UVC-based preservation
UVC-based preservation is an archival strategy for handling the preservation of digital objects. It employs the use of a Universal Virtual Computer (UVC)—a virtual machine (VM) specifically designed for archival purposes, that allows both emulation and migration to a language-neutral format like XML.[1]
Background to the development of a UVC approach
Digital preservation problem
Preservation of digital resources is of a paramount importance for deposit libraries, research libraries, archives, government agencies, and actually most organizations.[1] The dominant approach to digital preservation is migration. Migration entails making periodic transformations of archived information into new logical formats as their native formats, or the software or hardware on which they depend becomes obsolete. The notable danger of migration is data loss, and possible loss of original functionality or the ‘look and feel’ of the original format. Furthermore, digital migrations are time consuming and costly as the process requires converting the format of every document, in addition to copying converted bit streams to new media as necessary.
Emulation theory
Jeff Rothenberg caused a bit of stir in organizations concerned and responsible for digital preservation with his report in 1999: "Avoiding technological quicksand: Finding a viable technical foundation for digital preservation". He states that there are no viable solutions to ensure that digital information will be readable in the future. The proposed solutions of relying on standards and migrations are labeled time consuming and ultimately incapable of preserving digital documents in their original form. He suggests:
"an ideal approach should provide a single, extensible, long-term solution that can be designed once and for all and applied uniformly, automatically, and in synchrony (for example, at every future refresh cycle) to all types of documents and all media, with minimal human intervention."
He proposes that the best way to satisfy the above criteria is Emulation by; developing an emulator that will run on unknown future computers; developing techniques to capture the metadata needed to find, access and recreate the document; developing techniques for encapsulating documents, their attendant metadata, software, and emulator specifications.
In 2000 he suggests implementing an emulation-based preservation approach in which emulator specification are expressed as programs and interpreted by an emulator specification interpreter program written for an emulation virtual machine.
Rothenberg's approach was met with skepticism and considered too technically challenging, too expensive and too time consuming, and therefore an economic risk (without the support of empirical evidence). (See further reading section)
UVC concept development
Role of IBM
Raymond A. Lorie, during his employment at IBM Research Centre Almaden, initiated the development of a UVC-based solution to long-term digital preservation.[2] He describes the approach as ‘Universal’ because its definition is so basic that it will endure forever, ‘Virtual’ because it will never have to be physically built and it is a ‘Computer’ in its functionality.
IBM (NL), the asset owner of the UVC, continues to develop the UVC concept within the PLANETS project. Raymond van Diessen is responsible for extending the application of the UVC concept to preserve more complex objects.
Role of the National Library of the Netherlands
The National Library of the Netherlands (Koninklijke Bibliotheek, KB) played a major role in demonstrating that emulation based on the UVC concept is a viable option for long-term digital preservation.
In 2000, the emulation advocate, Jeff Rothenberg participated in a study with the KB to test and evaluate the feasibility of using emulation as a long-term preserving strategy. His method was to use software emulation to reproduce the behaviour of obsolete computing platforms on newer platforms offering a way of running a digital document’s original software in the far future, thereby recreating the content, behaviour, and ‘look and feel’ of the original document.[3] Rothenberg was criticized for trying to preserve the wrong thing by suggesting to emulate the behavior of old hardware platforms and operating systems to access the original data through the original software program associated with it. Raymond A. Lorie recognized the difficulties in trying to create a program to emulate a 'real' machine on a future platform and realised that this approach was overkill for the purpose of preserving digital objects. Instead he introduced a novel approach of data/program archiving using a ‘Universal Virtual Computer’.[2] The concept of the UVC-based preservation strategy was implemented by the KB and tested on PDF files as part of a KB/IBM ‘Long Term Preservation’ (LTP) study.[4] Creating a UVC for PDF documents is more complex. Instead the KB decided on developing a UVC for images because this approach would also cover PDF documents (a PDF file can easily be converted to a series of images). The UVC-based approach resulted in the UVC as one of the permanent access tools for JPEG/GIF87 images within the Preservation Subsystem of the KB’s e-Depot.[5] Following the successful implementation of the UVC, the KB has continued to develop their emulation strategy for long-term digital preservation by focusing on 'full' or hardware emulation. This approach delivered a durable x86 component-based computer emulator: Dioscuri, the first modular emulator for digital preservation.[6]
UVC-based preservation
The Universal Virtual Computer is part of a broader concept, called the UVC-based preservation method. This method allows digital objects (like text documents, spreadsheets, images, sound waves, etc.) to be reconstructed in its original appearance anytime in the future. The methods are programs written in the machine language of a Universal Virtual Computer (UVC). The UVC is completely independent of the architecture of the computer on which it runs.
The UVC itself is a program which contains a set of instructions rather than a physical computer. It will run as a software application on a future platform. Because we do not know at this time which hardware is available in the future, the UVC must be created at the time we want to access a particular document from the repository. This UVC then forms the platform on which programs can run that have been specifically written for such UVC in the past. Creating an emulation program for the UVC in the future is much simpler than trying to emulate a 'real' machine.
Application description
The method of a UVC-based preservation strategy differentiates between data archiving which does not require full emulation, and program archiving which does. For archiving data, the UVC is used to archive methods which interpret the stored data stream.[2] The methods are programs written in the machine language of a Universal Virtual Computer (UVC). The UVC program is completely independent of the architecture of the computer on which it runs.
Data archiving
Data archiving reconstructs the 'look and feel' of the original file but not the functionality of the original format. If the electronic form of the document is only used for compact storage or if the way the document looks to the human eye is all there is, then it suffices to archive the document as an image. If additional functionality is needed, such as text searching, storing only the image is not enough. In this case the text also needs to be archived along with the image of the document. By restoring the original appearance of a file as an image a future user can see what the original file looks like in page layout, style, font etc. The text itself needs to be exported i.e. in ASCII format and can be saved as a sequence of homogeneous elements (all presentation attributes like font, size, etc. are the same for all characters) because the page image shows the exact look of the page. In this case the UVC program of the data has two parts, one to decode the text and one to decode the image.
What it entails
The data contained in the bit stream is stored with an internal representation, extracted from the data stream, of logical data elements that obey a certain schema in a certain data model. A decoding algorithm (method) extracts the various data elements from the internal representation and returns them tagged according to the schema. An additional schema (schema to read schemas) with information of the schema is similarly stored with the data together with a method to decode the schema to read schemas.
Logical Data View
The logical data model is kept simple in order to minimize the amount of description accompanying the data and to decrease the difficulty of understanding the structure of the data. The data model chosen for the UVC-based preservation method linearizes the data elements into a hierarchy of tagged elements organized using a XML-like approach. The tagged data elements are extracted from the data stream of the digital file. A tag specifies the role that the data element plays in the data structure. The element tags hold the specific information about the content of the data in a technology-independent manner. Furthermore, the data elements tagged according to the schema are returned to the client in a Logical Data View (LDV)
Example of Logical Data View

The schema (format decoder)
More information is needed about the various data elements in order to humanly understand what each element means, information such as the place of the tags in the hierarchy, the type of data (numeric, characters), together with some information on the semantics of the data. For example, the image has two attributes, width and heights, indicating that width times height pixels follow; but are these pixels stored line by line or column by column? Or, for colored pictures, how to interpret the RGB values in order to recreate the right color? This extra information is also called metadata. The schema is clearly application-dependent as it describes the structure and meaning of the tags as parts of a specific information type.
Schema to read the schemas (Logical Data Schema (LDS))
If in the future a user gets the tagged data elements, he/she will generally not understand the meaning of the data and the relationships between them and the future user will need additional information on the logical structure. In other word, a schema to read the metadata schema is needed. A simple solution adopted for the UVC approach is a method for the schema similar to the method for the data: the schema information is stored in an internal representation, and accompanied by a method to decode it.
At this point, what will be included in the archive is: the data itself, the metadata, a UVC program to decode the data, and a UVC program to decode the metadata.
Program archiving
The UVC method for data archiving can be extended for program archiving. Program archiving involves archiving the behavior and functionality of a program and may involve archiving the operating system as well. Archiving the operating system may not be needed if the program is only a series of native instructions of the operating system. However, the operating system must be archived if the digital object is a full-fledged system with Input/Output interactions.
If no Input/Output interactions are needed it suffices to archive the operating system's program. In this case, using a similar method as described above, the following needs to be stored at archiving time:
- the program
- a UVC program that emulates the instruction sets of the operating system on which the original program (i.e. software application) runs.
In the future - the UVC interprets the UVC code which will yield the same result as the original program running on the original operating system.
When Input/Output interactions are involved things become more complicated as an additional UVC program that mimics the functioning of the Input/Output device processor must be archived. This UVC program will produce an Input/Output data structure.
In the future - a mapping of the data structure needs to be written to the actual device.
The UVC method replaces the need for a multitude of standards (one for each format) by a single standard on the UVC method. That standard should cover: the UVC functional specifications, the interface to call the methods, the model for the schema and for the schema to read schemas
Specification
The central idea of UVC-based preservation is that digital objects preserved in an archive can be reconstructed anytime in the future without losing the meaning of that object. The UVC architecture is influenced by the characteristics as a real existing computer. It contains a memory, registers and a set of low-level instructions. The architecture differs from a 'real' computer in that it never has to be physically implemented. Consequently there are no actual physical cost. The core element of the UVC is its segment-based memory. It uses segments of memory to store distinct parts of the data. This segment-based design prevents the allocated memory to be accidentally overwritten by other applications as it does not share its memory space.[7]
Conceptual model
Together with the original data it is possible to reconstruct the meaning of each particular digital object. The UVC can be seen as the heart of the system. Like the Java Virtual Machine and the Common Language Runtime, the UVC is actually an emulator which allows a program to run on virtual instances of the necessary, usually obsolete, hardware, and will continue to emulate the necessary hardware as technology continues to evolve. Because we do not know at this time which hardware is available in the future, the UVC must be created at the time we want to access a particular document from the repository. The UVC forms the platform on which programs specifically written for the UVC can run.
What needs to be done
Different steps must be taken at archiving time (present) and retrieval time (future).
At archiving time
Step 1 - Define the appropriate logical schema for a given application
Step 2 - Choose an internal representation and associate a UVC program P with the data. This is part of the normal design of an application
Step 3 – Write the UVC program for data interpretation
Step 4 - Archive the schema information by storing an internal representation of the schema information in the bit stream together with a UVC program Q to decode it. Since the structure of the schema is the same for all applications, a schema to read schemata is chosen once and for all.
At retrieval time
Step 1 - Create an emulator on the current platform. Because of the simplicity of the UVC concept, it is fairly easy for skilled software developers to construct a UVC emulator for a particular platform of the time
Step 2 - Develop a Logical Data Viewer (a restore program to restore the data). This is an application program that reads the UVC object code and the bit stream and invokes the emulator to execute the UVC program i.e. the program controls the UVC and all input/output interaction between it
Step 3 - Write a restore program to restore the schema. Since the logical view for the schema information is fixed a single restore program may actually support all applications. If the future client already knows the logical view for the documents being restored then the schema does not necessarily needs retrieving. Furthermore, the schema only needs to be requested once for a collection of documents of the same type
UVC convention
The UVC convention includes the information items that need to be archived today, and preserved indefinitely to enable the retrieval of digital objects in the future. Included in the convention are;
- The UVC architecture document
- The interface to the UVC emulator (Logical Data Viewer)
- The definition of the logical data schema or LDS (the schema to read schemata)
The convention must be 'written in stone'. It can be saved digitally, on paper and/or in micrographic media.
Preservation System
Components
UVC-based preservation as the central idea of the UVC-based preservation method is based on four different components. These are:
- UVC program (format decoder)
- Logical data Schema (LDS) with information type description
- Universal Virtual Computer
- Logical data viewer (UVC interface)
- UVC interpreter
- Restoration program
Fig. 2 UVC and its components
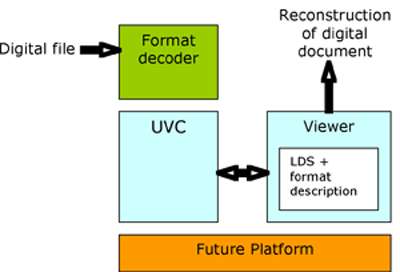
Description of method
The UVC program decodes the file format of a digital object. This format decoder program runs on the UVC, which is the platform-independent layer, independent of future hard- and software changes. Executing the format decoder delivers the element tags. These elements build the Logical Data View (LDV) of the data, which is quite similar to XML. The LDV is an instantiation of the LDS, describing the structure and meaning of the tags as parts of a specific information type.
All these components are controlled by a Logical Data Viewer simply called viewer. For reconstruction, the viewer starts the UVC and feeds it with the data of the digital object to a format decoder running on top of the UVC. In return it retrieves an LDV and reconstructs a specific representation of the original object’s meaning.
Performance
The architecture relies on concepts that have existed since the beginning of the computer era: memory, registers and basic instructions without secondary features often introduced to improve the execution performance. The performance is of secondary concern as the UVC programs are run mostly to restore the data and not work with them.
Speed is not a real concern either as future machines will be much faster, and an emulation of the UVC on a future machine will consequently run much faster. Furthermore, the flexibility of the UVC is more important than the speed of execution. Even so, performance can always still be improved.
Implementation
The UVC for data archiving i.e. the archiving of static files, is proven to work in an operational digital archiving environment. The UVC is one of the permanent access tools for images at the KB.
UVC for Images
The UVC is proven to successfully restore digital objects in their original form. The application is simple because with images no functionality is needed. The approach to develop a UVC for JPEG images is justified as most formats can be converted to this format. For example, a PDF document can be displayed as a series of JPEG images thereby retaining the 'look and feel' of the original digital object but sacrificing the functionality. Furthermore, the application for JPEG images can be easily adopted to emulate TIFF images by making a small adjustment to the Logical Data Schema.
The approach can also be applied to all other objects which do not contain behavioral aspects. For example, interpreters have been written (partially) for Excel, Lotus 1-2-3 and PDF. However, these applications only handle the static features of the formats.
UVC-based emulation
UVC-based emulation uses the UVC as a universal platform on which a platform independent emulator can be built. The UVC (software program) recreates a simple general purpose computer and can be easily implemented on any computer platform now and in the future. With this strategy future users should always be able to access and view the original object. The official UVC specification must be preserved at preservation time. Also decoders must be developed for each specific file format and a LSD is required for each type of digital object, defining object types by image, sound, spreadsheet, text, etc. And of course the original objects should be preserved as well.[8]
Complex objects/dynamic content
As mentioned before, the UVC-based approach has only been effectively implemented for static files. The technology continues to be developed by Raymond van Diessen (IBM) to include dynamic objects by exploiting the communication facility between the UVC program and a future application.[9]
Alternative emulation approaches
Other emulation approaches are stacked emulation, migrated emulation and Emulation Virtual Machine (VM).
Stacked emulation
Stacked emulation is platform dependent emulation that requires, over time, multiple emulators running on top of each other to reconstruct a historic platform. This brings better performance and functionality but lacks compatibility between platforms. This approach can mainly be found in the gaming industry.
Migrated emulation
Migrated emulation involves creating a platform dependent emulator that must be migrated (adapted) to subsequent newer hosts. When the particular operating system on which the emulator is created becomes obsolete, the emulator is translated to run on the new current platform. This approach is a strategy with high risks
Emulation Virtual Machine (EVM)
The EVM was presented by Jeff Rothenberg in 1999 and involves introducing an additional layer between the host platform and emulator and is said to be platform and time independent. This approach uses a virtual machine, and an emulator specification interpreter. It is said to be platform and time independent. It is quite complex as an emulation specification needs to be written for the computer platform on which the original software runs. The specification is then interpreted by an emulation specification interpreter that creates an emulator for the old platform. Both the interpreter and the created emulator run on the EVM.
Cost implications
Copyright issues
Copyright issues for this approach are not expected to be different from those of any other approach.
If intellectual property rights exist for a format this issue has to be taken up with the format owners. Similarly, to 'UVC-enable" applications the source code is required from the developer and therefore permission from the owner. Lastly, for hardware emulation, all the relevant licenses of the software running on the system are required.
Historical timeline
- 1995 Rothenberg advocates emulation as a long-term preservation solution.
- 2000 Rothenberg describes an Emulator Virtual Machine (EVM)
- 2001 Lorie presents a novel approach to the preservation of digital data, based on a Universal Virtual Computer
- 2002 Lorie reports on the ongoing work in refining the methodology and building an initial prototype.
- 2002 Proof of concept for UVC-based preservation of static files
- 2004 Experimental stage of implementing a UVC for images within an operational digital archive environment
- 2005 Operational UVC as a permanent access tool for Images
- 2007 UVC inspired universal platform and component library for a modular emulation model
- present (2009) continuing research into extending the UVC-based preservation approach to complex processes
See also
References
- Lorie R. A., 2002. A Methodology and System for Preserving Digital Data. Proceedings of the 2nd ACM/IEEE-CS joint conference on Digital libraries, Portland, Oregon, USA. 14–18 July 2002. New York, NY: Association of Computing Machinery. pp. 312-319 doi:10.1145/544220.544296
- Lorie R. A., 2001. Long term preservation of digital information. Proceedings of the 1st ACM/IEEE-CS joint conference on Digital libraries, Roanoke, Virginia, United States. 24–28 June 2001. New York, NY: Association of Computing Machinery. pp. 346-352 doi:10.1145/379437.379726
- Rothenberg, J., 2000. Experiment in using digital emulation to preserve digital publications. NEDLIB Report Series 1 [online] Den Haag: National Library of the Netherlands
- Lorie, R. A., 2002. The UVC: a Method for Preserving Digital Documents – Proof of Concept. IBM/KB Long-term Preservation Study. Amsterdam: IBM Netherlands
- Wijngaarden H., Oltmans, E., 2004. Digital Preservation and Permanent Access: The UVC for Images. Proceedings of the Imaging Science & Technology Archiving Conference, San Antonio, USA. 23 April 2004 pp. 254-259
- van der Hoeven J. R., Lohman B., Verdegem R., 2007. Emulation for Digital Preservation in Practice: The Results. The International Journal of Digital Curation, 2(2), pp. 123-132
- van Diessen R. J., van der Hoeven J. R., van der Meer K., 2005. Development of a Universal Virtual Computer (UVC) for long-term preservation of digital objects, 31(3), pp. 196-208 doi:10.1177/0165551505052347
- van der Hoeven, J.R., van Wijngaarden, H., Verdegem, R., Slats, J., 2005. Emulation – a viable preservation strategy. [online] Koninklijke Bibliotheek / Nationaal Archief: The Hague, The Netherlands.
- Lorie R. A., van Diessen R. J., 2005. Long-term preservation of complex processes. Archiving 2005, Vol. 2, pp. 14-19
Further reading
- Caplan, P. (2008), "The preservation of Digital Materials, Chapter 2: Preservation Practices", Library Technology Reports, 44 (2): 10–13
- Bearman, B. (1999), "Reality and Chimeras in the Preservation of Electronic Records", D-Lib Magazine, 5 (4)
- Granger, S. (2000), "Emulation as a Digital preservation strategy", D-Lib Magazine, 6 (10), doi:10.1045/october2000-granger
- Hendley, T. (1998), Comparison of Methods & Costs of Digital Preservation. British Library Research and Innovation Report 106, Boston Spa: British Library and Innovation Centre
- Rothenberg, J. (1999), Avoiding Technological Quicksand: Finding a Viable Technical Foundation for Digital Preservation. A report to the Council on Library and Information Resources
- Rusbridge C. (2006), "Excuse Me… Some Digital Preservation Fallacies?", Ariadne (46)
- van der Hoeven, J.R., van Wijngaarden, H.N. (2005), "Modular emulation as a long-term preservation strategy for digital objects" (PDF), Proceedings of IWAW, Vienna, Austria [online] 22 and 23 September 2005CS1 maint: multiple names: authors list (link)
External links
- UVC demonstration tool - Freely available UVC demonstration tool from IBM.
- E-depot and digital preservation - Link to KB's "e-depot and digital preservation" page.
- KB, UVC for images - Short description of the UVC for images
- Dioscuri software - Open source software for any individual or institution that would like to work with their older digital documents again
- PLANETS partners - Short description of the role of IBM within the PLANETS project