OCRopus
OCRopus is a free document analysis and optical character recognition (OCR) system released under the Apache License v2.0 with a very modular design using command-line interfaces.
 | |
| Developer(s) | Thomas Breuel, DFKI |
|---|---|
| Initial release | 9 April 2007[1] |
| Stable release | 1.3.3
/ 16 December 2017 |
| Repository | |
| Written in | C++ and Python |
| Operating system | FreeBSD, Linux, Mac OS X |
| Type | Optical character recognition |
| License | Apache License v2.0 |
| Website | github |
OCRopus is developed under the lead of Thomas Breuel from the German Research Centre for Artificial Intelligence in Kaiserslautern, Germany and was sponsored by Google.
Description
OCRopus was especially designed for use in high-volume digitization projects of books, such as Google Books, Internet Archive or libraries. A large number of languages and fonts are to be supported.[2] However, it can also be used for desktop and office applications or for application for the visually impaired people.
The main components of OCRopus are formed:
Single or multiple scripts are available for these components. The modular approach allows individual workflows to be used and individual steps to be exchanged.
By default, OCRopus comes with a model for English texts and a model for text in Fraktur. These models refer to the script and are largely independent of the actual language.[3] New characters or language variants can be trained either new or in addition.
Recent text recognition is based on recurrent neural networks (LSTM) and does not require a language model. This makes it possible to train language-independent models for which good recognition results for English, German and French have been shown at the same time.[4] In addition to the Latin script, there are results for other scripts such as Sanskrit, Urdu, Devanagari and Greek.
Very good detection rates can be achieved through an appropriate training. This extra effort is particularly worthwhile for difficult documents or scripts that are no longer common today, which are not in the focus of other OCR software.[5][6]
History
On 9 April 2007, OCRopus was announced as a Google-sponsored project to develop advanced OCR technologies.[1] Funding was granted for a period of three years and covered in particular PhD and postdoctoral positions at DFKI and the University of Kaiserslautern. In return, OCRopus was also used for automatic text recognition in Google Book Search.[7] Licensing under an open source license was made right from the start to facilitate collaboration between industrial and academic research.[8] OCRopus has received further funding from the Andrew W. Mellon Foundation and the BMBF.[9]
The first alpha version 0.1 was released on 22 October 2007 and several pre-releases followed between December 2007 and May 2009 reaching a stable version 0.4.4 in March 2010.[10] Originally, the software was developed in C++, Python and Lua with Jam as a build system. A complete refactoring of the source code in Python modules was done and released in version 0.5 (June 2012).[11]
Initially, Tesseract was used as the only text recognition module. Since 2009 (version 0.4) Tesseract was only supported as a plugin. Instead, a self-developed text recognizer (also segment-based) was used.[12] This recognizer was then used together with OpenFST[13] for language modeling after the recognition step. From 2013 onwards, an additional recognition with recurrent neural networks (LSTM) was offered, which with the release of version 1.0 in November 2014 is the only recognizer.[14][15]
The source code is managed over GitHub and is maintained and developed by a developer community.[16] The current version of OCRopus is 1.3.3 (December 2017).[17]
Usage
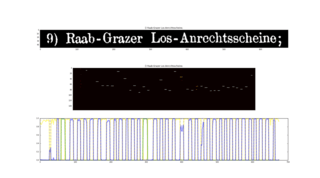
OCRopus can be used from the command line. Once installed, it can be invoked by specifying the input images. It will output the recognized text to standard output directly or write it as hOCR (HTML-based) code into files, from which it then can be transformed to a searchable PDF. If more precise control is needed, options can be specified on the command line to perform specific operations (e.g. recognizing a single line).[18]
Example for the OCRopus calls to recognize the text in an image:
# perform binarization
ocropus-nlbin tests/ersch.png -o book
# perform page layout analysis
ocropus-gpageseg book/0001.bin.png
# perform text line recognition (with a fraktur model)
ocropus-rpred -m models/fraktur.pyrnn.gz book/0001/*.bin.png
# generate HTML output
ocropus-hocr book/0001.bin.png -o book/0001.htmlOther tools concentrate on the training part of OCRopus. There are OCRopus models to extract text from Latin, Greek, Cyrillic and Indic scripts.[19]
References
- Breuel, Thomas (9 April 2007). "Announcing the OCRopus Open Source OCR System". Google Developers Blog. Retrieved 29 December 2017.
- Breuel, Thomas (2009). Recent Progress on the OCRopus OCR System. Proceedings of the International Workshop on Multilingual OCR. MOCR '09. New York, NY, USA: ACM. pp. 2:1–2:10. doi:10.1145/1577802.1577805. ISBN 9781605586984.
- "Models". ocropy wiki. Retrieved 5 January 2018.
- Ul-Hasan, Adnan; Breuel, Thomas M. (2013). Can We Build Language-independent OCR Using LSTM Networks?. Proceedings of the 4th International Workshop on Multilingual OCR. MOCR '13. New York, NY, USA: ACM. pp. 9:1–9:5. doi:10.1145/2505377.2505394. ISBN 9781450321143.
- Springmann, Uwe (1 December 2016). "OCR für alte Drucke". Informatik-Spektrum (in German). 39 (6): 459–462. doi:10.1007/s00287-016-1004-3. ISSN 0170-6012.
- Simistira, F.; Ul-Hassan, A.; Papavassiliou, V.; Gatos, B.; Katsouros, V.; Liwicki, M. (August 2015). Recognition of historical Greek polytonic scripts using LSTM networks. 2015 13th International Conference on Document Analysis and Recognition (ICDAR). pp. 766–770. doi:10.1109/icdar.2015.7333865. ISBN 978-1-4799-1805-8.
- "Research project OCRopus". www.dfki.de. Retrieved 5 January 2018.
- Breuel, Thomas M. (28 January 2008). "The OCRopus open source OCR system". Proceedings Volume 6815, Document Recognition and Retrieval XV. Document Recognition and Retrieval XV. 6815: 68150F–68150F–15. Bibcode:2008SPIE.6815E..0FB. CiteSeerX 10.1.1.99.8505. doi:10.1117/12.783598.
- "ocropus project website". Google Project Hosting. January 2019. Archived from the original on 24 December 2012.
- "Older versions - ocropy". GitHub. Retrieved 5 January 2018.
- "OCRopus 0.5". Google Groups. 2 June 2012.
- OCRopus doesn't even link with Tesseract by default.
- Official OpenFST website.
- "ocropy - release v1.0". GitHub. 2 November 2014. Retrieved 5 January 2018.
- Breuel, T. M.; Ul-Hasan, A.; Al-Azawi, M. A.; Shafait, F. (August 2013). High-Performance OCR for Printed English and Fraktur Using LSTM Networks. 2013 12th International Conference on Document Analysis and Recognition. pp. 683–687. doi:10.1109/icdar.2013.140. ISBN 978-0-7695-4999-6.
- "ocropy: Python-based tools for document analysis and OCR", GitHub, retrieved 5 January 2018
- "Releases ocropy". GitHub. Retrieved 5 January 2018.
- "ocropy wiki". GitHub. Retrieved 30 December 2017.
- "ocropy models". GitHub. Retrieved 13 March 2018.
External links
- ocropy on GitHub
- Ocropy wiki on GitHub
- IUPR Publication Server (papers behind many of the algorithms used in OCRopus)