Adversarial machine learning
Adversarial machine learning is a machine learning technique that attempts to fool models by supplying deceptive input.[1][2][3] The most common reason is to cause a malfunction in a machine learning model.
Most machine learning techniques were designed to work on specific problem sets in which the training and test data are generated from the same statistical distribution (IID). When those models are applied to the real world, adversaries may supply data that violates that statistical assumption. This data may be arranged to exploit specific vulnerabilities and compromise the results.[3][4]
History
In Snow Crash (1992), the author offered scenarios of technology that was vulnerable to an adversarial attack. In Zero History (2010), a character dons a t-shirt decorated in a way that renders him invisible to electronic surveillance.[5]
In 2004, Nilesh Dalvi and others noted that linear classifiers used in spam filters could be defeated by simple "evasion attacks" as spammers inserted "good words" into their spam emails. (Around 2007, some spammers added random noise to fuzz words within "image spam" in order to defeat OCR-based filters.) In 2006, Marco Barreno and others published "Can Machine Learning Be Secure?", outlining a broad taxonomy of attacks. As late as 2013 many researchers continued to hope that non-linear classifiers (such as support vector machines and neural networks) might be robust to adversaries. In 2012, deep neural networks began to dominate computer vision problems; starting in 2014, Christian Szegedy and others demonstrated that deep neural networks could be fooled by adversaries.[6]
Examples
Examples include attacks in spam filtering, where spam messages are obfuscated through the misspelling of “bad” words or the insertion of “good” words;[7][8] attacks in computer security, such as obfuscating malware code within network packets or to mislead signature detection; attacks in biometric recognition where fake biometric traits may be exploited to impersonate a legitimate user;[9] or to compromise users' template galleries that adapt to updated traits over time.
Researchers showed that by changing only one-pixel it was possible to fool deep learning algorithms.[10][11] Others 3-D printed a toy turtle with a texture engineered to make Google's object detection AI classify it as a rifle regardless of the angle from which the turtle was viewed.[12] Creating the turtle required only low-cost commercially available 3-D printing technology.[13]
A machine-tweaked image of a dog was shown to look like a cat to both computers and humans.[14] A 2019 study reported that humans can guess how machines will classify adversarial images.[15] Researchers discovered methods for perturbing the appearance of a stop sign such that an autonomous vehicle classified it as a merge or speed limit sign.[3][16][17]
McAfee attacked Tesla's former Mobileye system, fooling it into driving 50 mph over the speed limit, simply by adding a two-inch strip of black tape to a speed limit sign.[18][19]
Adversarial patterns on glasses or clothing designed to deceive facial-recognition systems or license-plate readers, have led to a niche industry of "stealth streetwear".[20]
An adversarial attack on a neural network can allow an attacker to inject algorithms into the target system.[21] Researchers can also create adversarial audio inputs to disguise commands to intelligent assistants in benign-seeming audio.[22]
Clustering algorithms are used in security applications. Malware and computer virus analysis aims to identify malware families, and to generate specific detection signatures.[23][24]
Attack modalities
Taxonomy
Attacks against (supervised) machine learning algorithms have been categorized along three primary axes:[25] influence on the classifier, the security violation and their specificity.
- Classifier influence: An attack can influence the classifier by disrupting the classification phase. This may be preceded by an exploration phase to identify vulnerabilities. The attacker's capabilities might restricted by the presence of data manipulation constraints.[26]
- Security violation: An attack can supply malicious data that gets classified as legitimate. Malicious data supplied during training can cause legitimate data to be rejected after training.
- Specificity: A targeted attack attempts to allow a specific intrusion/disruption. Alternatively, an indiscriminate attack creates general mayhem.
This taxonomy has been extended into a more comprehensive threat model that allows explicit assumptions about the adversary's goal, knowledge of the attacked system, capability of manipulating the input data/system components, and on attack strategy.[27][28] Two of the main attack scenarios are:
Strategies
Evasion
Evasion attacks[27][28][29] are the most prevalent type of attack. For instance, spammers and hackers often attempt to evade detection by obfuscating the content of spam emails and malware. Samples are modified to evade detection; that is, to be classified as legitimate. This does not involve influence over the training data. A clear example of evasion is image-based spam in which the spam content is embedded within an attached image to evade textual analysis by anti-spam filters. Another example of evasion is given by spoofing attacks against biometric verification systems.[9]
Poisoning
Poisoning is adversarial contamination of training data. Machine learning systems can be re-trained using data collected during operations. For instance, intrusion detection systems (IDSs) are often re-trained using such data. An attacker may poison this data by injecting malicious samples during operation that subsequently disrupt retraining.[27][28][25][30][31][32]
Defense
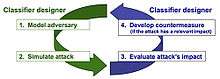
Researchers have proposed a multi-step approach to protecting machine learning.[6]
- Threat modeling - Formalize the attackers goals and capabilities with respect to the target system.
- Attack simulation - Formalize the optimization problem the attacker tries to solve according to possible attack strategies.
- Attack impact evaluation
- Countermeasure design
- Noise detection (For evasion based attack)[33]
Mechanisms
A number of defense mechanisms against evasion, poisoning, and privacy attacks have been proposed, including:
- Secure learning algorithms[8][34][35]
- Multiple classifier systems[7][36]
- AI-written algorithms.[21]
- AIs that explore the training environment; for example, in image recognition, actively navigating a 3D environment rather than passively scanning a fixed set of 2D images.[21]
- Privacy-preserving learning[28][37]
- Ladder algorithm for Kaggle-style competitions
- Game theoretic models[38]
- Sanitizing training data
Software
Available software libraries, mainly for testing and research.
- AdversariaLib - includes implementation of evasion attacks
- AdLib - Python library with a scikit-style interface which includes implementations of a number of published evasion attacks and defenses
- AlfaSVMLib - Adversarial Label Flip Attacks against Support Vector Machines[39]
- Poisoning Attacks against Support Vector Machines, and Attacks against Clustering Algorithms
- deep-pwning - Metasploit for deep learning which currently has attacks on deep neural networks using Tensorflow.[40] This framework currently updates to maintain compatibility with the latest versions of Python.
- Cleverhans - A Tensorflow Library to test existing deep learning models versus known attacks
- foolbox - Python Library to create adversarial examples, implements multiple attacks
- SecML - Python Library for secure and explainable machine learning - includes implementation of a wide range of ML and attack algorithms, support for dense and sparse data, multiprocessing, visualization tools.
See also
References
- Kianpour, Mazaher; Wen, Shao-Fang (2020). "Timing Attacks on Machine Learning: State of the Art". doi:10.1007/978-3-030-29516-5_10. Retrieved 2020-06-13.
- Bengio, Samy; Goodfellow, Ian J.; Kurakin, Alexey (2017). "Adversarial Machine Learning at Scale". Google AI. arXiv:1611.01236. Bibcode:2016arXiv161101236K. Retrieved 2018-12-13.
- Lim, Hazel Si Min; Taeihagh, Araz (2019). "Algorithmic Decision-Making in AVs: Understanding Ethical and Technical Concerns for Smart Cities". Sustainability. 11 (20): 5791. arXiv:1910.13122. Bibcode:2019arXiv191013122L. doi:10.3390/su11205791.
- Goodfellow, Ian; McDaniel, Patrick; Papernot, Nicolas (25 June 2018). "Making machine learning robust against adversarial inputs". Communications of the ACM. 61 (7): 56–66. doi:10.1145/3134599. ISSN 0001-0782. Retrieved 2018-12-13.CS1 maint: ref=harv (link)
- Vincent, James (12 April 2017). "Magic AI: these are the optical illusions that trick, fool, and flummox computers". The Verge. Retrieved 27 March 2020.
- Biggio, Battista; Roli, Fabio (December 2018). "Wild patterns: Ten years after the rise of adversarial machine learning". Pattern Recognition. 84: 317–331. arXiv:1712.03141. doi:10.1016/j.patcog.2018.07.023.
- Biggio, Battista; Fumera, Giorgio; Roli, Fabio (2010). "Multiple classifier systems for robust classifier design in adversarial environments". International Journal of Machine Learning and Cybernetics. 1 (1–4): 27–41. doi:10.1007/s13042-010-0007-7. ISSN 1868-8071.
- Brückner, Michael; Kanzow, Christian; Scheffer, Tobias (2012). "Static Prediction Games for Adversarial Learning Problems" (PDF). Journal of Machine Learning Research. 13 (Sep): 2617–2654. ISSN 1533-7928.
- Rodrigues, Ricardo N.; Ling, Lee Luan; Govindaraju, Venu (1 June 2009). "Robustness of multimodal biometric fusion methods against spoof attacks" (PDF). Journal of Visual Languages & Computing. 20 (3): 169–179. doi:10.1016/j.jvlc.2009.01.010. ISSN 1045-926X.
- Su, Jiawei; Vargas, Danilo Vasconcellos; Sakurai, Kouichi (2019). "One Pixel Attack for Fooling Deep Neural Networks". IEEE Transactions on Evolutionary Computation. 23 (5): 828–841. arXiv:1710.08864. doi:10.1109/TEVC.2019.2890858.
- Su, Jiawei; Vargas, Danilo Vasconcellos; Sakurai, Kouichi (October 2019). "One Pixel Attack for Fooling Deep Neural Networks". IEEE Transactions on Evolutionary Computation. 23 (5): 828–841. arXiv:1710.08864. doi:10.1109/TEVC.2019.2890858. ISSN 1941-0026.
- "Single pixel change fools AI programs". BBC News. 3 November 2017. Retrieved 12 February 2018.
- Athalye, A., & Sutskever, I. (2017). Synthesizing robust adversarial examples. arXiv preprint arXiv:1707.07397.
- "AI Has a Hallucination Problem That's Proving Tough to Fix". WIRED. 2018. Retrieved 10 March 2018.
- Zhou, Z., & Firestone, C. (2019). Humans can decipher adversarial images Archived 2019-03-31 at the Wayback Machine. Nature Communications, 10, 1334.
- Jain, Anant (2019-02-09). "Breaking neural networks with adversarial attacks - Towards Data Science". Medium. Retrieved 2019-07-15.
- Ackerman, Evan (2017-08-04). "Slight Street Sign Modifications Can Completely Fool Machine Learning Algorithms". IEEE Spectrum: Technology, Engineering, and Science News. Retrieved 2019-07-15.
- "A Tiny Piece of Tape Tricked Teslas Into Speeding Up 50 MPH". Wired. 2020. Retrieved 11 March 2020.
- "Model Hacking ADAS to Pave Safer Roads for Autonomous Vehicles". McAfee Blogs. 2020-02-19. Retrieved 2020-03-11.
- Seabrook, John (2020). "Dressing for the Surveillance Age". The New Yorker. Retrieved 5 April 2020.
- Heaven, Douglas (October 2019). "Why deep-learning AIs are so easy to fool". Nature: 163–166. doi:10.1038/d41586-019-03013-5.
- Hutson, Matthew (10 May 2019). "AI can now defend itself against malicious messages hidden in speech". Nature. doi:10.1038/d41586-019-01510-1.
- D. B. Skillicorn. "Adversarial knowledge discovery". IEEE Intelligent Systems, 24:54–61, 2009.
- B. Biggio, G. Fumera, and F. Roli. "Pattern recognition systems under attack: Design issues and research challenges". Int'l J. Patt. Recogn. Artif. Intell., 28(7):1460002, 2014.
- M. Barreno, B. Nelson, A. Joseph, and J. Tygar. "The security of machine learning". Machine Learning, 81:121–148, 2010
- Sikos, Leslie F. (2019). AI in Cybersecurity. Intelligent Systems Reference Library. 151. Cham: Springer. p. 50. doi:10.1007/978-3-319-98842-9. ISBN 978-3-319-98841-2.
- B. Biggio, G. Fumera, and F. Roli. "Security evaluation of pattern classifiers under attack Archived 2018-05-18 at the Wayback Machine". IEEE Transactions on Knowledge and Data Engineering, 26(4):984–996, 2014.
- Biggio, Battista; Corona, Igino; Nelson, Blaine; Rubinstein, Benjamin I. P.; Maiorca, Davide; Fumera, Giorgio; Giacinto, Giorgio; Roli, Fabio (2014). "Security Evaluation of Support Vector Machines in Adversarial Environments". Support Vector Machines Applications. Springer International Publishing. pp. 105–153. arXiv:1401.7727. doi:10.1007/978-3-319-02300-7_4. ISBN 978-3-319-02300-7.
- B. Nelson, B. I. Rubinstein, L. Huang, A. D. Joseph, S. J. Lee, S. Rao, and J. D. Tygar. "Query strategies for evading convex-inducing classifiers". J. Mach. Learn. Res., 13:1293–1332, 2012
- B. Biggio, B. Nelson, and P. Laskov. "Support vector machines under adversarial label noise". In Journal of Machine Learning Research - Proc. 3rd Asian Conf. Machine Learning, volume 20, pp. 97–112, 2011.
- M. Kloft and P. Laskov. "Security analysis of online centroid anomaly detection". Journal of Machine Learning Research, 13:3647–3690, 2012.
- Moisejevs, Ilja (2019-07-15). "Poisoning attacks on Machine Learning - Towards Data Science". Medium. Retrieved 2019-07-15.
- https://arxiv.org/abs/2007.00337
- O. Dekel, O. Shamir, and L. Xiao. "Learning to classify with missing and corrupted features". Machine Learning, 81:149–178, 2010.
- W. Liu and S. Chawla. "Mining adversarial patterns via regularized loss minimization". Machine Learning, 81(1):69–83, 2010.
- B. Biggio, G. Fumera, and F. Roli. "Evade hard multiple classifier systems". In O. Okun and G. Valentini, editors, Supervised and Unsupervised Ensemble Methods and Their Applications, volume 245 of Studies in Computational Intelligence, pages 15–38. Springer Berlin / Heidelberg, 2009.
- B. I. P. Rubinstein, P. L. Bartlett, L. Huang, and N. Taft. "Learning in a large function space: Privacy- preserving mechanisms for svm learning". Journal of Privacy and Confidentiality, 4(1):65–100, 2012.
- M. Kantarcioglu, B. Xi, C. Clifton. "Classifier Evaluation and Attribute Selection against Active Adversaries". Data Min. Knowl. Discov., 22:291–335, January 2011.
- H. Xiao, B. Biggio, B. Nelson, H. Xiao, C. Eckert, and F. Roli. "Support vector machines under adversarial label contamination". Neurocomputing, Special Issue on Advances in Learning with Label Noise, In Press.
- "cchio/deep-pwning". GitHub. Retrieved 2016-08-08.
External links
- NIPS 2007 Workshop on Machine Learning in Adversarial Environments for Computer Security
- Special Issue on "Machine Learning in Adversarial Environments" in the journal of Machine Learning
- Dagstuhl Perspectives Workshop on "Machine Learning Methods for Computer Security"
- Workshop on Artificial Intelligence and Security, (AISec) Series
Differentiable computing | |||||||
|---|---|---|---|---|---|---|---|
| General |  | ||||||
| Concepts | |||||||
| Programming languages | |||||||
| Application |
| ||||||
| Hardware | |||||||
| Software library | |||||||
| Implementation |
| ||||||
| People | |||||||
| |||||||