Byte
The byte is a unit of digital information that most commonly consists of eight bits. Historically, the byte was the number of bits used to encode a single character of text in a computer[1][2] and for this reason it is the smallest addressable unit of memory in many computer architectures.
| byte | |
|---|---|
| Unit system | units derived from bit |
| Unit of | digital information, data size |
| Symbol | B or (when referring to exactly 8 bits) o |
| Multiples of bytes | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Orders of magnitude of data | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The size of the byte has historically been hardware dependent and no definitive standards existed that mandated the size. Sizes from 1 to 48 bits have been used.[3][4][5][6] The six-bit character code was an often used implementation in early encoding systems and computers using six-bit and nine-bit bytes were common in the 1960s. These systems often had memory words of 12, 18, 24, 30, 36, 48, or 60 bits, corresponding to 2, 3, 4, 5, 6, 8, or 10 six-bit bytes. In this era, bit groupings in the instruction stream were often referred to as syllables[lower-alpha 1] or slab, before the term byte became common.
The modern de facto standard of eight bits, as documented in ISO/IEC 2382-1:1993, is a convenient power of two permitting the binary-encoded values 0 through 255 for one byte—2 to the power 8 is 256.[7] The international standard IEC 80000-13 codified this common meaning. Many types of applications use information representable in eight or fewer bits and processor designers optimize for this common usage. The popularity of major commercial computing architectures has aided in the ubiquitous acceptance of the eight-bit size.[8] Modern architectures typically use 32- or 64-bit words, built of four or eight bytes.
The unit symbol for the byte was designated as the upper-case letter B by the International Electrotechnical Commission (IEC) and Institute of Electrical and Electronics Engineers (IEEE)[9] in contrast to the bit, whose IEEE symbol is a lower-case b. Internationally, the unit octet, symbol o, explicitly defines a sequence of eight bits, eliminating the ambiguity of the byte.[10][11]
History
The term byte was coined by Werner Buchholz in June 1956,[3][12][13][lower-alpha 2] during the early design phase for the IBM Stretch[14][15][1][12][13][16][17] computer, which had addressing to the bit and variable field length (VFL) instructions with a byte size encoded in the instruction.[12] It is a deliberate respelling of bite to avoid accidental mutation to bit.[1][12][18]
Another origin of byte for bit groups smaller than a computers's word size, and in particular groups of four bits, is on record by Louis G. Dooley, who claimed he coined the term while working with Jules Schwartz and Dick Beeler on an air defense system called SAGE at MIT Lincoln Laboratory in 1956 or 1957, which was jointly developed by Rand, MIT, and IBM.[19][20] Later on, Schwartz's language JOVIAL actually used the term, but the author recalled vaguely that it was derived from AN/FSQ-31.[21][20]
Early computers used a variety of four-bit binary-coded decimal (BCD) representations and the six-bit codes for printable graphic patterns common in the U.S. Army (FIELDATA) and Navy. These representations included alphanumeric characters and special graphical symbols. These sets were expanded in 1963 to seven bits of coding, called the American Standard Code for Information Interchange (ASCII) as the Federal Information Processing Standard, which replaced the incompatible teleprinter codes in use by different branches of the U.S. government and universities during the 1960s. ASCII included the distinction of upper- and lowercase alphabets and a set of control characters to facilitate the transmission of written language as well as printing device functions, such as page advance and line feed, and the physical or logical control of data flow over the transmission media.[17] During the early 1960s, while also active in ASCII standardization, IBM simultaneously introduced in its product line of System/360 the eight-bit Extended Binary Coded Decimal Interchange Code (EBCDIC), an expansion of their six-bit binary-coded decimal (BCDIC) representations[lower-alpha 3] used in earlier card punches.[22] The prominence of the System/360 led to the ubiquitous adoption of the eight-bit storage size,[17][15][12] while in detail the EBCDIC and ASCII encoding schemes are different.
In the early 1960s, AT&T introduced digital telephony on long-distance trunk lines. These used the eight-bit μ-law encoding. This large investment promised to reduce transmission costs for eight-bit data.
The development of eight-bit microprocessors in the 1970s popularized this storage size. Microprocessors such as the Intel 8008, the direct predecessor of the 8080 and the 8086, used in early personal computers, could also perform a small number of operations on the four-bit pairs in a byte, such as the decimal-add-adjust (DAA) instruction. A four-bit quantity is often called a nibble, also nybble, which is conveniently represented by a single hexadecimal digit.
The term octet is used to unambiguously specify a size of eight bits.[17][11] It is used extensively in protocol definitions.
Historically, the term octad or octade was used to denote eight bits as well at least in Western Europe;[23][24] however, this usage is no longer common. The exact origin of the term is unclear, but it can be found in British, Dutch, and German sources of the 1960s and 1970s, and throughout the documentation of Philips mainframe computers.
Unit symbol
The unit symbol for the byte is specified in IEC 80000-13, IEEE 1541 and the Metric Interchange Format[9] as the upper-case character B. In contrast, IEEE 1541 specifies the lower case character b as the symbol for the bit, but IEC 80000-13 and Metric-Interchange-Format specify the symbol as bit, providing disambiguation from B for byte.
In the International System of Quantities (ISQ), B is the symbol of the bel, a unit of logarithmic power ratios named after Alexander Graham Bell, creating a conflict with the IEC specification. However, little danger of confusion exists, because the bel is a rarely used unit. It is used primarily in its decadic fraction, the decibel (dB), for signal strength and sound pressure level measurements, while a unit for one tenth of a byte, the decibyte, and other fractions, are only used in derived units, such as transmission rates.
The lowercase letter o for octet is defined as the symbol for octet in IEC 80000-13 and is commonly used in languages such as French[25] and Romanian, and is also combined with metric prefixes for multiples, for example ko and Mo.
The usage of the term octad(e) for eight bits is no longer common.[23][24]
Unit multiples
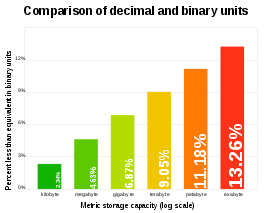
Despite standardization efforts, ambiguity still exists in the meanings of the SI (or metric) prefixes used with the unit byte, especially concerning the prefixes kilo (k or K), mega (M), and giga (G). Computer memory has a binary architecture in which multiples are expressed in powers of 2. In some fields of the software and computer hardware industries a binary prefix is used for bytes and bits, while producers of computer storage devices practice adherence to decimal SI multiples. For example, a computer disk drive capacity of 100 gigabytes is specified when the disk contains 100 billion bytes of storage space, which is the equivalent of approximately 93 gibibytes using the binary prefix gibi.
While the numerical difference between the decimal and binary interpretations is relatively small for the prefixes kilo and mega, it grows to over 20% for prefix yotta. The linear–log graph illustrates the difference versus storage size up to an exabyte.
Common uses
Many programming languages defined the data type byte.
The C and C++ programming languages define byte as an "addressable unit of data storage large enough to hold any member of the basic character set of the execution environment" (clause 3.6 of the C standard). The C standard requires that the integral data type unsigned char must hold at least 256 different values, and is represented by at least eight bits (clause 5.2.4.2.1). Various implementations of C and C++ reserve 8, 9, 16, 32, or 36 bits for the storage of a byte.[26][27][lower-alpha 4] In addition, the C and C++ standards require that there are no gaps between two bytes. This means every bit in memory is part of a byte.[28]
Java's primitive byte data type is always defined as consisting of 8 bits and being a signed data type, holding values from −128 to 127.
.NET programming languages, such as C#, define both an unsigned byte and a signed sbyte, holding values from 0 to 255, and −128 to 127, respectively.
In data transmission systems, the byte is defined as a contiguous sequence of bits in a serial data stream representing the smallest distinguished unit of data. A transmission unit might include start bits, stop bits, or parity bits, and thus could vary from 7 to 12 bits to contain a single 7-bit ASCII code.[29]
See also
- Data
- Data hierarchy
- JBOB, Just a Bunch Of Bytes
- Nibble
- Primitive data type
- Tryte
- Qubyte (quantum byte)
- Word (computer architecture)
Notes
- The term syllable was used for bytes containing instructions or constituents of instructions, not for data bytes.
- Many sources erroneously indicate a birthday of the term byte in July 1956, but Werner Buchholz claimed that the term would have been coined in June 1956. In fact, the earliest document supporting this dates from 1956-06-11. Buchholz stated that the transition to 8-bit bytes was conceived in August 1956, but the earliest document found using this notion dates from September 1956.
- There was more than one BCD code page.
- The actual number of bits in a particular implementation is documented as
CHAR_BITas implemented in the file limits.h.
References
- Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962), "4: Natural Data Units" (PDF), in Buchholz, Werner (ed.), Planning a Computer System – Project Stretch, McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA., pp. 39–40, LCCN 61-10466, archived from the original (PDF) on 2017-04-03, retrieved 2017-04-03,
Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. - Bemer, Robert William (1959), "A proposal for a generalized card code of 256 characters", Communications of the ACM, 2 (9): 19–23, doi:10.1145/368424.368435
- Buchholz, Werner (1956-06-11). "7. The Shift Matrix" (PDF). The Link System. IBM. pp. 5–6. Stretch Memo No. 39G. Archived from the original (PDF) on 2017-04-04. Retrieved 2016-04-04.
[…] Most important, from the point of view of editing, will be the ability to handle any characters or digits, from 1 to 6 bits long.
Figure 2 shows the Shift Matrix to be used to convert a 60-bit word, coming from Memory in parallel, into characters, or 'bytes' as we have called them, to be sent to the Adder serially. The 60 bits are dumped into magnetic cores on six different levels. Thus, if a 1 comes out of position 9, it appears in all six cores underneath. Pulsing any diagonal line will send the six bits stored along that line to the Adder. The Adder may accept all or only some of the bits.
Assume that it is desired to operate on 4 bit decimal digits, starting at the right. The 0-diagonal is pulsed first, sending out the six bits 0 to 5, of which the Adder accepts only the first four (0–3). Bits 4 and 5 are ignored. Next, the 4 diagonal is pulsed. This sends out bits 4 to 9, of which the last two are again ignored, and so on.
It is just as easy to use all six bits in alphanumeric work, or to handle bytes of only one bit for logical analysis, or to offset the bytes by any number of bits. All this can be done by pulling the appropriate shift diagonals. An analogous matrix arrangement is used to change from serial to parallel operation at the output of the adder. […] - 3600 Computer System – Reference Manual (PDF). K. St. Paul, Minnesota, USA: Control Data Corporation (CDC). 1966-10-11 [1965]. 60021300. Archived from the original (PDF) on 2017-04-05. Retrieved 2017-04-05.
Byte – A partition of a computer word.
(NB. Discusses 12-bit, 24-bit and 48-bit bytes.) - Rao, Thammavaram R. N.; Fujiwara, Eiji (1989). McCluskey, Edward J. (ed.). Error-Control Coding for Computer Systems. Prentice Hall Series in Computer Engineering (1 ed.). Englewood Cliffs, NJ, USA: Prentice Hall. ISBN 0-13-283953-9. LCCN 88-17892. (NB. Example of the usage of a code for "4-bit bytes".)
- Tafel, Hans Jörg (1971). Einführung in die digitale Datenverarbeitung [Introduction to digital information processing] (in German). Munich: Carl Hanser Verlag. p. 300. ISBN 3-446-10569-7.
Byte = zusammengehörige Folge von i.a. neun Bits; davon sind acht Datenbits, das neunte ein Prüfbit
(NB. Defines a byte as a group of typically 9 bits; 8 data bits plus 1 parity bit.) - ISO/IEC 2382-1: 1993, Information technology – Vocabulary – Part 1: Fundamental terms. 1993.
byte
A string that consists of a number of bits, treated as a unit, and usually representing a character or a part of a character.
NOTES
1 The number of bits in a byte is fixed for a given data processing system.
2 The number of bits in a byte is usually 8. - "Computer History Museum – Exhibits – Internet History – 1964: Internet History 1962 to 1992". Computer History Museum. 2017 [2015]. Archived from the original on 2017-04-03. Retrieved 2017-04-03.
- Jaffer, Aubrey (2011) [2008]. "Metric-Interchange-Format". Archived from the original on 2017-04-03. Retrieved 2017-04-03.
- Kozierok, Charles M. (2005-09-20) [2001]. "The TCP/IP Guide – Binary Information and Representation: Bits, Bytes, Nibbles, Octets and Characters – Byte versus Octet". 3.0. Archived from the original on 2017-04-03. Retrieved 2017-04-03.
- ISO 2382-4, Organization of data (2 ed.).
byte, octet, 8-bit byte: A string that consists of eight bits.
- Buchholz, Werner (February 1977). "The Word 'Byte' Comes of Age..." Byte Magazine. 2 (2): 144.
[…] The first reference found in the files was contained in an internal memo written in June 1956 during the early days of developing Stretch. A byte was described as consisting of any number of parallel bits from one to six. Thus a byte was assumed to have a length appropriate for the occasion. Its first use was in the context of the input-output equipment of the 1950s, which handled six bits at a time. The possibility of going to 8 bit bytes was considered in August 1956 and incorporated in the design of Stretch shortly thereafter. The first published reference to the term occurred in 1959 in a paper 'Processing Data in Bits and Pieces' by G A Blaauw, F P Brooks Jr and W Buchholz in the IRE Transactions on Electronic Computers, June 1959, page 121. The notions of that paper were elaborated in Chapter 4 of Planning a Computer System (Project Stretch), edited by W Buchholz, McGraw-Hill Book Company (1962). The rationale for coining the term was explained there on page 40 as follows:
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (ie, different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
System/360 took over many of the Stretch concepts, including the basic byte and word sizes, which are powers of 2. For economy, however, the byte size was fixed at the 8 bit maximum, and addressing at the bit level was replaced by byte addressing. […] - "Timeline of the IBM Stretch/Harvest era (1956–1961)". Computer History Museum. June 1956. Archived from the original on 2016-04-29. Retrieved 2017-04-03.
1956 Summer: Gerrit Blaauw, Fred Brooks, Werner Buchholz, John Cocke and Jim Pomerene join the Stretch team. Lloyd Hunter provides transistor leadership.
(NB. This timeline erroneously specifies the birth date of the term "byte" as July 1956, while Buchholz actually used the term as early as June 1956.)
1956 July [sic]: In a report Werner Buchholz lists the advantages of a 64-bit word length for Stretch. It also supports NSA's requirement for 8-bit bytes. Werner's term "Byte" first popularized in this memo. - Buchholz, Werner (1956-07-31). "5. Input-Output" (PDF). Memory Word Length. IBM. p. 2. Stretch Memo No. 40. Archived from the original (PDF) on 2017-04-04. Retrieved 2016-04-04.
[…] 60 is a multiple of 1, 2, 3, 4, 5, and 6. Hence bytes of length from 1 to 6 bits can be packed efficiently into a 60-bit word without having to split a byte between one word and the next. If longer bytes were needed, 60 bits would, of course, no longer be ideal. With present applications, 1, 4, and 6 bits are the really important cases.
With 64-bit words, it would often be necessary to make some compromises, such as leaving 4 bits unused in a word when dealing with 6-bit bytes at the input and output. However, the LINK Computer can be equipped to edit out these gaps and to permit handling of bytes which are split between words. […] - Buchholz, Werner (1956-09-19). "2. Input-Output Byte Size" (PDF). Memory Word Length and Indexing. IBM. p. 1. Stretch Memo No. 45. Archived from the original (PDF) on 2017-04-04. Retrieved 2016-04-04.
[…] The maximum input-output byte size for serial operation will now be 8 bits, not counting any error detection and correction bits. Thus, the Exchange will operate on an 8-bit byte basis, and any input-output units with less than 8 bits per byte will leave the remaining bits blank. The resultant gaps can be edited out later by programming […]
- Raymond, Eric Steven (2017) [2003]. "byte definition". Archived from the original on 2017-04-03. Retrieved 2017-04-03.
- Bemer, Robert William (2000-08-08). "Why is a byte 8 bits? Or is it?". Computer History Vignettes. Archived from the original on 2017-04-03. Retrieved 2017-04-03.
[…] I came to work for IBM, and saw all the confusion caused by the 64-character limitation. Especially when we started to think about word processing, which would require both upper and lower case. […] I even made a proposal (in view of STRETCH, the very first computer I know of with an 8-bit byte) that would extend the number of punch card character codes to 256 […]. So some folks started thinking about 7-bit characters, but this was ridiculous. With IBM's STRETCH computer as background, handling 64-character words divisible into groups of 8 (I designed the character set for it, under the guidance of Dr. Werner Buchholz, the man who DID coin the term 'byte' for an 8-bit grouping). […] It seemed reasonable to make a universal 8-bit character set, handling up to 256. In those days my mantra was 'powers of 2 are magic'. And so the group I headed developed and justified such a proposal […] The IBM 360 used 8-bit characters, although not ASCII directly. Thus Buchholz's 'byte' caught on everywhere. I myself did not like the name for many reasons. The design had 8 bits moving around in parallel. But then came a new IBM part, with 9 bits for self-checking, both inside the CPU and in the tape drives. I exposed this 9-bit byte to the press in 1973. But long before that, when I headed software operations for Cie. Bull in France in 1965–66, I insisted that 'byte' be deprecated in favor of 'octet'. […] It is justified by new communications methods that can carry 16, 32, 64, and even 128 bits in parallel. But some foolish people now refer to a '16-bit byte' because of this parallel transfer, which is visible in the UNICODE set. I'm not sure, but maybe this should be called a 'hextet'. […]
- Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (June 1959). "Processing Data in Bits and Pieces". IRE Transactions on Electronic Computers: 121.
- Dooley, Louis G. (February 1995). "Byte: The Word". BYTE. Ocala, FL, USA. Archived from the original on 1996-12-20.
[…] The word byte was coined around 1956 to 1957 at MIT Lincoln Laboratories within a project called SAGE (the North American Air Defense System), which was jointly developed by Rand, Lincoln Labs, and IBM. In that era, computer memory structure was already defined in terms of word size. A word consisted of x number of bits; a bit represented a binary notational position in a word. Operations typically operated on all the bits in the full word.
(NB. According to his son, Dooley wrote to him: "On good days, we would have the XD-1 up and running and all the programs doing the right thing, and we then had some time to just sit and talk idly, as we waited for the computer to finish doing its thing. On one such occasion, I coined the word "byte", they (Jules Schwartz and Dick Beeler) liked it, and we began using it amongst ourselves. The origin of the word was a need for referencing only a part of the word length of the computer, but a part larger than just one bit...Many programs had to access just a specific 4-bit segment of the full word...I wanted a name for this smaller segment of the fuller word. The word "bit" lead to "bite" (meaningfully less than the whole), but for a unique spelling, "i" could be "y", and thus the word "byte" was born.")
We coined the word byte to refer to a logical set of bits less than a full word size. At that time, it was not defined specifically as x bits but typically referred to as a set of 4 bits, as that was the size of most of our coded data items. Shortly afterward, I went on to other responsibilities that removed me from SAGE. After having spent many years in Asia, I returned to the U.S. and was bemused to find out that the word byte was being used in the new microcomputer technology to refer to the basic addressable memory unit. - Ram, Stefan. "Erklärung des Wortes "Byte" im Rahmen der Lehre binärer Codes" (in German). Berlin, Germany: Freie Universität Berlin. Retrieved 2017-04-10.
- Origin of the term "byte", 1956, archived from the original on 2017-04-10, retrieved 2017-04-10,
A question-and-answer session at an ACM conference on the history of programming languages included this exchange:
JOHN GOODENOUGH: You mentioned that the term "byte" is used in JOVIAL. Where did the term come from?
JULES SCHWARTZ (inventor of JOVIAL): As I recall, the AN/FSQ-31, a totally different computer than the 709, was byte oriented. I don't recall for sure, but I'm reasonably certain the description of that computer included the word "byte," and we used it.
FRED BROOKS: May I speak to that? Werner Buchholz coined the word as part of the definition of STRETCH, and the AN/FSQ-31 picked it up from STRETCH, but Werner is very definitely the author of that word.
SCHWARTZ: That's right. Thank you. - "List of EBCDIC codes by IBM". ibm.com.
- Williams, R. H. (1969-01-01). British Commercial Computer Digest: Pergamon Computer Data Series. Pergamon Press. ISBN 1483122107. 978-1483122106.
- "Philips – Philips Data Systems' product range – April 1971" (PDF). Philips. April 1971. Archived from the original (PDF) on 2016-03-04. Retrieved 2015-08-03.
- "When is a kilobyte a kibibyte? And an MB an MiB?". The International System of Units and the IEC. International Electrotechnical Commission. Retrieved 2010-08-30.)
- Cline, Marshall. "I could imagine a machine with 9-bit bytes. But surely not 16-bit bytes or 32-bit bytes, right?".
- Klein, Jack (2008), Integer Types in C and C++, archived from the original on 2010-03-27, retrieved 2015-06-18
- Cline, Marshall. "C++ FAQ: the rules about bytes, chars, and characters".
- "External Interfaces/API". Northwestern University.
Further reading
- Programming with the PDP-10 Instruction Set (PDF). PDP-10 System Reference Manual. 1. Digital Equipment Corporation (DEC). August 1969. Archived (PDF) from the original on 2017-04-05. Retrieved 2017-04-05.
- Ashley Taylor. “Bits and Bytes.” Stanford. https://web.stanford.edu/class/cs101/bits-bytes.html