Autoregressive model
In statistics, econometrics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation (or recurrence relation which should not be confused with differential equation). Together with the moving-average (MA) model, it is a special case and key component of the more general autoregressive–moving-average (ARMA) and autoregressive integrated moving average (ARIMA) models of time series, which have a more complicated stochastic structure; it is also a special case of the vector autoregressive model (VAR), which consists of a system of more than one interlocking stochastic difference equation in more than one evolving random variable.
Contrary to the moving-average (MA) model, the autoregressive model is not always stationary as it may contain a unit root.
Definition
The notation indicates an autoregressive model of order p. The AR(p) model is defined as


where are the parameters of the model, is a constant, and is white noise. This can be equivalently written using the backshift operator B as




so that, moving the summation term to the left side and using polynomial notation, we have

An autoregressive model can thus be viewed as the output of an all-pole infinite impulse response filter whose input is white noise.
Some parameter constraints are necessary for the model to remain wide-sense stationary. For example, processes in the AR(1) model with are not stationary. More generally, for an AR(p) model to be wide-sense stationary, the roots of the polynomial must lie outside the unit circle, i.e., each (complex) root must satisfy (see pages 88,90 [1]).




Intertemporal effect of shocks
In an AR process, a one-time shock affects values of the evolving variable infinitely far into the future. For example, consider the AR(1) model . A non-zero value for at say time t=1 affects by the amount . Then by the AR equation for in terms of , this affects by the amount . Then by the AR equation for in terms of , this affects by the amount . Continuing this process shows that the effect of never ends, although if the process is stationary then the effect diminishes toward zero in the limit.







Because each shock affects X values infinitely far into the future from when they occur, any given value Xt is affected by shocks occurring infinitely far into the past. This can also be seen by rewriting the autoregression

(where the constant term has been suppressed by assuming that the variable has been measured as deviations from its mean) as

When the polynomial division on the right side is carried out, the polynomial in the backshift operator applied to has an infinite order—that is, an infinite number of lagged values of appear on the right side of the equation.
Characteristic polynomial
The autocorrelation function of an AR(p) process can be expressed as

where are the roots of the polynomial


where B is the backshift operator, where is the function defining the autoregression, and where are the coefficients in the autoregression.


The autocorrelation function of an AR(p) process is a sum of decaying exponentials.
- Each real root contributes a component to the autocorrelation function that decays exponentially.
- Similarly, each pair of complex conjugate roots contributes an exponentially damped oscillation.
Graphs of AR(p) processes
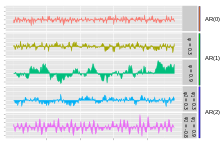
The simplest AR process is AR(0), which has no dependence between the terms. Only the error/innovation/noise term contributes to the output of the process, so in the figure, AR(0) corresponds to white noise.
For an AR(1) process with a positive , only the previous term in the process and the noise term contribute to the output. If is close to 0, then the process still looks like white noise, but as approaches 1, the output gets a larger contribution from the previous term relative to the noise. This results in a "smoothing" or integration of the output, similar to a low pass filter.

For an AR(2) process, the previous two terms and the noise term contribute to the output. If both and are positive, the output will resemble a low pass filter, with the high frequency part of the noise decreased. If is positive while is negative, then the process favors changes in sign between terms of the process. The output oscillates. This can be likened to edge detection or detection of change in direction.


Example: An AR(1) process
An AR(1) process is given by:

where is a white noise process with zero mean and constant variance . (Note: The subscript on has been dropped.) The process is wide-sense stationary if since it is obtained as the output of a stable filter whose input is white noise. (If then the variance of depends on time lag t, so that the variance of the series diverges to infinity as t goes to infinity, and is therefore not wide sense stationary.) Assuming , the mean is identical for all values of t by the very definition of wide sense stationarity. If the mean is denoted by , it follows from







that

and hence

In particular, if , then the mean is 0.

The variance is

where is the standard deviation of . This can be shown by noting that


and then by noticing that the quantity above is a stable fixed point of this relation.
The autocovariance is given by

It can be seen that the autocovariance function decays with a decay time (also called time constant) of [to see this, write where is independent of . Then note that and match this to the exponential decay law ].






The spectral density function is the Fourier transform of the autocovariance function. In discrete terms this will be the discrete-time Fourier transform:

This expression is periodic due to the discrete nature of the , which is manifested as the cosine term in the denominator. If we assume that the sampling time () is much smaller than the decay time (), then we can use a continuum approximation to :





which yields a Lorentzian profile for the spectral density:

where is the angular frequency associated with the decay time .

An alternative expression for can be derived by first substituting for in the defining equation. Continuing this process N times yields



For N approaching infinity, will approach zero and:


It is seen that is white noise convolved with the kernel plus the constant mean. If the white noise is a Gaussian process then is also a Gaussian process. In other cases, the central limit theorem indicates that will be approximately normally distributed when is close to one.

Explicit mean/difference form of AR(1) process
The AR(1) model is the discrete time analogy of the continuous Ornstein-Uhlenbeck process. It is therefore sometimes useful to understand the properties of the AR(1) model cast in an equivalent form. In this form, the AR(1) model, with process parameter is given by:

- , where and is the model mean.


By putting this in the form , and then expanding the series for , one can show that:


- , and
- .


Choosing the maximum lag
The partial autocorrelation of an AR(p) process equals zero at lag which is not bigger than order of p and provides a good model for the correlation between and , so the appropriate maximum lag is the one beyond which the partial autocorrelations are all zero.

Calculation of the AR parameters
There are many ways to estimate the coefficients, such as the ordinary least squares procedure or method of moments (through Yule–Walker equations).
The AR(p) model is given by the equation

It is based on parameters where i = 1, ..., p. There is a direct correspondence between these parameters and the covariance function of the process, and this correspondence can be inverted to determine the parameters from the autocorrelation function (which is itself obtained from the covariances). This is done using the Yule–Walker equations.

Yule–Walker equations
The Yule–Walker equations, named for Udny Yule and Gilbert Walker,[2][3] are the following set of equations.[4]

where m = 0, ..., p, yielding p + 1 equations. Here is the autocovariance function of Xt, is the standard deviation of the input noise process, and is the Kronecker delta function.


Because the last part of an individual equation is non-zero only if m = 0, the set of equations can be solved by representing the equations for m > 0 in matrix form, thus getting the equation

which can be solved for all The remaining equation for m = 0 is


which, once are known, can be solved for


An alternative formulation is in terms of the autocorrelation function. The AR parameters are determined by the first p+1 elements of the autocorrelation function. The full autocorrelation function can then be derived by recursively calculating [5]


Examples for some Low-order AR(p) processes
- p=1
- Hence
- p=2
- The Yule–Walker equations for an AR(2) process are
- Remember that
- Using the first equation yields
- Using the recursion formula yields
- The Yule–Walker equations for an AR(2) process are







Estimation of AR parameters
The above equations (the Yule–Walker equations) provide several routes to estimating the parameters of an AR(p) model, by replacing the theoretical covariances with estimated values.[6] Some of these variants can be described as follows:
- Estimation of autocovariances or autocorrelations. Here each of these terms is estimated separately, using conventional estimates. There are different ways of doing this and the choice between these affects the properties of the estimation scheme. For example, negative estimates of the variance can be produced by some choices.
- Formulation as a least squares regression problem in which an ordinary least squares prediction problem is constructed, basing prediction of values of Xt on the p previous values of the same series. This can be thought of as a forward-prediction scheme. The normal equations for this problem can be seen to correspond to an approximation of the matrix form of the Yule–Walker equations in which each appearance of an autocovariance of the same lag is replaced by a slightly different estimate.
- Formulation as an extended form of ordinary least squares prediction problem. Here two sets of prediction equations are combined into a single estimation scheme and a single set of normal equations. One set is the set of forward-prediction equations and the other is a corresponding set of backward prediction equations, relating to the backward representation of the AR model:
- Here predicted values of Xt would be based on the p future values of the same series. This way of estimating the AR parameters is due to Burg,[7] and is called the Burg method:[8] Burg and later authors called these particular estimates "maximum entropy estimates",[9] but the reasoning behind this applies to the use of any set of estimated AR parameters. Compared to the estimation scheme using only the forward prediction equations, different estimates of the autocovariances are produced, and the estimates have different stability properties. Burg estimates are particularly associated with maximum entropy spectral estimation.[10]

Other possible approaches to estimation include maximum likelihood estimation. Two distinct variants of maximum likelihood are available: in one (broadly equivalent to the forward prediction least squares scheme) the likelihood function considered is that corresponding to the conditional distribution of later values in the series given the initial p values in the series; in the second, the likelihood function considered is that corresponding to the unconditional joint distribution of all the values in the observed series. Substantial differences in the results of these approaches can occur if the observed series is short, or if the process is close to non-stationarity.
Spectrum
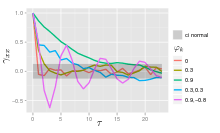
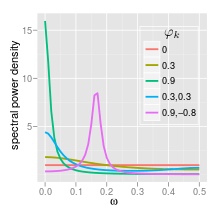
The power spectral density (PSD) of an AR(p) process with noise variance is[5]


AR(0)
For white noise (AR(0))

AR(1)
For AR(1)

- If there is a single spectral peak at f=0, often referred to as red noise. As becomes nearer 1, there is stronger power at low frequencies, i.e. larger time lags. This is then a low-pass filter, when applied to full spectrum light, everything except for the red light will be filtered.
- If there is a minimum at f=0, often referred to as blue noise. This similarly acts as a high-pass filter, everything except for blue light will be filtered.


AR(2)
AR(2) processes can be split into three groups depending on the characteristics of their roots:

- When , the process has a pair of complex-conjugate roots, creating a mid-frequency peak at:


Otherwise the process has real roots, and:
- When it acts as a low-pass filter on the white noise with a spectral peak at
- When it acts as a high-pass filter on the white noise with a spectral peak at .


The process is non-stationary when the roots are outside the unit circle. The process is stable when the roots are within the unit circle, or equivalently when the coefficients are in the triangle .

The full PSD function can be expressed in real form as:

Implementations in statistics packages
- R, the stats package includes an ar function.[11]
- MATLAB's Econometrics Toolbox [12] and System Identification Toolbox [13] includes autoregressive models [14]
- Matlab and Octave: the TSA toolbox contains several estimation functions for uni-variate, multivariate and adaptive autoregressive models.[15]
- PyMC3: the Bayesian statistics and probabilistic programming framework supports autoregressive modes with p lags.
- bayesloop supports parameter inference and model selection for the AR-1 process with time-varying parameters.[16]
- Python: implementation in statsmodels.[17]
Impulse response
The impulse response of a system is the change in an evolving variable in response to a change in the value of a shock term k periods earlier, as a function of k. Since the AR model is a special case of the vector autoregressive model, the computation of the impulse response in vector autoregression#impulse response applies here.
n-step-ahead forecasting
Once the parameters of the autoregression
have been estimated, the autoregression can be used to forecast an arbitrary number of periods into the future. First use t to refer to the first period for which data is not yet available; substitute the known preceding values Xt-i for i=1, ..., p into the autoregressive equation while setting the error term equal to zero (because we forecast Xt to equal its expected value, and the expected value of the unobserved error term is zero). The output of the autoregressive equation is the forecast for the first unobserved period. Next, use t to refer to the next period for which data is not yet available; again the autoregressive equation is used to make the forecast, with one difference: the value of X one period prior to the one now being forecast is not known, so its expected value—the predicted value arising from the previous forecasting step—is used instead. Then for future periods the same procedure is used, each time using one more forecast value on the right side of the predictive equation until, after p predictions, all p right-side values are predicted values from preceding steps.
There are four sources of uncertainty regarding predictions obtained in this manner: (1) uncertainty as to whether the autoregressive model is the correct model; (2) uncertainty about the accuracy of the forecasted values that are used as lagged values in the right side of the autoregressive equation; (3) uncertainty about the true values of the autoregressive coefficients; and (4) uncertainty about the value of the error term for the period being predicted. Each of the last three can be quantified and combined to give a confidence interval for the n-step-ahead predictions; the confidence interval will become wider as n increases because of the use of an increasing number of estimated values for the right-side variables.

Evaluating the quality of forecasts
The predictive performance of the autoregressive model can be assessed as soon as estimation has been done if cross-validation is used. In this approach, some of the initially available data was used for parameter estimation purposes, and some (from available observations later in the data set) was held back for out-of-sample testing. Alternatively, after some time has passed after the parameter estimation was conducted, more data will have become available and predictive performance can be evaluated then using the new data.
In either case, there are two aspects of predictive performance that can be evaluated: one-step-ahead and n-step-ahead performance. For one-step-ahead performance, the estimated parameters are used in the autoregressive equation along with observed values of X for all periods prior to the one being predicted, and the output of the equation is the one-step-ahead forecast; this procedure is used to obtain forecasts for each of the out-of-sample observations. To evaluate the quality of n-step-ahead forecasts, the forecasting procedure in the previous section is employed to obtain the predictions.
Given a set of predicted values and a corresponding set of actual values for X for various time periods, a common evaluation technique is to use the mean squared prediction error; other measures are also available (see forecasting#forecasting accuracy).
The question of how to interpret the measured forecasting accuracy arises—for example, what is a "high" (bad) or a "low" (good) value for the mean squared prediction error? There are two possible points of comparison. First, the forecasting accuracy of an alternative model, estimated under different modeling assumptions or different estimation techniques, can be used for comparison purposes. Second, the out-of-sample accuracy measure can be compared to the same measure computed for the in-sample data points (that were used for parameter estimation) for which enough prior data values are available (that is, dropping the first p data points, for which p prior data points are not available). Since the model was estimated specifically to fit the in-sample points as well as possible, it will usually be the case that the out-of-sample predictive performance will be poorer than the in-sample predictive performance. But if the predictive quality deteriorates out-of-sample by "not very much" (which is not precisely definable), then the forecaster may be satisfied with the performance.
See also
Notes
- Shumway, Robert; Stoffer, David (2010). Time series analysis and its applications : with R examples (3rd ed.). Springer. ISBN 144197864X.
- Yule, G. Udny (1927) "On a Method of Investigating Periodicities in Disturbed Series, with Special Reference to Wolfer's Sunspot Numbers", Philosophical Transactions of the Royal Society of London, Ser. A, Vol. 226, 267–298.]
- Walker, Gilbert (1931) "On Periodicity in Series of Related Terms", Proceedings of the Royal Society of London, Ser. A, Vol. 131, 518–532.
- Theodoridis, Sergios (2015-04-10). "Chapter 1. Probability and Stochastic Processes". Machine Learning: A Bayesian and Optimization Perspective. Academic Press, 2015. pp. 9–51. ISBN 978-0-12-801522-3.
- Von Storch, H.; F. W Zwiers (2001). Statistical analysis in climate research. Cambridge Univ Pr. ISBN 0-521-01230-9.
- Eshel, Gidon. "The Yule Walker Equations for the AR Coefficients" (PDF). stat.wharton.upenn.edu.
- Burg, J. P. (1968). "A new analysis technique for time series data". In Modern Spectrum Analysis (Edited by D. G. Childers), NATO Advanced Study Institute of Signal Processing with emphasis on Underwater Acoustics. IEEE Press, New York.
- Brockwell, Peter J.; Dahlhaus, Rainer; Trindade, A. Alexandre (2005). "Modified Burg Algorithms for Multivariate Subset Autoregression" (PDF). Statistica Sinica. 15: 197–213. Archived from the original (PDF) on 2012-10-21.
- Burg, J.P. (1967) "Maximum Entropy Spectral Analysis", Proceedings of the 37th Meeting of the Society of Exploration Geophysicists, Oklahoma City, Oklahoma.
- Bos, R.; De Waele, S.; Broersen, P. M. T. (2002). "Autoregressive spectral estimation by application of the burg algorithm to irregularly sampled data". IEEE Transactions on Instrumentation and Measurement. 51 (6): 1289. doi:10.1109/TIM.2002.808031.
- "Fit Autoregressive Models to Time Series" (in R)
- Econometrics Toolbox Overview
- System Identification Toolbox overview
- "Autoregressive modeling in MATLAB"
- "Time Series Analysis toolbox for Matlab and Octave"
- bayesloop: Probabilistic programming framework that facilitates objective model selection for time-varying parameter models.
- "statsmodels.tsa.ar_model.AR — statsmodels 0.9.0 documentation". www.statsmodels.org. Retrieved 2019-05-16.
References
- Mills, Terence C. (1990). Time Series Techniques for Economists. Cambridge University Press.
- Percival, Donald B.; Walden, Andrew T. (1993). Spectral Analysis for Physical Applications. Cambridge University Press.
- Pandit, Sudhakar M.; Wu, Shien-Ming (1983). Time Series and System Analysis with Applications. John Wiley & Sons.
External links
- AutoRegression Analysis (AR) by Paul Bourke
- Econometrics lecture (topic: Autoregressive models) on YouTube by Mark Thoma