Pumping lemma for regular languages
In the theory of formal languages, the pumping lemma for regular languages is a lemma that describes an essential property of all regular languages. Informally, it says that all sufficiently long words in a regular language may be pumped—that is, have a middle section of the word repeated an arbitrary number of times—to produce a new word that also lies within the same language.
Specifically, the pumping lemma says that for any regular language there exists a constant such that any word in with length at least can be split into three substrings, , where the middle portion must not be empty, such that the words constructed by repeating zero or more times are still in . This process of repetition is known as "pumping". Moreover, the pumping lemma guarantees that the length of will be at most , imposing a limit on the ways in which may be split. Finite languages vacuously satisfy the pumping lemma by having equal to the maximum string length in plus one.







The pumping lemma is useful for disproving the regularity of a specific language in question. It was first proven by Michael Rabin and Dana Scott in 1959,[1] and rediscovered shortly after by Yehoshua Bar-Hillel, Micha A. Perles, and Eli Shamir in 1961, as a simplification of their pumping lemma for context-free languages.[2][3]
Formal statement
Let be a regular language. Then there exists an integer depending only on such that every string in of length at least ( is called the "pumping length"[4]) can be written as (i.e., can be divided into three substrings), satisfying the following conditions:




is the substring that can be pumped (removed or repeated any number of times, and the resulting string is always in ). (1) means the loop to be pumped must be of length at least one; (2) means the loop must occur within the first characters. must be smaller than (conclusion of (1) and (2)), but apart from that, there is no restriction on and .



In simple words, for any regular language , any sufficiently long word (in ) can be split into 3 parts. i.e. , such that all the strings for are also in .


Below is a formal expression of the Pumping Lemma.

Use of the lemma
The pumping lemma is often used to prove that a particular language is non-regular: a proof by contradiction (of the language's regularity) may consist of exhibiting a word (of the required length) in the language that lacks the property outlined in the pumping lemma.
For example, the language over the alphabet can be shown to be non-regular as follows:


Let , and be as used in the formal statement for the pumping lemma above. We assume that there exists some constant . Let in be given by , which is a string longer than . By the pumping lemma, there must be some decomposition with and such that in for every . Using , we know only consists of instances of . Moreover, because , it contains at least one instance of the letter . We now pump up: has more instances of the letter than the letter , since we have added some instances of without adding instances of . Therefore, is not in . We have reached a contradiction. Therefore, the assumption that is regular (i.e. there exists such a ) must be incorrect. Hence is not regular.








The proof that the language of balanced (i.e., properly nested) parentheses is not regular follows the same idea. Given , there is a string of balanced parentheses that begins with more than left parentheses, so that will consist entirely of left parentheses. By repeating , we can produce a string that does not contain the same number of left and right parentheses, and so they cannot be balanced.
Proof of the pumping lemma
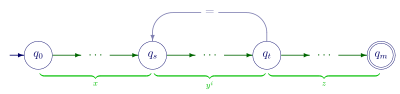

For every regular language there is a finite state automaton (FSA) that accepts the language. The number of states in such an FSA are counted and that count is used as the pumping length . For a string of length at least , let be the start state and let be the sequence of the next states visited as the string is emitted. Because the FSA has only states, within this sequence of visited states there must be at least one state that is repeated. Write for such a state. The transitions that take the machine from the first encounter of state to the second encounter of state match some string. This string is called in the lemma, and since the machine will match a string without the portion, or with the string repeated any number of times, the conditions of the lemma are satisfied.




For example, the following image shows an FSA.
*d.svg.png)
The FSA accepts the string: abcd. Since this string has a length at least as large as the number of states, which is four, the pigeonhole principle indicates that there must be at least one repeated state among the start state and the next four visited states. In this example, only is a repeated state. Since the substring bc takes the machine through transitions that start at state and end at state , that portion could be repeated and the FSA would still accept, giving the string abcbcd. Alternatively, the bc portion could be removed and the FSA would still accept giving the string ad. In terms of the pumping lemma, the string abcd is broken into an portion a, a portion bc and a portion d.

General version of pumping lemma for regular languages
If a language is regular, then there exists a number (the pumping length) such that every string in with |w| ≥ p can be written in the form


with strings , and such that , and
- is in for every integer .[5]

From this, the above standard version follows a special case, with both and being the empty string.


Since the general version imposes stricter requirements on the language, it can be used to prove the non-regularity of many more languages, such as .[6]

Converse of lemma not true
While the pumping lemma states that all regular languages satisfy the conditions described above, the converse of this statement is not true: a language that satisfies these conditions may still be non-regular. In other words, both the original and the general version of the pumping lemma give a necessary but not sufficient condition for a language to be regular.
For example, consider the following language:
- .

In other words, contains all strings over the alphabet with a substring of length 3 including a duplicate character, as well as all strings over this alphabet where precisely 1/7 of the string's characters are 3's. This language is not regular but can still be "pumped" with . Suppose some string s has length at least 5. Then, since the alphabet has only four characters, at least two of the first five characters in the string must be duplicates. They are separated by at most three characters.


- If the duplicate characters are separated by 0 characters, or 1, pump one of the other two characters in the string, which will not affect the substring containing the duplicates.
- If the duplicate characters are separated by 2 or 3 characters, pump 2 of the characters separating them. Pumping either down or up results in the creation of a substring of size 3 that contains 2 duplicate characters.
- The second condition of ensures that is not regular: Consider the string . This string is in exactly when and thus is not regular by the Myhill–Nerode theorem.


The Myhill–Nerode theorem provides a test that exactly characterizes regular languages. The typical method for proving that a language is regular is to construct either a finite state machine or a regular expression for the language.
Notes
- Rabin, Michael; Scott, Dana (Apr 1959). "Finite Automata and Their Decision Problems" (PDF). IBM Journal of Research and Development. 3 (2): 114–125. doi:10.1147/rd.32.0114. Archived from the original on December 14, 2010.CS1 maint: unfit url (link) Here: Lemma 8, p.119
- Bar-Hillel, Y.; Perles, M.; Shamir, E. (1961), "On formal properties of simple phrase structure grammars", Zeitschrift für Phonetik, Sprachwissenschaft und Kommunikationsforschung, 14 (2): 143–172
- John E. Hopcroft; Rajeev Motwani; Jeffrey D. Ullman (2003). Introduction to Automata Theory, Languages, and Computation. Addison Wesley. Here: Sect.4.6, p.166
- Berstel, Jean; Lauve, Aaron; Reutenauer, Christophe; Saliola, Franco V. (2009). Combinatorics on words. Christoffel words and repetitions in words. CRM Monograph Series. 27. Providence, RI: American Mathematical Society. p. 86. ISBN 978-0-8218-4480-9. Zbl 1161.68043.
- Savitch, Walter (1982). Abstract Machines and Grammars. p. 49. ISBN 978-0-316-77161-0.
- John E. Hopcroft & Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Reading/MA: Addison-Wesley. ISBN 978-0-201-02988-8. Here: p. 72, Exercise 3.2 (which give a slightly less general version, requiring |w|=p) and 3.3
References
- Lawson, Mark V. (2004). Finite automata. Chapman and Hall/CRC. ISBN 978-1-58488-255-8. Zbl 1086.68074.
- Sipser, Michael (1997). "1.4: Nonregular Languages". Introduction to the Theory of Computation. PWS Publishing. pp. 77–83. ISBN 978-0-534-94728-6. Zbl 1169.68300.
- Hopcroft, John E.; Ullman, Jeffrey D. (1979). Introduction to Automata Theory, Languages, and Computation. Reading, Massachusetts: Addison-Wesley Publishing. ISBN 978-0-201-02988-8. Zbl 0426.68001. (See chapter 3.)
- Bakhadyr Khoussainov; Anil Nerode (6 December 2012). Automata Theory and its Applications. Springer Science & Business Media. ISBN 978-1-4612-0171-7.