UPGMA
UPGMA (unweighted pair group method with arithmetic mean) is a simple agglomerative (bottom-up) hierarchical clustering method. The method is generally attributed to Sokal and Michener.[1]
The UPGMA method is similar to its weighted variant, the WPGMA method.
Note that the unweighted term indicates that all distances contribute equally to each average that is computed and does not refer to the math by which it is achieved. Thus the simple averaging in WPGMA produces a weighted result and the proportional averaging in UPGMA produces an unweighted result (see the working example).[2]
Algorithm
The UPGMA algorithm constructs a rooted tree (dendrogram) that reflects the structure present in a pairwise similarity matrix (or a dissimilarity matrix). At each step, the nearest two clusters are combined into a higher-level cluster. The distance between any two clusters and , each of size (i.e., cardinality) and , is taken to be the average of all distances between pairs of objects in and in , that is, the mean distance between elements of each cluster:








In other words, at each clustering step, the updated distance between the joined clusters and a new cluster is given by the proportional averaging of the and distances:





The UPGMA algorithm produces rooted dendrograms and requires a constant-rate assumption - that is, it assumes an ultrametric tree in which the distances from the root to every branch tip are equal. When the tips are molecular data (i.e., DNA, RNA and protein) sampled at the same time, the ultrametricity assumption becomes equivalent to assuming a molecular clock.
Working example
This working example is based on a JC69 genetic distance matrix computed from the 5S ribosomal RNA sequence alignment of five bacteria: Bacillus subtilis (), Bacillus stearothermophilus (), Lactobacillus viridescens (), Acholeplasma modicum (), and Micrococcus luteus ().[3][4]





First step
- First clustering
Let us assume that we have five elements and the following matrix of pairwise distances between them :


| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 0 | 17 | 21 | 31 | 23 |
| b | 17 | 0 | 30 | 34 | 21 |
| c | 21 | 30 | 0 | 28 | 39 |
| d | 31 | 34 | 28 | 0 | 43 |
| e | 23 | 21 | 39 | 43 | 0 |
In this example, is the smallest value of , so we join elements and .

- First branch length estimation
Let denote the node to which and are now connected. Setting ensures that elements and are equidistant from . This corresponds to the expectation of the ultrametricity hypothesis. The branches joining and to then have lengths (see the final dendrogram)



- First distance matrix update
We then proceed to update the initial distance matrix into a new distance matrix (see below), reduced in size by one row and one column because of the clustering of with . Bold values in correspond to the new distances, calculated by averaging distances between each element of the first cluster and each of the remaining elements:





Italicized values in are not affected by the matrix update as they correspond to distances between elements not involved in the first cluster.
Second step
- Second clustering
We now reiterate the three previous steps, starting from the new distance matrix
| (a,b) | c | d | e | |
|---|---|---|---|---|
| (a,b) | 0 | 25.5 | 32.5 | 22 |
| c | 25.5 | 0 | 28 | 39 |
| d | 32.5 | 28 | 0 | 43 |
| e | 22 | 39 | 43 | 0 |
Here, is the smallest value of , so we join cluster and element .

- Second branch length estimation
Let denote the node to which and are now connected. Because of the ultrametricity constraint, the branches joining or to , and to are equal and have the following length:


We deduce the missing branch length: (see the final dendrogram)

- Second distance matrix update
We then proceed to update into a new distance matrix (see below), reduced in size by one row and one column because of the clustering of with . Bold values in correspond to the new distances, calculated by proportional averaging:


Thanks to this proportional average, the calculation of this new distance accounts for the larger size of the cluster (two elements) with respect to (one element). Similarly:

Proportional averaging therefore gives equal weight to the initial distances of matrix . This is the reason why the method is unweighted, not with respect to the mathematical procedure but with respect to the initial distances.
Third step
- Third clustering
We again reiterate the three previous steps, starting from the updated distance matrix .
| ((a,b),e) | c | d | |
|---|---|---|---|
| ((a,b),e) | 0 | 30 | 36 |
| c | 30 | 0 | 28 |
| d | 36 | 28 | 0 |
Here, is the smallest value of , so we join elements and .

- Third branch length estimation
Let denote the node to which and are now connected. The branches joining and to then have lengths (see the final dendrogram)


- Third distance matrix update
There is a single entry to update, keeping in mind that the two elements and each have a contribution of in the average computation:


Final step
The final matrix is:

| ((a,b),e) | (c,d) | |
|---|---|---|
| ((a,b),e) | 0 | 33 |
| (c,d) | 33 | 0 |
So we join clusters and .


Let denote the (root) node to which and are now connected. The branches joining and to then have lengths:


We deduce the two remaining branch lengths:


The UPGMA dendrogram
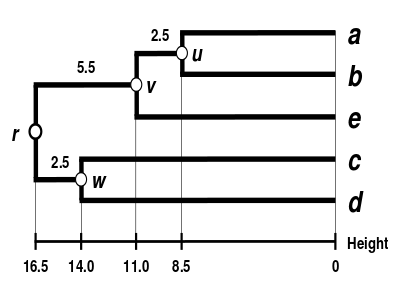
The dendrogram is now complete.[5] It is ultrametric because all tips ( to ) are equidistant from :

The dendrogram is therefore rooted by , its deepest node.
Comparison with other linkages
Alternative linkage schemes include single linkage clustering, complete linkage clustering, and WPGMA average linkage clustering. Implementing a different linkage is simply a matter of using a different formula to calculate inter-cluster distances during the distance matrix update steps of the above algorithm. Complete linkage clustering avoids a drawback of the alternative single linkage clustering method - the so-called chaining phenomenon, where clusters formed via single linkage clustering may be forced together due to single elements being close to each other, even though many of the elements in each cluster may be very distant to each other. Complete linkage tends to find compact clusters of approximately equal diameters.[6]
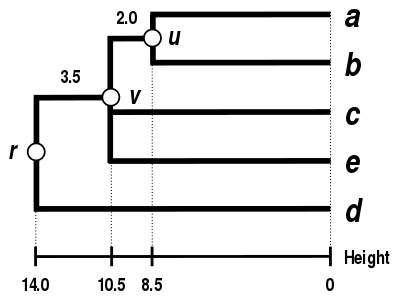 |
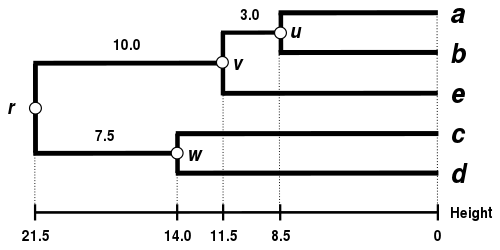 |
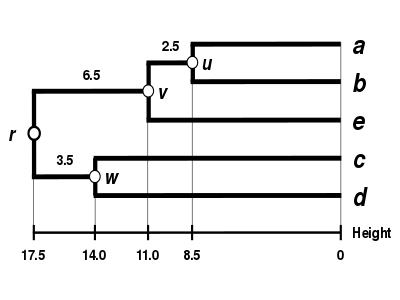 |
|
| Single-linkage clustering. | Complete-linkage clustering. | Average linkage clustering: WPGMA. | Average linkage clustering: UPGMA. |
Uses
- In ecology, it is one of the most popular methods for the classification of sampling units (such as vegetation plots) on the basis of their pairwise similarities in relevant descriptor variables (such as species composition).[7] For example, it has been used to understand the trophic interaction between marine bacteria and protists.[8]
- In bioinformatics, UPGMA is used for the creation of phenetic trees (phenograms). UPGMA was initially designed for use in protein electrophoresis studies, but is currently most often used to produce guide trees for more sophisticated algorithms. This algorithm is for example used in sequence alignment procedures, as it proposes one order in which the sequences will be aligned. Indeed, the guide tree aims at grouping the most similar sequences, regardless of their evolutionary rate or phylogenetic affinities, and that is exactly the goal of UPGMA[9]
- In phylogenetics, UPGMA assumes a constant rate of evolution (molecular clock hypothesis) and that all sequences were sampled at the same time, and is not a well-regarded method for inferring relationships unless this assumption has been tested and justified for the data set being used. Notice that even under a 'strict clock', sequences sampled at different times should not lead to an ultrametric tree.
Time complexity
A trivial implementation of the algorithm to construct the UPGMA tree has time complexity, and using a heap for each cluster to keep its distances from other cluster reduces its time to . Fionn Murtagh presented some other approaches for special cases, a time algorithm by Day and Edelsbrunner[10] for k-dimensional data that is optimal for constant k, and another algorithm for restricted inputs, when "the agglomerative strategy satisfies the reducibility property."[11]




See also
References
- Sokal, Michener (1958). "A statistical method for evaluating systematic relationships". University of Kansas Science Bulletin. 38: 1409–1438.
- Garcia S, Puigbò P. "DendroUPGMA: A dendrogram construction utility" (PDF). p. 4.
- Erdmann VA, Wolters J (1986). "Collection of published 5S, 5.8S and 4.5S ribosomal RNA sequences". Nucleic Acids Research. 14 Suppl (Suppl): r1–59. doi:10.1093/nar/14.suppl.r1. PMC 341310. PMID 2422630.
- Olsen GJ (1988). "Phylogenetic analysis using ribosomal RNA". Methods in Enzymology. 164: 793–812. doi:10.1016/s0076-6879(88)64084-5. PMID 3241556.
- Swofford DL, Olsen GJ, Waddell PJ, Hillis DM (1996). "Phylogenetic inference". In Hillis DM, Moritz C, Mable BK (eds.). Molecular Systematics, 2nd edition. Sunderland, MA: Sinauer. pp. 407–514. ISBN 9780878932825.
- Everitt, B. S.; Landau, S.; Leese, M. (2001). Cluster Analysis. 4th Edition. London: Arnold. p. 62–64.
- Legendre P, Legendre L (1998). Numerical Ecology. Developments in Environmental Modelling. 20 (Second English ed.). Amsterdam: Elsevier.
- Vázquez-Domínguez E, Casamayor EO, Català P, Lebaron P (April 2005). "Different marine heterotrophic nanoflagellates affect differentially the composition of enriched bacterial communities". Microbial Ecology. 49 (3): 474–85. doi:10.1007/s00248-004-0035-5. JSTOR 25153200. PMID 16003474.
- Wheeler TJ, Kececioglu JD (July 2007). "Multiple alignment by aligning alignments". Bioinformatics. 23 (13): i559–68. doi:10.1093/bioinformatics/btm226. PMID 17646343.
- Day WH, Edelsbrunner H (1984-12-01). "Efficient algorithms for agglomerative hierarchical clustering methods". Journal of Classification. 1 (1): 7–24. doi:10.1007/BF01890115. ISSN 0176-4268.
- Murtagh F (1984). "Complexities of Hierarchic Clustering Algorithms: the state of the art". Computational Statistics Quarterly. 1: 101–113.
External links
- UPGMA clustering algorithm implementation in Ruby (AI4R)
- Example calculation of UPGMA using a similarity matrix
- Example calculation of UPGMA using a distance matrix
| Relevant fields | ||
|---|---|---|
| Basic concepts | ||
| Inference methods |
| |
| Current topics | ||
| Group traits | ||
| Group types | ||
| Nomenclature | ||
| ||