Complete-linkage clustering
Complete-linkage clustering is one of several methods of agglomerative hierarchical clustering. At the beginning of the process, each element is in a cluster of its own. The clusters are then sequentially combined into larger clusters until all elements end up being in the same cluster. The method is also known as farthest neighbour clustering. The result of the clustering can be visualized as a dendrogram, which shows the sequence of cluster fusion and the distance at which each fusion took place.[1][2][3]
Clustering procedure
At each step, the two clusters separated by the shortest distance are combined. The definition of 'shortest distance' is what differentiates between the different agglomerative clustering methods. In complete-linkage clustering, the link between two clusters contains all element pairs, and the distance between clusters equals the distance between those two elements (one in each cluster) that are farthest away from each other. The shortest of these links that remains at any step causes the fusion of the two clusters whose elements are involved.
Mathematically, the complete linkage function — the distance between clusters and — is described by the following expression :




where
- is the distance between elements and ;
- and are two sets of elements (clusters).



Algorithms
Naive scheme
The following algorithm is an agglomerative scheme that erases rows and columns in a proximity matrix as old clusters are merged into new ones. The proximity matrix D contains all distances d(i,j). The clusterings are assigned sequence numbers 0,1,......, (n − 1) and L(k) is the level of the kth clustering. A cluster with sequence number m is denoted (m) and the proximity between clusters (r) and (s) is denoted d[(r),(s)].

The complete linkage clustering algorithm consists of the following steps:
- Begin with the disjoint clustering having level and sequence number .
- Find the most similar pair of clusters in the current clustering, say pair , according to where the minimum is over all pairs of clusters in the current clustering.
- Increment the sequence number: . Merge clusters and into a single cluster to form the next clustering . Set the level of this clustering to
- Update the proximity matrix, , by deleting the rows and columns corresponding to clusters and and adding a row and column corresponding to the newly formed cluster. The proximity between the new cluster, denoted and old cluster is defined as .
- If all objects are in one cluster, stop. Else, go to step 2.













Optimally efficient scheme
The algorithm explained above is easy to understand but of complexity . In May 1976, D. Defays proposed an optimally efficient algorithm of only complexity known as CLINK (published 1977)[4] inspired by the similar algorithm SLINK for single-linkage clustering.


Working example
The working example is based on a JC69 genetic distance matrix computed from the 5S ribosomal RNA sequence alignment of five bacteria: Bacillus subtilis (), Bacillus stearothermophilus (), Lactobacillus viridescens (), Acholeplasma modicum (), and Micrococcus luteus ().[5][6]





First step
- First clustering
Let us assume that we have five elements and the following matrix of pairwise distances between them:


| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 0 | 17 | 21 | 31 | 23 |
| b | 17 | 0 | 30 | 34 | 21 |
| c | 21 | 30 | 0 | 28 | 39 |
| d | 31 | 34 | 28 | 0 | 43 |
| e | 23 | 21 | 39 | 43 | 0 |
In this example, is the smallest value of , so we join elements and .

- First branch length estimation
Let denote the node to which and are now connected. Setting ensures that elements and are equidistant from . This corresponds to the expectation of the ultrametricity hypothesis. The branches joining and to then have lengths (see the final dendrogram)



- First distance matrix update
We then proceed to update the initial proximity matrix into a new proximity matrix (see below), reduced in size by one row and one column because of the clustering of with . Bold values in correspond to the new distances, calculated by retaining the maximum distance between each element of the first cluster and each of the remaining elements:





Italicized values in are not affected by the matrix update as they correspond to distances between elements not involved in the first cluster.
Second step
- Second clustering
We now reiterate the three previous steps, starting from the new distance matrix :
| (a,b) | c | d | e | |
|---|---|---|---|---|
| (a,b) | 0 | 30 | 34 | 23 |
| c | 30 | 0 | 28 | 39 |
| d | 34 | 28 | 0 | 43 |
| e | 23 | 39 | 43 | 0 |
Here, is the lowest value of , so we join cluster with element .

- Second branch length estimation
Let denote the node to which and are now connected. Because of the ultrametricity constraint, the branches joining or to , and to , are equal and have the following total length:


We deduce the missing branch length: (see the final dendrogram)

- Second distance matrix update
We then proceed to update the matrix into a new distance matrix (see below), reduced in size by one row and one column because of the clustering of with :



Third step
- Third clustering
We again reiterate the three previous steps, starting from the updated distance matrix .
| ((a,b),e) | c | d | |
|---|---|---|---|
| ((a,b),e) | 0 | 39 | 43 |
| c | 39 | 0 | 28 |
| d | 43 | 28 | 0 |
Here, is the smallest value of , so we join elements and .

- Third branch length estimation
Let denote the node to which and are now connected. The branches joining and to then have lengths (see the final dendrogram)


- Third distance matrix update
There is a single entry to update:

Final step
The final matrix is:

| ((a,b),e) | (c,d) | |
|---|---|---|
| ((a,b),e) | 0 | 43 |
| (c,d) | 43 | 0 |
So we join clusters and .


Let denote the (root) node to which and are now connected. The branches joining and to then have lengths:


We deduce the two remaining branch lengths:


The complete-linkage dendrogram
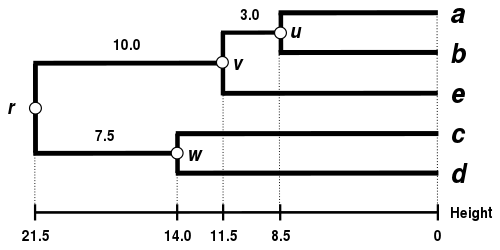
The dendrogram is now complete. It is ultrametric because all tips ( to ) are equidistant from :

The dendrogram is therefore rooted by , its deepest node.
Comparison with other linkages
Alternative linkage schemes include single linkage clustering and average linkage clustering - implementing a different linkage in the naive algorithm is simply a matter of using a different formula to calculate inter-cluster distances in the initial computation of the proximity matrix and in step 4 of the above algorithm. An optimally efficient algorithm is however not available for arbitrary linkages. The formula that should be adjusted has been highlighted using bold text.
Complete linkage clustering avoids a drawback of the alternative single linkage method - the so-called chaining phenomenon, where clusters formed via single linkage clustering may be forced together due to single elements being close to each other, even though many of the elements in each cluster may be very distant to each other. Complete linkage tends to find compact clusters of approximately equal diameters.[7]
 |
|
 |
 |
| Single-linkage clustering. | Complete-linkage clustering. | Average linkage clustering: WPGMA. | Average linkage clustering: UPGMA. |
See also
References
- Sorensen T (1948). "A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons". Biologiske Skrifter. 5: 1–34.
- Legendre P, Legendre L (1998). Numerical Ecology (Second English ed.). p. 853.
- Everitt BS, Landau S, Leese M (2001). Cluster Analysis (Fourth ed.). London: Arnold. ISBN 0-340-76119-9.
- Defays D (1977). "An efficient algorithm for a complete link method" (PDF). The Computer Journal. British Computer Society. 20 (4): 364–366. doi:10.1093/comjnl/20.4.364.
- Erdmann VA, Wolters J (1986). "Collection of published 5S, 5.8S and 4.5S ribosomal RNA sequences". Nucleic Acids Research. 14 Suppl (Suppl): r1-59. doi:10.1093/nar/14.suppl.r1. PMC 341310. PMID 2422630.
- Olsen GJ (1988). "Phylogenetic analysis using ribosomal RNA". Methods in Enzymology. 164: 793–812. doi:10.1016/s0076-6879(88)64084-5. PMID 3241556.
- Everitt, Landau and Leese (2001), pp. 62-64.
Further reading
- Späth H (1980). Cluster Analysis Algorithms. Chichester: Ellis Horwood.