Differentiable neural computer
In artificial intelligence, a differentiable neural computer (DNC) is a memory augmented neural network architecture (MANN), which is typically (not by definition) recurrent in its implementation. The model was published in 2016 by Alex Graves et al. of DeepMind.[1]
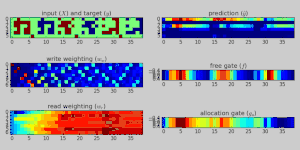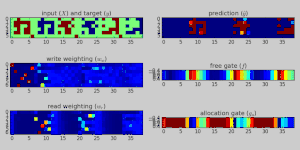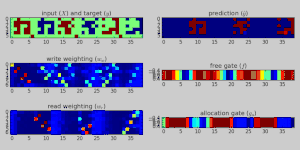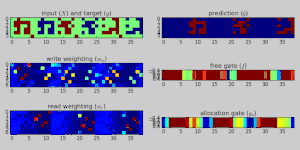
Applications
DNC indirectly takes inspiration from Von-Neumann architecture, making it likely to outperform conventional architectures in tasks that are fundamentally algorithmic that cannot be learned by finding a decision boundary.
So far, DNCs have been demonstrated to handle only relatively simple tasks, which can be solved using conventional programming. But DNCs don't need to be programmed for each problem, but can instead be trained. This attention span allows the user to feed complex data structures such as graphs sequentially, and recall them for later use. Furthermore, they can learn aspects of symbolic reasoning and apply it to working memory. The researchers who published the method see promise that DNCs can be trained to perform complex, structured tasks[1][2] and address big-data applications that require some sort of reasoning, such as generating video commentaries or semantic text analysis.[3][4]
DNC can be trained to navigate rapid transit systems, and apply that network to a different system. A neural network without memory would typically have to learn about each transit system from scratch. On graph traversal and sequence-processing tasks with supervised learning, DNCs performed better than alternatives such as long short-term memory or a neural turing machine.[5] With a reinforcement learning approach to a block puzzle problem inspired by SHRDLU, DNC was trained via curriculum learning, and learned to make a plan. It performed better than a traditional recurrent neural network.[5]
Architecture
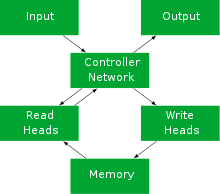
DNC networks were introduced as an extension of the Neural Turing Machine (NTM), with the addition of memory attention mechanisms that control where the memory is stored, and temporal attention that records the order of events. This structure allows DNCs to be more robust and abstract than a NTM, and still perform tasks that have longer-term dependencies than some predecessors such as Long Short Term Memory (LSTM). The memory, which is simply a matrix, can be allocated dynamically and accessed indefinitely. The DNC is differentiable end-to-end (each subcomponent of the model is differentiable, therefore so is the whole model). This makes it possible to optimize them efficiently using gradient descent.[3][6][7]
The DNC model is similar to the Von Neumann architecture, and because of the resizability of memory, it is Turing complete.[8]
Traditional DNC
DNC, as originally published[1]
| Independent variables | |
| Input vector | |
| Target vector | |
| Controller | |
| Controller input matrix | |
| Deep (layered) LSTM | |
| Input gate vector | |
| Output gate vector | |
| Forget gate vector | |
| State gate vector, | |
| Hidden gate vector, | |
| DNC output vector | |
| Read & Write heads | |
| Interface parameters | |
| Read heads | |
| Read keys | |
| Read strengths | |
| Free gates | |
| Read modes, | |
| Write head | |
| Write key | |
| Write strength | |
| Erase vector | |
| Write vector | |
| Allocation gate | |
| Write gate | |
| Memory | |
| Memory matrix, Matrix of ones | |
| Usage vector | |
| Precedence weighting, | |
| Temporal link matrix, | |
| Write weighting | |
| Read weighting | |
| Read vectors | |
| Content-based addressing, Lookup key , key strength | |
| Indices of , sorted in ascending order of usage | |
| Allocation weighting | |
| Write content weighting | |
| Read content weighting | |
| Forward weighting | |
| Backward weighting | |
| Memory retention vector | |
| Definitions | |
| Weight matrix, bias vector | |
| Zeros matrix, ones matrix, identity matrix | |
| Element-wise multiplication | |
| Cosine similarity | |
| Sigmoid function | |
| Oneplus function | |
| for j = 1, …, K. | Softmax function |






















































Extensions
Refinements include sparse memory addressing, which reduces time and space complexity by thousands of times. This can be achieved by using an approximate nearest neighbor algorithm, such as Locality-sensitive hashing, or a random k-d tree like Fast Library for Approximate Nearest Neighbors from UBC.[9] Adding Adaptive Computation Time (ACT) separates computation time from data time, which uses the fact that problem length and problem difficulty are not always the same.[10] Training using synthetic gradients performs considerably better than Backpropagation through time (BPTT).[11] Robustness can be improved with use of layer normalization and Bypass Dropout as regularization.[12]
References
- Graves, Alex; Wayne, Greg; Reynolds, Malcolm; Harley, Tim; Danihelka, Ivo; Grabska-Barwińska, Agnieszka; Colmenarejo, Sergio Gómez; Grefenstette, Edward; Ramalho, Tiago (2016-10-12). "Hybrid computing using a neural network with dynamic external memory". Nature. 538 (7626): 471–476. Bibcode:2016Natur.538..471G. doi:10.1038/nature20101. ISSN 1476-4687. PMID 27732574.
- "Differentiable neural computers | DeepMind". DeepMind. Retrieved 2016-10-19.
- Burgess, Matt. "DeepMind's AI learned to ride the London Underground using human-like reason and memory". WIRED UK. Retrieved 2016-10-19.
- Jaeger, Herbert (2016-10-12). "Artificial intelligence: Deep neural reasoning". Nature. 538 (7626): 467–468. Bibcode:2016Natur.538..467J. doi:10.1038/nature19477. ISSN 1476-4687. PMID 27732576.
- James, Mike. "DeepMind's Differentiable Neural Network Thinks Deeply". www.i-programmer.info. Retrieved 2016-10-20.
- "DeepMind AI 'Learns' to Navigate London Tube". PCMAG. Retrieved 2016-10-19.
- Mannes, John. "DeepMind's differentiable neural computer helps you navigate the subway with its memory". TechCrunch. Retrieved 2016-10-19.
- "RNN Symposium 2016: Alex Graves - Differentiable Neural Computer".
- Jack W Rae; Jonathan J Hunt; Harley, Tim; Danihelka, Ivo; Senior, Andrew; Wayne, Greg; Graves, Alex; Timothy P Lillicrap (2016). "Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes". arXiv:1610.09027 [cs.LG].
- Graves, Alex (2016). "Adaptive Computation Time for Recurrent Neural Networks". arXiv:1603.08983 [cs.NE].
- Jaderberg, Max; Wojciech Marian Czarnecki; Osindero, Simon; Vinyals, Oriol; Graves, Alex; Silver, David; Kavukcuoglu, Koray (2016). "Decoupled Neural Interfaces using Synthetic Gradients". arXiv:1608.05343 [cs.LG].
- Franke, Jörg; Niehues, Jan; Waibel, Alex (2018). "Robust and Scalable Differentiable Neural Computer for Question Answering". arXiv:1807.02658 [cs.CL].
External links
- A bit-by-bit guide to the equations governing differentiable neural computers
- DeepMind's Differentiable Neural Network Thinks Deeply
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General | | ||||||
| Concepts | |||||||
| Programming languages | |||||||
| Application |
| ||||||
| Hardware | |||||||
| Software library | |||||||
| Implementation |
| ||||||
| People | |||||||
| |||||||