting of all strings over the alphabet {a, b} which contain an even number of as, or the language consisting of all strings of the form: several as followed by several bs.
A simple example of a language that is not regular is the set of strings { anbn | n ≥ 0 }.[4] Intuitively, it cannot be recognized with a finite automaton, since a finite automaton has finite memory and it cannot remember the exact number of a's. Techniques to prove this fact rigorously are given below.
Equivalent formalisms
A regular language satisfies the following equivalent properties:
- it is the language of a regular expression (by the above definition)
- it is the language accepted by a nondeterministic finite automaton (NFA)[note 1][note 2]
- it is the language accepted by a deterministic finite automaton (DFA)[note 3][note 4]
- it can be generated by a regular grammar[note 5][note 6]
- it is the language accepted by an alternating finite automaton
- it is the language accepted by a two-way finite automaton
- it can be generated by a prefix grammar
- it can be accepted by a read-only Turing machine
- it can be defined in monadic second-order logic (Büchi–Elgot–Trakhtenbrot theorem[5])
- it is recognized by some finite monoid M, meaning it is the preimage { w∈Σ* | f(w)∈S } of a subset S of a finite monoid M under a monoid homomorphism f: Σ* → M from the free monoid on its alphabet[note 7]
- the number of equivalence classes of its syntactic congruence is finite.[note 8][note 9] (This number equals the number of states of the minimal deterministic finite automaton accepting L.)
Properties 10. and 11. are purely algebraic approaches to define regular languages; a similar set of statements can be formulated for a monoid M⊂Σ*. In this case, equivalence over M leads to the concept of a recognizable language.
Some authors use one of the above properties different from "1." as an alternative definition of regular languages.
Some of the equivalences above, particularly those among the first four formalisms, are called Kleene's theorem in textbooks. Precisely which one (or which subset) is called such varies between authors. One textbook calls the equivalence of regular expressions and NFAs ("1." and "2." above) "Kleene's theorem".[6] Another textbook calls the equivalence of regular expressions and DFAs ("1." and "3." above) "Kleene's theorem".[7] Two other textbooks first prove the expressive equivalence of NFAs and DFAs ("2." and "3.") and then state "Kleene's theorem" as the equivalence between regular expressions and finite automata (the latter said to describe "recognizable languages").[2][8] A linguistically oriented text first equates regular grammars ("4." above) with DFAs and NFAs, calls the languages generated by (any of) these "regular", after which it introduces regular expressions which it terms to describe "rational languages", and finally states "Kleene's theorem" as the coincidence of regular and rational languages.[9] Other authors simply define "rational expression" and "regular expressions" as synonymous and do the same with "rational languages" and "regular languages".[1][2]
Closure properties
The regular languages are closed under various operations, that is, if the languages K and L are regular, so is the result of the following operations:
- the set theoretic Boolean operations: union K ∪ L, intersection K ∩ L, and complement L, hence also relative complement K - L.[10]
- the regular operations: K ∪ L, concatenation K ∘ L, and Kleene star L*.[11]
- the trio operations: string homomorphism, inverse string homomorphism, and intersection with regular languages. As a consequence they are closed under arbitrary finite state transductions, like quotient K / L with a regular language. Even more, regular languages are closed under quotients with arbitrary languages: If L is regular then L / K is regular for any K.
- the reverse (or mirror image) LR.[12] Given a nondeterministic finite automaton to recognize L, an automaton for LR can be obtained by reversing all transitions and interchanging starting and finishing states. This may result in multiple starting states; ε-transitions can be used to join them.
Decidability properties
Given two deterministic finite automata A and B, it is decidable whether they accept the same language.[13] As a consequence, using the above closure properties, the following problems are also decidable for arbitrarily given deterministic finite automata A and B, with accepted languages LA and LB, respectively:
- Containment: is LA ⊆ LB ?[note 10]
- Disjointness: is LA ∩ LB = {} ?
- Emptiness: is LA = {} ?
- Universality: is LA = Σ* ?
- Membership: given a ∈ Σ*, is a ∈ LB ?
For regular expressions, the universality problem is NP-complete already for a singleton alphabet.[14] For larger alphabets, that problem is PSPACE-complete.[15] If regular expressions are extended to allow also a squaring operator, with "A2" denoting the same as "AA", still just regular languages can be described, but the universality problem has an exponential space lower bound,[16][17][18] and is in fact complete for exponential space with respect to polynomial-time reduction.[19]
Complexity results
In computational complexity theory, the complexity class of all regular languages is sometimes referred to as REGULAR or REG and equals DSPACE(O(1)), the decision problems that can be solved in constant space (the space used is independent of the input size). REGULAR ≠ AC0, since it (trivially) contains the parity problem of determining whether the number of 1 bits in the input is even or odd and this problem is not in AC0.[20] On the other hand, REGULAR does not contain AC0, because the nonregular language of palindromes, or the nonregular language can both be recognized in AC0.[21]

If a language is not regular, it requires a machine with at least Ω(log log n) space to recognize (where n is the input size).[22] In other words, DSPACE(o(log log n)) equals the class of regular languages. In practice, most nonregular problems are solved by machines taking at least logarithmic space.
Location in the Chomsky hierarchy
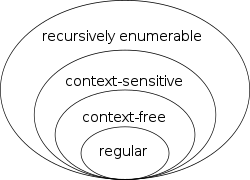
To locate the regular languages in the Chomsky hierarchy, one notices that every regular language is context-free. The converse is not true: for example the language consisting of all strings having the same number of a's as b's is context-free but not regular. To prove that a language such as this is not regular, one often uses the Myhill–Nerode theorem or the pumping lemma among other methods.[23]
Important subclasses of regular languages include
- Finite languages, those containing only a finite number of words.[24] These are regular languages, as one can create a regular expression that is the union of every word in the language.
- Star-free languages, those that can be described by a regular expression constructed from the empty symbol, letters, concatenation and all boolean operators including complementation but not the Kleene star: this class includes all finite languages.[25]
The number of words in a regular language
Let denote the number of words of length in . The ordinary generating function for L is the formal power series




The generating function of a language L is a rational function if L is regular.[26] Hence for every regular language the sequence is constant-recursive; that is, there exist an integer constant , complex constants and complex polynomials such that for every the number of words of length in is .[27][28][29][30]






Thus, non-regularity of certain languages can be proved by counting the words of a given length in . Consider, for example, the Dyck language of strings of balanced parentheses. The number of words of length in the Dyck language is equal to the Catalan number , which is not of the form , witnessing the non-regularity of the Dyck language. Care must be taken since some of the eigenvalues could have the same magnitude. For example, the number of words of length in the language of all even binary words is not of the form , but the number of words of even or odd length are of this form; the corresponding eigenvalues are . In general, for every regular language there exists a constant such that for all , the number of words of length is asymptotically .[31]










The zeta function of a language L is[26]

The zeta function of a regular language is not in general rational, but that of an arbitrary cyclic language is.[32][33]
Generalizations
The notion of a regular language has been generalized to infinite words (see ω-automata) and to trees (see tree automaton).
Rational set generalizes the notion (of regular/rational language) to monoids that are not necessarily free. Likewise, the notion of a recognizable language (by a finite automaton) has namesake as recognizable set over a monoid that is not necessarily free. Howard Straubing notes in relation to these facts that “The term "regular language" is a bit unfortunate. Papers influenced by Eilenberg's monograph[34] often use either the term "recognizable language", which refers to the behavior of automata, or "rational language", which refers to important analogies between regular expressions and rational power series. (In fact, Eilenberg defines rational and recognizable subsets of arbitrary monoids; the two notions do not, in general, coincide.) This terminology, while better motivated, never really caught on, and "regular language" is used almost universally.”[35]
Rational series is another generalization, this time in the context of a formal power series over a semiring. This approach gives rise to weighted rational expressions and weighted automata. In this algebraic context, the regular languages (corresponding to Boolean-weighted rational expressions) are usually called rational languages.[36][37] Also in this context, Kleene's theorem finds a generalization called the Kleene-Schützenberger theorem.
Induction
Notes
- 1. ⇒ 2. by Thompson's construction algorithm
- 2. ⇒ 1. by Kleene's algorithm or using Arden's lemma
- 2. ⇒ 3. by the powerset construction
- 3. ⇒ 2. since the former definition is stronger than the latter
- 2. ⇒ 4. see Hopcroft, Ullman (1979), Theorem 9.2, p.219
- 4. ⇒ 2. see Hopcroft, Ullman (1979), Theorem 9.1, p.218
- 3. ⇔ 10. by the Myhill–Nerode theorem
- u~v is defined as: uw∈L if and only if vw∈L for all w∈Σ*
- 3. ⇔ 11. see the proof in the Syntactic monoid article, and see p.160 in Holcombe, W.M.L. (1982). Algebraic automata theory. Cambridge Studies in Advanced Mathematics. 1. Cambridge University Press. ISBN 0-521-60492-3. Zbl 0489.68046.
- Check if LA ∩ LB = LA. Deciding this property is NP-hard in general; see File:RegSubsetNP.pdf for an illustration of the proof idea.
References
- Berstel, Jean; Reutenauer, Christophe (2011). Noncommutative rational series with applications. Encyclopedia of Mathematics and Its Applications. 137. Cambridge: Cambridge University Press. ISBN 978-0-521-19022-0. Zbl 1250.68007.
- Eilenberg, Samuel (1974). Automata, Languages, and Machines. Volume A. Pure and Applied Mathematics. 58. New York: Academic Press. Zbl 0317.94045.
- Salomaa, Arto (1981). Jewels of Formal Language Theory. Pitman Publishing. ISBN 0-273-08522-0. Zbl 0487.68064.
- Sipser, Michael (1997). Introduction to the Theory of Computation. PWS Publishing. ISBN 0-534-94728-X. Zbl 1169.68300. Chapter 1: Regular Languages, pp. 31–90. Subsection "Decidable Problems Concerning Regular Languages" of section 4.1: Decidable Languages, pp. 152–155.
- Philippe Flajolet and Robert Sedgewick, Analytic Combinatorics: Symbolic Combinatorics. Online book, 2002.
- John E. Hopcroft; Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 0-201-02988-X.
- Alfred V. Aho and John E. Hopcroft and Jeffrey D. Ullman (1974). The Design and Analysis of Computer Algorithms. Addison-Wesley.
- Ruslan Mitkov (2003). The Oxford Handbook of Computational Linguistics. Oxford University Press. p. 754. ISBN 978-0-19-927634-9.
- Mark V. Lawson (2003). Finite Automata. CRC Press. pp. 98–103. ISBN 978-1-58488-255-8.
- Sheng Yu (1997). "Regular languages". In Grzegorz Rozenberg; Arto Salomaa (eds.). Handbook of Formal Languages: Volume 1. Word, Language, Grammar. Springer. p. 41. ISBN 978-3-540-60420-4.
- Eilenberg (1974), p. 16 (Example II, 2.8) and p. 25 (Example II, 5.2).
- M. Weyer: Chapter 12 - Decidability of S1S and S2S, p. 219, Theorem 12.26. In: Erich Grädel, Wolfgang Thomas, Thomas Wilke (Eds.): Automata, Logics, and Infinite Games: A Guide to Current Research. Lecture Notes in Computer Science 2500, Springer 2002.
- Robert Sedgewick; Kevin Daniel Wayne (2011). Algorithms. Addison-Wesley Professional. p. 794. ISBN 978-0-321-57351-3.
- Jean-Paul Allouche; Jeffrey Shallit (2003). Automatic Sequences: Theory, Applications, Generalizations. Cambridge University Press. p. 129. ISBN 978-0-521-82332-6.
- Kenneth Rosen (2011). Discrete Mathematics and Its Applications 7th edition. McGraw-Hill Science. pp. 873–880.
- Horst Bunke; Alberto Sanfeliu (January 1990). Syntactic and Structural Pattern Recognition: Theory and Applications. World Scientific. p. 248. ISBN 978-9971-5-0566-0.
- Salomaa (1981) p.28
- Salomaa (1981) p.27
- Hopcroft, Ullman (1979), Chapter 3, Exercise 3.4g, p. 72
- Hopcroft, Ullman (1979), Theorem 3.8, p.64; see also Theorem 3.10, p.67
- Aho, Hopcroft, Ullman (1974), Exercise 10.14, p.401
- Aho, Hopcroft, Ullman (1974), Theorem 10.14, p399
- Hopcroft, Ullman (1979), Theorem 13.15, p.351
- A.R. Meyer & L.J. Stockmeyer (Oct 1972). The Equivalence Problem for Regular Expressions with Squaring Requires Exponential Space (PDF). 13th Annual IEEE Symp. on Switching and Automata Theory. pp. 125–129.
- L.J. Stockmeyer & A.R. Meyer (1973). Word Problems Requiring Exponential Time (PDF). Proc. 5th ann. symp. on Theory of computing (STOC). ACM. pp. 1–9.
- Hopcroft, Ullman (1979), Corollary p.353
- Furst, Merrick; Saxe, James B.; Sipser, Michael (1984). "Parity, circuits, and the polynomial-time hierarchy". Mathematical Systems Theory. 17 (1): 13–27. doi:10.1007/BF01744431. MR 0738749.
- Cook, Stephen; Nguyen, Phuong (2010). Logical foundations of proof complexity (1. publ. ed.). Ithaca, NY: Association for Symbolic Logic. p. 75. ISBN 978-0-521-51729-4.
- J. Hartmanis, P. L. Lewis II, and R. E. Stearns. Hierarchies of memory-limited computations. Proceedings of the 6th Annual IEEE Symposium on Switching Circuit Theory and Logic Design, pp. 179–190. 1965.
- "How to prove that a language is not regular?". cs.stackexchange.com. Retrieved 10 April 2018.
- A finite language shouldn't be confused with a (usually infinite) language generated by a finite automaton.
- Volker Diekert; Paul Gastin (2008). "First-order definable languages" (PDF). In Jörg Flum; Erich Grädel; Thomas Wilke (eds.). Logic and automata: history and perspectives. Amsterdam University Press. ISBN 978-90-5356-576-6.
- Honkala, Juha (1989). "A necessary condition for the rationality of the zeta function of a regular language". Theor. Comput. Sci. 66 (3): 341–347. doi:10.1016/0304-3975(89)90159-x. Zbl 0675.68034.
- Flajolet & Sedgweick, section V.3.1, equation (13).
- "Number of words in the regular language $(00)^*$". cs.stackexchange.com. Retrieved 10 April 2018.
- Proof of theorem for arbitrary DFAs
- "Number of words of a given length in a regular language". cs.stackexchange.com. Retrieved 10 April 2018.
- Flajolet & Sedgewick (2002) Theorem V.3
- Berstel, Jean; Reutenauer, Christophe (1990). "Zeta functions of formal languages". Trans. Am. Math. Soc. 321 (2): 533–546. CiteSeerX 10.1.1.309.3005. doi:10.1090/s0002-9947-1990-0998123-x. Zbl 0797.68092.
- Berstel & Reutenauer (2011) p.222
- Samuel Eilenberg. Automata, languages, and machines. Academic Press. in two volumes "A" (1974, ISBN 9780080873749) and "B" (1976, ISBN 9780080873756), the latter with two chapters by Bret Tilson.
- Straubing, Howard (1994). Finite automata, formal logic, and circuit complexity. Progress in Theoretical Computer Science. Basel: Birkhäuser. p. 8. ISBN 3-7643-3719-2. Zbl 0816.68086.
- Berstel & Reutenauer (2011) p.47
- Sakarovitch, Jacques (2009). Elements of automata theory. Translated from the French by Reuben Thomas. Cambridge: Cambridge University Press. p. 86. ISBN 978-0-521-84425-3. Zbl 1188.68177.
Further reading
- Kleene, S.C.: Representation of events in nerve nets and finite automata. In: Shannon, C.E., McCarthy, J. (eds.) Automata Studies, pp. 3–41. Princeton University Press, Princeton (1956); it is a slightly modified version of his 1951 RAND Corporation report of the same title, RM704.
- Sakarovitch, J (1987). "Kleene's theorem revisited". Lecture Notes in Computer Science. 1987: 39–50. doi:10.1007/3540185356_29. ISBN 978-3-540-18535-2. Cite journal requires
|journal=(help)
External links

- Complexity Zoo: Class REG