Speech synthesis
Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech computer or speech synthesizer, and can be implemented in software or hardware products. A text-to-speech (TTS) system converts normal language text into speech; other systems render symbolic linguistic representations like phonetic transcriptions into speech.[1]
Synthesized speech can be created by concatenating pieces of recorded speech that are stored in a database. Systems differ in the size of the stored speech units; a system that stores phones or diphones provides the largest output range, but may lack clarity. For specific usage domains, the storage of entire words or sentences allows for high-quality output. Alternatively, a synthesizer can incorporate a model of the vocal tract and other human voice characteristics to create a completely "synthetic" voice output.[2]
The quality of a speech synthesizer is judged by its similarity to the human voice and by its ability to be understood clearly. An intelligible text-to-speech program allows people with visual impairments or reading disabilities to listen to written words on a home computer. Many computer operating systems have included speech synthesizers since the early 1990s.
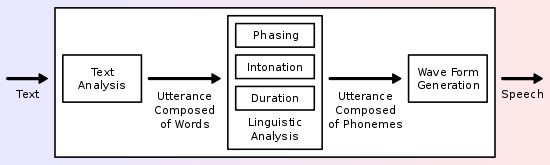
A text-to-speech system (or "engine") is composed of two parts:[3] a front-end and a back-end. The front-end has two major tasks. First, it converts raw text containing symbols like numbers and abbreviations into the equivalent of written-out words. This process is often called text normalization, pre-processing, or tokenization. The front-end then assigns phonetic transcriptions to each word, and divides and marks the text into prosodic units, like phrases, clauses, and sentences. The process of assigning phonetic transcriptions to words is called text-to-phoneme or grapheme-to-phoneme conversion. Phonetic transcriptions and prosody information together make up the symbolic linguistic representation that is output by the front-end. The back-end—often referred to as the synthesizer—then converts the symbolic linguistic representation into sound. In certain systems, this part includes the computation of the target prosody (pitch contour, phoneme durations),[4] which is then imposed on the output speech.
History
Long before the invention of electronic signal processing, some people tried to build machines to emulate human speech. Some early legends of the existence of "Brazen Heads" involved Pope Silvester II (d. 1003 AD), Albertus Magnus (1198–1280), and Roger Bacon (1214–1294).
In 1779 the German-Danish scientist Christian Gottlieb Kratzenstein won the first prize in a competition announced by the Russian Imperial Academy of Sciences and Arts for models he built of the human vocal tract that could produce the five long vowel sounds (in International Phonetic Alphabet notation: [aː], [eː], [iː], [oː] and [uː]).[5] There followed the bellows-operated "acoustic-mechanical speech machine" of Wolfgang von Kempelen of Pressburg, Hungary, described in a 1791 paper.[6] This machine added models of the tongue and lips, enabling it to produce consonants as well as vowels. In 1837, Charles Wheatstone produced a "speaking machine" based on von Kempelen's design, and in 1846, Joseph Faber exhibited the "Euphonia". In 1923 Paget resurrected Wheatstone's design.[7]
In the 1930s Bell Labs developed the vocoder, which automatically analyzed speech into its fundamental tones and resonances. From his work on the vocoder, Homer Dudley developed a keyboard-operated voice-synthesizer called The Voder (Voice Demonstrator), which he exhibited at the 1939 New York World's Fair.
Dr. Franklin S. Cooper and his colleagues at Haskins Laboratories built the Pattern playback in the late 1940s and completed it in 1950. There were several different versions of this hardware device; only one currently survives. The machine converts pictures of the acoustic patterns of speech in the form of a spectrogram back into sound. Using this device, Alvin Liberman and colleagues discovered acoustic cues for the perception of phonetic segments (consonants and vowels).
Electronic devices
.jpg)
The first computer-based speech-synthesis systems originated in the late 1950s. Noriko Umeda et al. developed the first general English text-to-speech system in 1968, at the Electrotechnical Laboratory in Japan.[8] In 1961, physicist John Larry Kelly, Jr and his colleague Louis Gerstman[9] used an IBM 704 computer to synthesize speech, an event among the most prominent in the history of Bell Labs. Kelly's voice recorder synthesizer (vocoder) recreated the song "Daisy Bell", with musical accompaniment from Max Mathews. Coincidentally, Arthur C. Clarke was visiting his friend and colleague John Pierce at the Bell Labs Murray Hill facility. Clarke was so impressed by the demonstration that he used it in the climactic scene of his screenplay for his novel 2001: A Space Odyssey,[10] where the HAL 9000 computer sings the same song as astronaut Dave Bowman puts it to sleep.[11] Despite the success of purely electronic speech synthesis, research into mechanical speech-synthesizers continues.[12]
Linear predictive coding (LPC), a form of speech coding, began development with the work of Fumitada Itakura of Nagoya University and Shuzo Saito of Nippon Telegraph and Telephone (NTT) in 1966. Further developments in LPC technology were made by Bishnu S. Atal and Manfred R. Schroeder at Bell Labs during the 1970s.[13] LPC was later the basis for early speech synthesizer chips, such as the Texas Instruments LPC Speech Chips used in the Speak & Spell toys from 1978.
In 1975, Fumitada Itakura developed the line spectral pairs (LSP) method for high-compression speech coding, while at NTT.[14][15][16] From 1975 to 1981, Itakura studied problems in speech analysis and synthesis based on the LSP method.[16] In 1980, his team developed an LSP-based speech synthesizer chip. LSP is an important technology for speech synthesis and coding, and in the 1990s was adopted by almost all international speech coding standards as an essential component, contributing to the enhancement of digital speech communication over mobile channels and the internet.[15]
In 1975, MUSA was released, and was one of the first Speech Synthesis systems. It consisted of a stand-alone computer hardware and a specialized software that enabled it to read Italian. A second version, released in 1978, was also able to sing Italian in an "a cappella" style.
Dominant systems in the 1980s and 1990s were the DECtalk system, based largely on the work of Dennis Klatt at MIT, and the Bell Labs system;[17] the latter was one of the first multilingual language-independent systems, making extensive use of natural language processing methods.
Handheld electronics featuring speech synthesis began emerging in the 1970s. One of the first was the Telesensory Systems Inc. (TSI) Speech+ portable calculator for the blind in 1976.[18][19] Other devices had primarily educational purposes, such as the Speak & Spell toy produced by Texas Instruments in 1978.[20] Fidelity released a speaking version of its electronic chess computer in 1979.[21] The first video game to feature speech synthesis was the 1980 shoot 'em up arcade game, Stratovox (known in Japan as Speak & Rescue), from Sun Electronics.[22] The first personal computer game with speech synthesis was Manbiki Shoujo (Shoplifting Girl), released in 1980 for the PET 2001, for which the game's developer, Hiroshi Suzuki, developed a "zero cross" programming technique to produce a synthesized speech waveform.[23] Another early example, the arcade version of Berzerk, also dates from 1980. The Milton Bradley Company produced the first multi-player electronic game using voice synthesis, Milton, in the same year.
Early electronic speech-synthesizers sounded robotic and were often barely intelligible. The quality of synthesized speech has steadily improved, but as of 2016 output from contemporary speech synthesis systems remains clearly distinguishable from actual human speech.
Kurzweil predicted in 2005 that as the cost-performance ratio caused speech synthesizers to become cheaper and more accessible, more people would benefit from the use of text-to-speech programs.[24]
Synthesizer technologies
The most important qualities of a speech synthesis system are naturalness and intelligibility.[25] Naturalness describes how closely the output sounds like human speech, while intelligibility is the ease with which the output is understood. The ideal speech synthesizer is both natural and intelligible. Speech synthesis systems usually try to maximize both characteristics.
The two primary technologies generating synthetic speech waveforms are concatenative synthesis and formant synthesis. Each technology has strengths and weaknesses, and the intended uses of a synthesis system will typically determine which approach is used.
Concatenation synthesis
Concatenative synthesis is based on the concatenation (or stringing together) of segments of recorded speech. Generally, concatenative synthesis produces the most natural-sounding synthesized speech. However, differences between natural variations in speech and the nature of the automated techniques for segmenting the waveforms sometimes result in audible glitches in the output. There are three main sub-types of concatenative synthesis.
Unit selection synthesis
Unit selection synthesis uses large databases of recorded speech. During database creation, each recorded utterance is segmented into some or all of the following: individual phones, diphones, half-phones, syllables, morphemes, words, phrases, and sentences. Typically, the division into segments is done using a specially modified speech recognizer set to a "forced alignment" mode with some manual correction afterward, using visual representations such as the waveform and spectrogram.[26] An index of the units in the speech database is then created based on the segmentation and acoustic parameters like the fundamental frequency (pitch), duration, position in the syllable, and neighboring phones. At run time, the desired target utterance is created by determining the best chain of candidate units from the database (unit selection). This process is typically achieved using a specially weighted decision tree.
Unit selection provides the greatest naturalness, because it applies only a small amount of digital signal processing (DSP) to the recorded speech. DSP often makes recorded speech sound less natural, although some systems use a small amount of signal processing at the point of concatenation to smooth the waveform. The output from the best unit-selection systems is often indistinguishable from real human voices, especially in contexts for which the TTS system has been tuned. However, maximum naturalness typically require unit-selection speech databases to be very large, in some systems ranging into the gigabytes of recorded data, representing dozens of hours of speech.[27] Also, unit selection algorithms have been known to select segments from a place that results in less than ideal synthesis (e.g. minor words become unclear) even when a better choice exists in the database.[28] Recently, researchers have proposed various automated methods to detect unnatural segments in unit-selection speech synthesis systems.[29]
Diphone synthesis
Diphone synthesis uses a minimal speech database containing all the diphones (sound-to-sound transitions) occurring in a language. The number of diphones depends on the phonotactics of the language: for example, Spanish has about 800 diphones, and German about 2500. In diphone synthesis, only one example of each diphone is contained in the speech database. At runtime, the target prosody of a sentence is superimposed on these minimal units by means of digital signal processing techniques such as linear predictive coding, PSOLA[30] or MBROLA.[31] or more recent techniques such as pitch modification in the source domain using discrete cosine transform.[32] Diphone synthesis suffers from the sonic glitches of concatenative synthesis and the robotic-sounding nature of formant synthesis, and has few of the advantages of either approach other than small size. As such, its use in commercial applications is declining, although it continues to be used in research because there are a number of freely available software implementations. An early example of Diphone synthesis is a teaching robot, leachim, that was invented by Michael J. Freeman.[33] Leachim contained information regarding class curricular and certain biographical information about the 40 students whom it was programmed to teach.[34] It was tested in a fourth grade classroom in the Bronx, New York.[35][36]
Domain-specific synthesis
Domain-specific synthesis concatenates prerecorded words and phrases to create complete utterances. It is used in applications where the variety of texts the system will output is limited to a particular domain, like transit schedule announcements or weather reports.[37] The technology is very simple to implement, and has been in commercial use for a long time, in devices like talking clocks and calculators. The level of naturalness of these systems can be very high because the variety of sentence types is limited, and they closely match the prosody and intonation of the original recordings.
Because these systems are limited by the words and phrases in their databases, they are not general-purpose and can only synthesize the combinations of words and phrases with which they have been preprogrammed. The blending of words within naturally spoken language however can still cause problems unless the many variations are taken into account. For example, in non-rhotic dialects of English the "r" in words like "clear" /ˈklɪə/ is usually only pronounced when the following word has a vowel as its first letter (e.g. "clear out" is realized as /ˌklɪəɹˈʌʊt/). Likewise in French, many final consonants become no longer silent if followed by a word that begins with a vowel, an effect called liaison. This alternation cannot be reproduced by a simple word-concatenation system, which would require additional complexity to be context-sensitive.
Formant synthesis
Formant synthesis does not use human speech samples at runtime. Instead, the synthesized speech output is created using additive synthesis and an acoustic model (physical modelling synthesis).[38] Parameters such as fundamental frequency, voicing, and noise levels are varied over time to create a waveform of artificial speech. This method is sometimes called rules-based synthesis; however, many concatenative systems also have rules-based components. Many systems based on formant synthesis technology generate artificial, robotic-sounding speech that would never be mistaken for human speech. However, maximum naturalness is not always the goal of a speech synthesis system, and formant synthesis systems have advantages over concatenative systems. Formant-synthesized speech can be reliably intelligible, even at very high speeds, avoiding the acoustic glitches that commonly plague concatenative systems. High-speed synthesized speech is used by the visually impaired to quickly navigate computers using a screen reader. Formant synthesizers are usually smaller programs than concatenative systems because they do not have a database of speech samples. They can therefore be used in embedded systems, where memory and microprocessor power are especially limited. Because formant-based systems have complete control of all aspects of the output speech, a wide variety of prosodies and intonations can be output, conveying not just questions and statements, but a variety of emotions and tones of voice.
Examples of non-real-time but highly accurate intonation control in formant synthesis include the work done in the late 1970s for the Texas Instruments toy Speak & Spell, and in the early 1980s Sega arcade machines[39] and in many Atari, Inc. arcade games[40] using the TMS5220 LPC Chips. Creating proper intonation for these projects was painstaking, and the results have yet to be matched by real-time text-to-speech interfaces.[41]
Articulatory synthesis
Articulatory synthesis refers to computational techniques for synthesizing speech based on models of the human vocal tract and the articulation processes occurring there. The first articulatory synthesizer regularly used for laboratory experiments was developed at Haskins Laboratories in the mid-1970s by Philip Rubin, Tom Baer, and Paul Mermelstein. This synthesizer, known as ASY, was based on vocal tract models developed at Bell Laboratories in the 1960s and 1970s by Paul Mermelstein, Cecil Coker, and colleagues.
Until recently, articulatory synthesis models have not been incorporated into commercial speech synthesis systems. A notable exception is the NeXT-based system originally developed and marketed by Trillium Sound Research, a spin-off company of the University of Calgary, where much of the original research was conducted. Following the demise of the various incarnations of NeXT (started by Steve Jobs in the late 1980s and merged with Apple Computer in 1997), the Trillium software was published under the GNU General Public License, with work continuing as gnuspeech. The system, first marketed in 1994, provides full articulatory-based text-to-speech conversion using a waveguide or transmission-line analog of the human oral and nasal tracts controlled by Carré's "distinctive region model".
More recent synthesizers, developed by Jorge C. Lucero and colleagues, incorporate models of vocal fold biomechanics, glottal aerodynamics and acoustic wave propagation in the bronqui, traquea, nasal and oral cavities, and thus constitute full systems of physics-based speech simulation.[42][43]
HMM-based synthesis
HMM-based synthesis is a synthesis method based on hidden Markov models, also called Statistical Parametric Synthesis. In this system, the frequency spectrum (vocal tract), fundamental frequency (voice source), and duration (prosody) of speech are modeled simultaneously by HMMs. Speech waveforms are generated from HMMs themselves based on the maximum likelihood criterion.[44]
Sinewave synthesis
Sinewave synthesis is a technique for synthesizing speech by replacing the formants (main bands of energy) with pure tone whistles.[45]
Deep learning-based Synthesis
Formulation
Given an input text or some sequence of linguistic unit , the target speech can be derived by



where is the model parameter.

Typically, the input text will first be passed to an acoustic feature generator, then the acoustic features are passed to the neural vocoder. For the acoustic feature generator, the Loss function is typically L1 or L2 loss. These loss functions put a constraint that the output acoustic feature distributions must be Gaussian or Laplacian. In practice, since the human voice band ranges from approximately 300 to 4000 Hz, the loss function will be designed to have more penality on this range:

where is the loss from human voice band and is a scalar typically around 0.5. The acoustic feature is typically Spectrogram or spectrogram in Mel scale. These features capture the time-frequency relation of speech signal and thus, it is sufficient to generate intelligent outputs with these acoustic features. The Mel-frequency cepstrum feature used in the speech recognition task is not suitable for speech synthesis because it reduces too much information.


Brief History
In September 2016, DeepMind proposed WaveNet, a deep generative model of raw audio waveforms. This shows the community that deep learning-based models have the capability to model raw waveforms and perform well on generating speech from acoustic features like spectrograms or spectrograms in mel scale, or even from some preprocessed linguistic features. In early 2017, Mila (research institute) proposed char2wav, a model to produce raw waveform in an end-to-end method. Also, Google and Facebook proposed Tacotron and VoiceLoop, respectively, to generate acoustic features directly from the input text. In the later in the same year, Google proposed Tacotron2 which combined the WaveNet vocoder with the revised Tacotron architecture to perform end-to-end speech synthesis. Tacotron2 can generate high-quality speech approaching the human voice. Since then, end-to-end methods became the hottest research topic because many researchers around the world start to notice the power of the end-to-end speech synthesizer.
Advantages and Disadvantages
The advantages of end-to-end methods are as follows:
- Only need a single model to perform text analysis, acoustic modeling and audio synthesis, i.e. synthesizing speech directly from characters
- Less feature engineering
- Easily allows for rich conditioning on various attributes, e.g. speaker or language
- Adaptation to new data is easier
- More robust than multi-stage models because no component's error can compound
- Powerful model capacity to capture the hidden internal structures of data
- Capable to generate intelligible and natural speech
- No need to maintain a large database, i.e. small footprint
Despite the many advantages mentioned, end-to-end methods still have many challenges to be solved:
- Auto-regressive-based models suffer from slow inference problem
- Output speech are not robust when data are not sufficient
- Lack of controllability compared with traditional concatenative and statistical parametric approaches
- Tend to learn the flat prosody by averaging over training data
- Tend to output smoothed acoustic features because the l1 or l2 loss is used
Challenges
- Slow inference problem
To solve the slow inference problem, Microsoft research and Baidu research both proposed using non-auto-regressive models to make the inference process faster. The FastSpeech model proposed by Microsoft use Transformer architecture with a duration model to achieve the goal. Besides, the duration model which borrows from traditional methods makes the speech production more robust.
- Robustness problem
Researchers found that the robustness problem is strongly related to the text alignment failures, and this drives many researchers to revise the attention mechanism which utilize the strong local relation and monotonic properties of speech.
- Controllability problem
To solve the controllability problem, many works about variational auto-encoder are proposed.[46][47]
- Flat prosody problem
GST-Tacotron can slightly alleviate the flat prosody problem, however, it still depends on the training data.
- Smoothed acoustic output problem
To generate more realistic acoustic features, GAN learning strategy can be applied.
However, in practice, neural vocoder can generalize well even when the input features are more smooth than real data.
Semi-supervised Learning
Currently, self-supervised learning gain a lot of attention because of better utilizing unlabelled data. Research [48][49] shows that with the aid of self-supervised loss, the need of paired data decreases.
Zero-shot Speaker Adaptation
Zero-shot speaker adaptation is promising because a single model can generate speech with various speaker styles and characteristic. In June 2018, Google proposed to use pre-trained speaker verification model as speaker encoder to extract speaker embedding [50]. The speaker encoder then becomes a part of the neural text-to-speech model and it can decide the style and characteristic of the output speech. This shows the community that only using a single model to generate speech of multiple style is possible.
Neural Vocoder
Neural vocoder plays a important role in deep learning-based speech synthesis to generate high-quality speech from acoustic features. The WaveNet model proposed in 2016 achieves great performance on speech quality. Wavenet factorised the joint probability of a waveform as a product of conditional probabilities as follows


Where is the model parameter including many dilated convolution layers. Therefore, each audio sample is therefore conditioned on the samples at all previous timesteps. However, the auto-regressive nature of WaveNet makes the inference process dramatically slow. To solve the slow inference problem that comes from the auto-regressive characteristic of WaveNet model, Parallel WaveNet[51] is proposed. Parallel WaveNet is an inverse autoregressive flow-based model which is trained by knowledge distillation with a pre-trained teacher WaveNet model. Since inverse autoregressive flow-based model is non-auto-regressive when performing inference, the inference speed is faster than real-time. In the meanwhile, Nvidia proposed a flow-based WaveGlow [52] model which can also generate speech with faster than real-time speed. However, despite the high inference speed, parallel WaveNet has the limitation of the need of a pre-trained WaveNet model and WaveGlow takes many weeks to converge with limited computing devices. This issue is solved by Parallel WaveGAN [53] which learns to produce speech by multi-resolution spectral loss and GANs learning strategy.

Challenges
Text normalization challenges
The process of normalizing text is rarely straightforward. Texts are full of heteronyms, numbers, and abbreviations that all require expansion into a phonetic representation. There are many spellings in English which are pronounced differently based on context. For example, "My latest project is to learn how to better project my voice" contains two pronunciations of "project".
Most text-to-speech (TTS) systems do not generate semantic representations of their input texts, as processes for doing so are unreliable, poorly understood, and computationally ineffective. As a result, various heuristic techniques are used to guess the proper way to disambiguate homographs, like examining neighboring words and using statistics about frequency of occurrence.
Recently TTS systems have begun to use HMMs (discussed above) to generate "parts of speech" to aid in disambiguating homographs. This technique is quite successful for many cases such as whether "read" should be pronounced as "red" implying past tense, or as "reed" implying present tense. Typical error rates when using HMMs in this fashion are usually below five percent. These techniques also work well for most European languages, although access to required training corpora is frequently difficult in these languages.
Deciding how to convert numbers is another problem that TTS systems have to address. It is a simple programming challenge to convert a number into words (at least in English), like "1325" becoming "one thousand three hundred twenty-five." However, numbers occur in many different contexts; "1325" may also be read as "one three two five", "thirteen twenty-five" or "thirteen hundred and twenty five". A TTS system can often infer how to expand a number based on surrounding words, numbers, and punctuation, and sometimes the system provides a way to specify the context if it is ambiguous.[54] Roman numerals can also be read differently depending on context. For example, "Henry VIII" reads as "Henry the Eighth", while "Chapter VIII" reads as "Chapter Eight".
Similarly, abbreviations can be ambiguous. For example, the abbreviation "in" for "inches" must be differentiated from the word "in", and the address "12 St John St." uses the same abbreviation for both "Saint" and "Street". TTS systems with intelligent front ends can make educated guesses about ambiguous abbreviations, while others provide the same result in all cases, resulting in nonsensical (and sometimes comical) outputs, such as "Ulysses S. Grant" being rendered as "Ulysses South Grant".
Text-to-phoneme challenges
Speech synthesis systems use two basic approaches to determine the pronunciation of a word based on its spelling, a process which is often called text-to-phoneme or grapheme-to-phoneme conversion (phoneme is the term used by linguists to describe distinctive sounds in a language). The simplest approach to text-to-phoneme conversion is the dictionary-based approach, where a large dictionary containing all the words of a language and their correct pronunciations is stored by the program. Determining the correct pronunciation of each word is a matter of looking up each word in the dictionary and replacing the spelling with the pronunciation specified in the dictionary. The other approach is rule-based, in which pronunciation rules are applied to words to determine their pronunciations based on their spellings. This is similar to the "sounding out", or synthetic phonics, approach to learning reading.
Each approach has advantages and drawbacks. The dictionary-based approach is quick and accurate, but completely fails if it is given a word which is not in its dictionary. As dictionary size grows, so too does the memory space requirements of the synthesis system. On the other hand, the rule-based approach works on any input, but the complexity of the rules grows substantially as the system takes into account irregular spellings or pronunciations. (Consider that the word "of" is very common in English, yet is the only word in which the letter "f" is pronounced [v].) As a result, nearly all speech synthesis systems use a combination of these approaches.
Languages with a phonemic orthography have a very regular writing system, and the prediction of the pronunciation of words based on their spellings is quite successful. Speech synthesis systems for such languages often use the rule-based method extensively, resorting to dictionaries only for those few words, like foreign names and borrowings, whose pronunciations are not obvious from their spellings. On the other hand, speech synthesis systems for languages like English, which have extremely irregular spelling systems, are more likely to rely on dictionaries, and to use rule-based methods only for unusual words, or words that aren't in their dictionaries.
Evaluation challenges
The consistent evaluation of speech synthesis systems may be difficult because of a lack of universally agreed objective evaluation criteria. Different organizations often use different speech data. The quality of speech synthesis systems also depends on the quality of the production technique (which may involve analogue or digital recording) and on the facilities used to replay the speech. Evaluating speech synthesis systems has therefore often been compromised by differences between production techniques and replay facilities.
Since 2005, however, some researchers have started to evaluate speech synthesis systems using a common speech dataset.[55]
Prosodics and emotional content
A study in the journal Speech Communication by Amy Drahota and colleagues at the University of Portsmouth, UK, reported that listeners to voice recordings could determine, at better than chance levels, whether or not the speaker was smiling.[56][57][58] It was suggested that identification of the vocal features that signal emotional content may be used to help make synthesized speech sound more natural. One of the related issues is modification of the pitch contour of the sentence, depending upon whether it is an affirmative, interrogative or exclamatory sentence. One of the techniques for pitch modification[59] uses discrete cosine transform in the source domain (linear prediction residual). Such pitch synchronous pitch modification techniques need a priori pitch marking of the synthesis speech database using techniques such as epoch extraction using dynamic plosion index applied on the integrated linear prediction residual of the voiced regions of speech.[60]
Dedicated hardware
- Icophone
- General Instrument SP0256-AL2
- National Semiconductor DT1050 Digitalker (Mozer – Forrest Mozer)
- Texas Instruments LPC Speech Chips[61]
Hardware and software systems
Popular systems offering speech synthesis as a built-in capability.
Mattel
The Mattel Intellivision game console offered the Intellivoice Voice Synthesis module in 1982. It included the SP0256 Narrator speech synthesizer chip on a removable cartridge. The Narrator had 2kB of Read-Only Memory (ROM), and this was utilized to store a database of generic words that could be combined to make phrases in Intellivision games. Since the Orator chip could also accept speech data from external memory, any additional words or phrases needed could be stored inside the cartridge itself. The data consisted of strings of analog-filter coefficients to modify the behavior of the chip's synthetic vocal-tract model, rather than simple digitized samples.
SAM
Also released in 1982, Software Automatic Mouth was the first commercial all-software voice synthesis program. It was later used as the basis for Macintalk. The program was available for non-Macintosh Apple computers (including the Apple II, and the Lisa), various Atari models and the Commodore 64. The Apple version preferred additional hardware that contained DACs, although it could instead use the computer's one-bit audio output (with the addition of much distortion) if the card was not present. The Atari made use of the embedded POKEY audio chip. Speech playback on the Atari normally disabled interrupt requests and shut down the ANTIC chip during vocal output. The audible output is extremely distorted speech when the screen is on. The Commodore 64 made use of the 64's embedded SID audio chip.
Atari
Arguably, the first speech system integrated into an operating system was the 1400XL/1450XL personal computers designed by Atari, Inc. using the Votrax SC01 chip in 1983. The 1400XL/1450XL computers used a Finite State Machine to enable World English Spelling text-to-speech synthesis.[62] Unfortunately, the 1400XL/1450XL personal computers never shipped in quantity.
The Atari ST computers were sold with "stspeech.tos" on floppy disk.
Apple
The first speech system integrated into an operating system that shipped in quantity was Apple Computer's MacInTalk. The software was licensed from 3rd party developers Joseph Katz and Mark Barton (later, SoftVoice, Inc.) and was featured during the 1984 introduction of the Macintosh computer. This January demo required 512 kilobytes of RAM memory. As a result, it could not run in the 128 kilobytes of RAM the first Mac actually shipped with.[63] So, the demo was accomplished with a prototype 512k Mac, although those in attendance were not told of this and the synthesis demo created considerable excitement for the Macintosh. In the early 1990s Apple expanded its capabilities offering system wide text-to-speech support. With the introduction of faster PowerPC-based computers they included higher quality voice sampling. Apple also introduced speech recognition into its systems which provided a fluid command set. More recently, Apple has added sample-based voices. Starting as a curiosity, the speech system of Apple Macintosh has evolved into a fully supported program, PlainTalk, for people with vision problems. VoiceOver was for the first time featured in 2005 in Mac OS X Tiger (10.4). During 10.4 (Tiger) and first releases of 10.5 (Leopard) there was only one standard voice shipping with Mac OS X. Starting with 10.6 (Snow Leopard), the user can choose out of a wide range list of multiple voices. VoiceOver voices feature the taking of realistic-sounding breaths between sentences, as well as improved clarity at high read rates over PlainTalk. Mac OS X also includes say, a command-line based application that converts text to audible speech. The AppleScript Standard Additions includes a say verb that allows a script to use any of the installed voices and to control the pitch, speaking rate and modulation of the spoken text.
The Apple iOS operating system used on the iPhone, iPad and iPod Touch uses VoiceOver speech synthesis for accessibility.[64] Some third party applications also provide speech synthesis to facilitate navigating, reading web pages or translating text.
Amazon
Used in Alexa and as Software as a Service in AWS[65] (from 2017).
AmigaOS
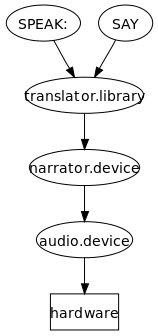
The second operating system to feature advanced speech synthesis capabilities was AmigaOS, introduced in 1985. The voice synthesis was licensed by Commodore International from SoftVoice, Inc., who also developed the original MacinTalk text-to-speech system. It featured a complete system of voice emulation for American English, with both male and female voices and "stress" indicator markers, made possible through the Amiga's audio chipset.[66] The synthesis system was divided into a translator library which converted unrestricted English text into a standard set of phonetic codes and a narrator device which implemented a formant model of speech generation.. AmigaOS also featured a high-level "Speak Handler", which allowed command-line users to redirect text output to speech. Speech synthesis was occasionally used in third-party programs, particularly word processors and educational software. The synthesis software remained largely unchanged from the first AmigaOS release and Commodore eventually removed speech synthesis support from AmigaOS 2.1 onward.
Despite the American English phoneme limitation, an unofficial version with multilingual speech synthesis was developed. This made use of an enhanced version of the translator library which could translate a number of languages, given a set of rules for each language.[67]
Microsoft Windows
Modern Windows desktop systems can use SAPI 4 and SAPI 5 components to support speech synthesis and speech recognition. SAPI 4.0 was available as an optional add-on for Windows 95 and Windows 98. Windows 2000 added Narrator, a text-to-speech utility for people who have visual impairment. Third-party programs such as JAWS for Windows, Window-Eyes, Non-visual Desktop Access, Supernova and System Access can perform various text-to-speech tasks such as reading text aloud from a specified website, email account, text document, the Windows clipboard, the user's keyboard typing, etc. Not all programs can use speech synthesis directly.[68] Some programs can use plug-ins, extensions or add-ons to read text aloud. Third-party programs are available that can read text from the system clipboard.
Microsoft Speech Server is a server-based package for voice synthesis and recognition. It is designed for network use with web applications and call centers.
Texas Instruments TI-99/4A
In the early 1980s, TI was known as a pioneer in speech synthesis, and a highly popular plug-in speech synthesizer module was available for the TI-99/4 and 4A. Speech synthesizers were offered free with the purchase of a number of cartridges and were used by many TI-written video games (notable titles offered with speech during this promotion were Alpiner and Parsec). The synthesizer uses a variant of linear predictive coding and has a small in-built vocabulary. The original intent was to release small cartridges that plugged directly into the synthesizer unit, which would increase the device's built-in vocabulary. However, the success of software text-to-speech in the Terminal Emulator II cartridge canceled that plan.
Text-to-speech systems
Text-to-Speech (TTS) refers to the ability of computers to read text aloud. A TTS Engine converts written text to a phonemic representation, then converts the phonemic representation to waveforms that can be output as sound. TTS engines with different languages, dialects and specialized vocabularies are available through third-party publishers.[69]
Internet
Currently, there are a number of applications, plugins and gadgets that can read messages directly from an e-mail client and web pages from a web browser or Google Toolbar. Some specialized software can narrate RSS-feeds. On one hand, online RSS-narrators simplify information delivery by allowing users to listen to their favourite news sources and to convert them to podcasts. On the other hand, on-line RSS-readers are available on almost any PC connected to the Internet. Users can download generated audio files to portable devices, e.g. with a help of podcast receiver, and listen to them while walking, jogging or commuting to work.
A growing field in Internet based TTS is web-based assistive technology, e.g. 'Browsealoud' from a UK company and Readspeaker. It can deliver TTS functionality to anyone (for reasons of accessibility, convenience, entertainment or information) with access to a web browser. The non-profit project Pediaphon was created in 2006 to provide a similar web-based TTS interface to the Wikipedia.[71]
Other work is being done in the context of the W3C through the W3C Audio Incubator Group with the involvement of The BBC and Google Inc.
Open source
Some open-source software systems are available, such as:
- Festival Speech Synthesis System which uses diphone-based synthesis, as well as more modern and better-sounding techniques.
- eSpeak which supports a broad range of languages.
- gnuspeech which uses articulatory synthesis[72] from the Free Software Foundation.
Others
- Following the commercial failure of the hardware-based Intellivoice, gaming developers sparingly used software synthesis in later games. Earlier systems from Atari, such as the Atari 5200 (Baseball) and the Atari 2600 (Quadrun and Open Sesame), also had games utilizing software synthesis.
- Some e-book readers, such as the Amazon Kindle, Samsung E6, PocketBook eReader Pro, enTourage eDGe, and the Bebook Neo.
- The BBC Micro incorporated the Texas Instruments TMS5220 speech synthesis chip,
- Some models of Texas Instruments home computers produced in 1979 and 1981 (Texas Instruments TI-99/4 and TI-99/4A) were capable of text-to-phoneme synthesis or reciting complete words and phrases (text-to-dictionary), using a very popular Speech Synthesizer peripheral. TI used a proprietary codec to embed complete spoken phrases into applications, primarily video games.[73]
- IBM's OS/2 Warp 4 included VoiceType, a precursor to IBM ViaVoice.
- GPS Navigation units produced by Garmin, Magellan, TomTom and others use speech synthesis for automobile navigation.
- Yamaha produced a music synthesizer in 1999, the Yamaha FS1R which included a Formant synthesis capability. Sequences of up to 512 individual vowel and consonant formants could be stored and replayed, allowing short vocal phrases to be synthesized.
Digital sound-alikes
With the 2016 introduction of Adobe Voco audio editing and generating software prototype slated to be part of the Adobe Creative Suite and the similarly enabled DeepMind WaveNet, a deep neural network based audio synthesis software from Google [74] speech synthesis is verging on being completely indistinguishable from a real human's voice.
Adobe Voco takes approximately 20 minutes of the desired target's speech and after that it can generate sound-alike voice with even phonemes that were not present in the training material. The software poses ethical concerns as it allows to steal other peoples voices and manipulate them to say anything desired.[75]
At the 2018 Conference on Neural Information Processing Systems (NeurIPS) researchers from Google presented the work 'Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis', which transfers learning from speaker verification to achieve text-to-speech synthesis, that can be made to sound almost like anybody from a speech sample of only 5 seconds (listen). [76]
Also researchers from Baidu Research presented an voice cloning system with similar aims at the 2018 NeurIPS conference[77], though the result is rather unconvincing. (listen)
By 2019 the digital sound-alikes found their way to the hands of criminals as Symantec researchers know of 3 cases where digital sound-alikes technology has been used for crime.[78][79]
This increases the stress on the disinformation situation coupled with the facts that
- Human image synthesis since the early 2000s has improved beyond the point of human's inability to tell a real human imaged with a real camera from a simulation of a human imaged with a simulation of a camera.
- 2D video forgery techniques were presented in 2016 that allow near real-time counterfeiting of facial expressions in existing 2D video.[80]
- In SIGGRAPH 2017 an audio driven digital look-alike of upper torso of Barack Obama was presented by researchers from University of Washington. (view) It was driven only by a voice track as source data for the animation after the training phase to acquire lip sync and wider facial information from training material consisting of 2D videos with audio had been completed.[81]
In March 2020, a freeware web application that generates high-quality voices from an assortment of fictional characters from a variety of media sources called 15.ai was released.[82] Initial characters included GLaDOS from Portal, Twilight Sparkle and Fluttershy from the show My Little Pony: Friendship Is Magic, and the Tenth Doctor from Doctor Who. Subsequent updates included Wheatley from Portal 2, the Soldier from Team Fortress 2, and the remaining main cast of My Little Pony: Friendship Is Magic.[83] [84]
Speech synthesis markup languages
A number of markup languages have been established for the rendition of text as speech in an XML-compliant format. The most recent is Speech Synthesis Markup Language (SSML), which became a W3C recommendation in 2004. Older speech synthesis markup languages include Java Speech Markup Language (JSML) and SABLE. Although each of these was proposed as a standard, none of them have been widely adopted.
Speech synthesis markup languages are distinguished from dialogue markup languages. VoiceXML, for example, includes tags related to speech recognition, dialogue management and touchtone dialing, in addition to text-to-speech markup.
Applications
Speech synthesis has long been a vital assistive technology tool and its application in this area is significant and widespread. It allows environmental barriers to be removed for people with a wide range of disabilities. The longest application has been in the use of screen readers for people with visual impairment, but text-to-speech systems are now commonly used by people with dyslexia and other reading difficulties as well as by pre-literate children. They are also frequently employed to aid those with severe speech impairment usually through a dedicated voice output communication aid.
Speech synthesis techniques are also used in entertainment productions such as games and animations. In 2007, Animo Limited announced the development of a software application package based on its speech synthesis software FineSpeech, explicitly geared towards customers in the entertainment industries, able to generate narration and lines of dialogue according to user specifications.[85] The application reached maturity in 2008, when NEC Biglobe announced a web service that allows users to create phrases from the voices of Code Geass: Lelouch of the Rebellion R2 characters.[86]
In recent years, text-to-speech for disability and handicapped communication aids have become widely deployed in Mass Transit. Text-to-speech is also finding new applications outside the disability market. For example, speech synthesis, combined with speech recognition, allows for interaction with mobile devices via natural language processing interfaces.
Text-to-speech is also used in second language acquisition. Voki, for instance, is an educational tool created by Oddcast that allows users to create their own talking avatar, using different accents. They can be emailed, embedded on websites or shared on social media.
In addition, speech synthesis is a valuable computational aid for the analysis and assessment of speech disorders. A voice quality synthesizer, developed by Jorge C. Lucero et al. at University of Brasilia, simulates the physics of phonation and includes models of vocal frequency jitter and tremor, airflow noise and laryngeal asymmetries.[42] The synthesizer has been used to mimic the timbre of dysphonic speakers with controlled levels of roughness, breathiness and strain.[43]

See also
References
- Allen, Jonathan; Hunnicutt, M. Sharon; Klatt, Dennis (1987). From Text to Speech: The MITalk system. Cambridge University Press. ISBN 978-0-521-30641-6.
- Rubin, P.; Baer, T.; Mermelstein, P. (1981). "An articulatory synthesizer for perceptual research". Journal of the Acoustical Society of America. 70 (2): 321–328. Bibcode:1981ASAJ...70..321R. doi:10.1121/1.386780.
- van Santen, Jan P. H.; Sproat, Richard W.; Olive, Joseph P.; Hirschberg, Julia (1997). Progress in Speech Synthesis. Springer. ISBN 978-0-387-94701-3.
- Van Santen, J. (April 1994). "Assignment of segmental duration in text-to-speech synthesis". Computer Speech & Language. 8 (2): 95–128. doi:10.1006/csla.1994.1005.
- History and Development of Speech Synthesis, Helsinki University of Technology, Retrieved on November 4, 2006
- Mechanismus der menschlichen Sprache nebst der Beschreibung seiner sprechenden Maschine ("Mechanism of the human speech with description of its speaking machine", J. B. Degen, Wien). (in German)
- Mattingly, Ignatius G. (1974). Sebeok, Thomas A. (ed.). "Speech synthesis for phonetic and phonological models" (PDF). Current Trends in Linguistics. Mouton, The Hague. 12: 2451–2487. Archived from the original (PDF) on 2013-05-12. Retrieved 2011-12-13.
- Klatt, D (1987). "Review of text-to-speech conversion for English". Journal of the Acoustical Society of America. 82 (3): 737–93. Bibcode:1987ASAJ...82..737K. doi:10.1121/1.395275. PMID 2958525.
- Lambert, Bruce (March 21, 1992). "Louis Gerstman, 61, a Specialist In Speech Disorders and Processes". New York Times.
- "Arthur C. Clarke Biography". Archived from the original on December 11, 1997. Retrieved 5 December 2017.
- "Where "HAL" First Spoke (Bell Labs Speech Synthesis website)". Bell Labs. Archived from the original on 2000-04-07. Retrieved 2010-02-17.
- Anthropomorphic Talking Robot Waseda-Talker Series Archived 2016-03-04 at the Wayback Machine
- Gray, Robert M. (2010). "A History of Realtime Digital Speech on Packet Networks: Part II of Linear Predictive Coding and the Internet Protocol" (PDF). Found. Trends Signal Process. 3 (4): 203–303. doi:10.1561/2000000036. ISSN 1932-8346.
- Zheng, F.; Song, Z.; Li, L.; Yu, W. (1998). "The Distance Measure for Line Spectrum Pairs Applied to Speech Recognition" (PDF). Proceedings of the 5th International Conference on Spoken Language Processing (ICSLP'98) (3): 1123–6.
- "List of IEEE Milestones". IEEE. Retrieved 15 July 2019.
- "Fumitada Itakura Oral History". IEEE Global History Network. 20 May 2009. Retrieved 2009-07-21.
- Sproat, Richard W. (1997). Multilingual Text-to-Speech Synthesis: The Bell Labs Approach. Springer. ISBN 978-0-7923-8027-6.
- [TSI Speech+ & other speaking calculators]
- Gevaryahu, Jonathan, [ "TSI S14001A Speech Synthesizer LSI Integrated Circuit Guide"]
- Breslow, et al. US 4326710: "Talking electronic game", April 27, 1982
- Voice Chess Challenger
- Gaming's most important evolutions Archived 2011-06-15 at the Wayback Machine, GamesRadar
- Szczepaniak, John (2014). The Untold History of Japanese Game Developers. 1. SMG Szczepaniak. pp. 544–615. ISBN 978-0992926007.
- Kurzweil, Raymond (2005). The Singularity is Near. Penguin Books. ISBN 978-0-14-303788-0.
- Taylor, Paul (2009). Text-to-speech synthesis. Cambridge, UK: Cambridge University Press. p. 3. ISBN 9780521899277.
- Alan W. Black, Perfect synthesis for all of the people all of the time. IEEE TTS Workshop 2002.
- John Kominek and Alan W. Black. (2003). CMU ARCTIC databases for speech synthesis. CMU-LTI-03-177. Language Technologies Institute, School of Computer Science, Carnegie Mellon University.
- Julia Zhang. Language Generation and Speech Synthesis in Dialogues for Language Learning, masters thesis, Section 5.6 on page 54.
- William Yang Wang and Kallirroi Georgila. (2011). Automatic Detection of Unnatural Word-Level Segments in Unit-Selection Speech Synthesis, IEEE ASRU 2011.
- "Pitch-Synchronous Overlap and Add (PSOLA) Synthesis". Archived from the original on February 22, 2007. Retrieved 2008-05-28.CS1 maint: BOT: original-url status unknown (link)
- T. Dutoit, V. Pagel, N. Pierret, F. Bataille, O. van der Vrecken. The MBROLA Project: Towards a set of high quality speech synthesizers of use for non commercial purposes. ICSLP Proceedings, 1996.
- Muralishankar, R; Ramakrishnan, A.G.; Prathibha, P (2004). "Modification of Pitch using DCT in the Source Domain". Speech Communication. 42 (2): 143–154. doi:10.1016/j.specom.2003.05.001.
- "Education: Marvel of The Bronx". Time. 1974-04-01. ISSN 0040-781X. Retrieved 2019-05-28.
- "1960 - Rudy the Robot - Michael Freeman (American)". cyberneticzoo.com. 2010-09-13. Retrieved 2019-05-23.
- LLC, New York Media (1979-07-30). New York Magazine. New York Media, LLC.
- The Futurist. World Future Society. 1978. pp. 359, 360, 361.
- L.F. Lamel, J.L. Gauvain, B. Prouts, C. Bouhier, R. Boesch. Generation and Synthesis of Broadcast Messages, Proceedings ESCA-NATO Workshop and Applications of Speech Technology, September 1993.
- Dartmouth College: Music and Computers Archived 2011-06-08 at the Wayback Machine, 1993.
- Examples include Astro Blaster, Space Fury, and Star Trek: Strategic Operations Simulator
- Examples include Star Wars, Firefox, Return of the Jedi, Road Runner, The Empire Strikes Back, Indiana Jones and the Temple of Doom, 720°, Gauntlet, Gauntlet II, A.P.B., Paperboy, RoadBlasters, Vindicators Part II, Escape from the Planet of the Robot Monsters.
- John Holmes and Wendy Holmes (2001). Speech Synthesis and Recognition (2nd ed.). CRC. ISBN 978-0-7484-0856-6.
- Lucero, J. C.; Schoentgen, J.; Behlau, M. (2013). "Physics-based synthesis of disordered voices" (PDF). Interspeech 2013. Lyon, France: International Speech Communication Association. Retrieved Aug 27, 2015.
- Englert, Marina; Madazio, Glaucya; Gielow, Ingrid; Lucero, Jorge; Behlau, Mara (2016). "Perceptual error identification of human and synthesized voices". Journal of Voice. 30 (5): 639.e17–639.e23. doi:10.1016/j.jvoice.2015.07.017. PMID 26337775.
- "The HMM-based Speech Synthesis System". Hts.sp.nitech.ac.j. Retrieved 2012-02-22.
- Remez, R.; Rubin, P.; Pisoni, D.; Carrell, T. (22 May 1981). "Speech perception without traditional speech cues" (PDF). Science. 212 (4497): 947–949. Bibcode:1981Sci...212..947R. doi:10.1126/science.7233191. PMID 7233191. Archived from the original (PDF) on 2011-12-16. Retrieved 2011-12-14.
- Hsu, Wei-Ning (2018). "Hierarchical Generative Modeling for Controllable Speech Synthesis". arXiv:1810.07217 [cs.CL].
- Habib, Raza (2019). "Semi-Supervised Generative Modeling for Controllable Speech Synthesis". arXiv:1910.01709 [cs.CL].
- Chung, Yu-An (2018). "Semi-Supervised Training for Improving Data Efficiency in End-to-End Speech Synthesis". arXiv:1808.10128 [cs.CL].
- Ren, Yi (2019). "Almost Unsupervised Text to Speech and Automatic Speech Recognition". arXiv:1905.06791 [cs.CL].
- Jia, Ye (2018). "Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis". arXiv:1806.04558 [cs.CL].
- van den Oord, Aaron (2018). "Parallel WaveNet: Fast High-Fidelity Speech Synthesis". arXiv:1711.10433 [cs.CL].
- Prenger, Ryan (2018). "WaveGlow: A Flow-based Generative Network for Speech Synthesis". arXiv:1811.00002 [cs.SD].
- Yamamoto, Ryuichi (2019). "Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram". arXiv:1910.11480 [eess.AS].
- "Speech synthesis". World Wide Web Organization.
- "Blizzard Challenge". Festvox.org. Retrieved 2012-02-22.
- "Smile -and the world can hear you". University of Portsmouth. January 9, 2008. Archived from the original on May 17, 2008.
- "Smile – And The World Can Hear You, Even If You Hide". Science Daily. January 2008.
- Drahota, A. (2008). "The vocal communication of different kinds of smile" (PDF). Speech Communication. 50 (4): 278–287. doi:10.1016/j.specom.2007.10.001. Archived from the original (PDF) on 2013-07-03.
- Muralishankar, R.; Ramakrishnan, A. G.; Prathibha, P. (February 2004). "Modification of pitch using DCT in the source domain". Speech Communication. 42 (2): 143–154. doi:10.1016/j.specom.2003.05.001.
- Prathosh, A. P.; Ramakrishnan, A. G.; Ananthapadmanabha, T. V. (December 2013). "Epoch extraction based on integrated linear prediction residual using plosion index". IEEE Trans. Audio Speech Language Processing. 21 (12): 2471–2480. doi:10.1109/TASL.2013.2273717.
- EE Times. "TI will exit dedicated speech-synthesis chips, transfer products to Sensory Archived 2012-02-17 at WebCite." June 14, 2001.
- "1400XL/1450XL Speech Handler External Reference Specification" (PDF). Retrieved 2012-02-22.
- "It Sure Is Great To Get Out Of That Bag!". folklore.org. Retrieved 2013-03-24.
- "iPhone: Configuring accessibility features (Including VoiceOver and Zoom)". Apple. Retrieved 2011-01-29.
- "Amazon Polly". Amazon Web Services, Inc. Retrieved 2020-04-28.
- Miner, Jay; et al. (1991). Amiga Hardware Reference Manual (3rd ed.). Addison-Wesley Publishing Company, Inc. ISBN 978-0-201-56776-2.
- Devitt, Francesco (30 June 1995). "Translator Library (Multilingual-speech version)". Archived from the original on 26 February 2012. Retrieved 9 April 2013.
- "Accessibility Tutorials for Windows XP: Using Narrator". Microsoft. 2011-01-29. Retrieved 2011-01-29.
- "How to configure and use Text-to-Speech in Windows XP and in Windows Vista". Microsoft. 2007-05-07. Retrieved 2010-02-17.
- Jean-Michel Trivi (2009-09-23). "An introduction to Text-To-Speech in Android". Android-developers.blogspot.com. Retrieved 2010-02-17.
- Andreas Bischoff, The Pediaphon – Speech Interface to the free Wikipedia Encyclopedia for Mobile Phones, PDA's and MP3-Players, Proceedings of the 18th International Conference on Database and Expert Systems Applications, Pages: 575–579 ISBN 0-7695-2932-1, 2007
- "gnuspeech". Gnu.org. Retrieved 2010-02-17.
- "Smithsonian Speech Synthesis History Project (SSSHP) 1986–2002". Mindspring.com. Archived from the original on 2013-10-03. Retrieved 2010-02-17.
- "WaveNet: A Generative Model for Raw Audio". Deepmind.com. 2016-09-08. Retrieved 2017-05-24.
- "Adobe Voco 'Photoshop-for-voice' causes concern". BBC.com. BBC. 2016-11-07. Retrieved 2017-06-18.
- Jia, Ye; Zhang, Yu; Weiss, Ron J. (2018-06-12), "Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis", Advances in Neural Information Processing Systems, 31: 4485–4495, arXiv:1806.04558
- Arık, Sercan Ö.; Chen, Jitong; Peng, Kainan; Ping, Wei; Zhou, Yanqi (2018), "Neural Voice Cloning with a Few Samples", Advances in Neural Information Processing Systems, 31, arXiv:1802.06006
- "Fake voices 'help cyber-crooks steal cash'". bbc.com. BBC. 2019-07-08. Retrieved 2019-09-11.
- Drew, Harwell (2019-09-04). "An artificial-intelligence first: Voice-mimicking software reportedly used in a major theft". washingtonpost.com. Washington Post. Retrieved 2019-09-08.
- Thies, Justus (2016). "Face2Face: Real-time Face Capture and Reenactment of RGB Videos". Proc. Computer Vision and Pattern Recognition (CVPR), IEEE. Retrieved 2016-06-18.
- Suwajanakorn, Supasorn; Seitz, Steven; Kemelmacher-Shlizerman, Ira (2017), Synthesizing Obama: Learning Lip Sync from Audio, University of Washington, retrieved 2018-03-02
- Ng, Andrew (2020-04-01). "Voice Cloning for the Masses". deeplearning.ai. The Batch. Retrieved 2020-04-02.
- "15.ai". fifteen.ai. 2020-03-02. Retrieved 2020-04-02.
- "Pinkie Pie Added to 15.ai". equestriadaily.com. Equestria Daily. 2020-04-02. Retrieved 2020-04-02.
- "Speech Synthesis Software for Anime Announced". Anime News Network. 2007-05-02. Retrieved 2010-02-17.
- "Code Geass Speech Synthesizer Service Offered in Japan". Animenewsnetwork.com. 2008-09-09. Retrieved 2010-02-17.
External links
- Speech synthesis at Curlie
- Simulated singing with the singing robot Pavarobotti or a description from the BBC on how the robot synthesized the singing.