RNA-Seq
RNA-Seq (named as an abbreviation of "RNA sequencing") is a particular technology-based sequencing technique which uses next-generation sequencing (NGS) to reveal the presence and quantity of RNA in a biological sample at a given moment, analyzing the continuously changing cellular transcriptome.[2][3]
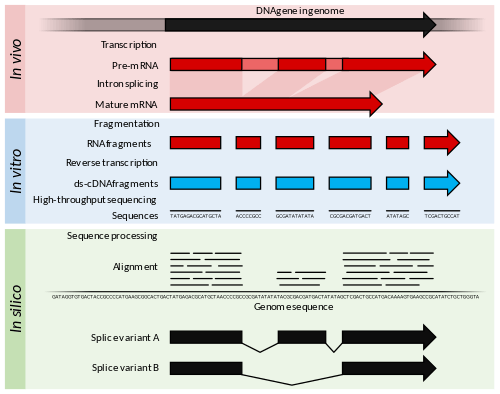
Specifically, RNA-Seq facilitates the ability to look at alternative gene spliced transcripts, post-transcriptional modifications, gene fusion, mutations/SNPs and changes in gene expression over time, or differences in gene expression in different groups or treatments.[4] In addition to mRNA transcripts, RNA-Seq can look at different populations of RNA to include total RNA, small RNA, such as miRNA, tRNA, and ribosomal profiling.[5] RNA-Seq can also be used to determine exon/intron boundaries and verify or amend previously annotated 5' and 3' gene boundaries. Recent advances in RNA-Seq include single cell sequencing and in situ sequencing of fixed tissue.[6]
Prior to RNA-Seq, gene expression studies were done with hybridization-based microarrays. Issues with microarrays include cross-hybridization artifacts, poor quantification of lowly and highly expressed genes, and needing to know the sequence a priori.[7] Because of these technical issues, transcriptomics transitioned to sequencing-based methods. These progressed from Sanger sequencing of Expressed Sequence Tag libraries, to chemical tag-based methods (e.g., serial analysis of gene expression), and finally to the current technology, next-gen sequencing of cDNA (notably RNA-Seq).
Methods
Library preparation
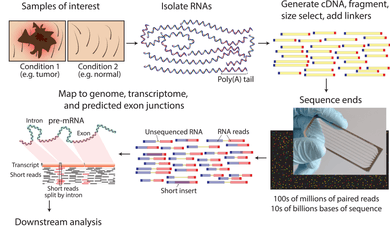
The general steps to prepare a complementary DNA (cDNA) library for sequencing are described below, but often vary between platforms.[8][3][9]
- RNA Isolation: RNA is isolated from tissue and mixed with deoxyribonuclease (DNase). DNase reduces the amount of genomic DNA. The amount of RNA degradation is checked with gel and capillary electrophoresis and is used to assign an RNA integrity number to the sample. This RNA quality and the total amount of starting RNA are taken into consideration during the subsequent library preparation, sequencing, and analysis steps.
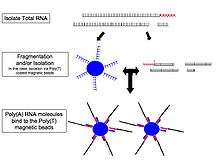
- RNA selection/depletion: To analyze signals of interest, the isolated RNA can either be kept as is, filtered for RNA with 3' polyadenylated (poly(A)) tails to include only mRNA, depleted of ribosomal RNA (rRNA), and/or filtered for RNA that binds specific sequences (RNA selection and depletion methods table, below). The RNA with 3' poly(A) tails are mature, processed, coding sequences. Poly(A) selection is performed by mixing RNA with poly(T) oligomers covalently attached to a substrate, typically magnetic beads.[10][11] Poly(A) selection ignores noncoding RNA and introduces 3' bias,[12] which is avoided with the ribosomal depletion strategy. The rRNA is removed because it represents over 90% of the RNA in a cell, which if kept would drown out other data in the transcriptome.
- cDNA synthesis: RNA is reverse transcribed to cDNA because DNA is more stable and to allow for amplification (which uses DNA polymerases) and leverage more mature DNA sequencing technology. Amplification subsequent to reverse transcription results in loss of strandedness, which can be avoided with chemical labeling or single molecule sequencing. Fragmentation and size selection are performed to purify sequences that are the appropriate length for the sequencing machine. The RNA, cDNA, or both are fragmented with enzymes, sonication, or nebulizers. Fragmentation of the RNA reduces 5' bias of randomly primed-reverse transcription and the influence of primer binding sites,[11] with the downside that the 5' and 3' ends are converted to DNA less efficiently. Fragmentation is followed by size selection, where either small sequences are removed or a tight range of sequence lengths are selected. Because small RNAs like miRNAs are lost, these are analyzed independently. The cDNA for each experiment can be indexed with a hexamer or octamer barcode, so that these experiments can be pooled into a single lane for multiplexed sequencing.
| Strategy | Type of RNA | Ribosomal RNA content | Unprocessed RNA content | Genomic DNA content | Isolation method |
|---|---|---|---|---|---|
| Total RNA | All | High | High | High | None |
| PolyA selection | Coding | Low | Low | Low | Hybridization with poly(dT) oligomers |
| rRNA depletion | Coding, noncoding | Low | High | High | Removal of oligomers complementary to rRNA |
| RNA capture | Targeted | Low | Moderate | Low | Hybridization with probes complementary to desired transcripts |
Small RNA/non-coding RNA sequencing
When sequencing RNA other than mRNA, the library preparation is modified. The cellular RNA is selected based on the desired size range. For small RNA targets, such as miRNA, the RNA is isolated through size selection. This can be performed with a size exclusion gel, through size selection magnetic beads, or with a commercially developed kit. Once isolated, linkers are added to the 3' and 5' end then purified. The final step is cDNA generation through reverse transcription.
Direct RNA sequencing

Because converting RNA into cDNA, ligation, amplification, and other sample manipulations have been shown to introduce biases and artifacts that may interfere with both the proper characterization and quantification of transcripts,[13] single molecule direct RNA sequencing has been explored by companies including Helicos (bankrupt), Oxford Nanopore Technologies,[14] and others. This technology sequences RNA molecules directly in a massively-parallel manner.
Single-cell RNA sequencing (scRNA-Seq)
Standard methods such as microarrays and standard bulk RNA-Seq analysis analyze the expression of RNAs from large populations of cells. In mixed cell populations, these measurements may obscure critical differences between individual cells within these populations.[15][16]
Single-cell RNA sequencing (scRNA-Seq) provides the expression profiles of individual cells. Although it is not possible to obtain complete information on every RNA expressed by each cell, due to the small amount of material available, patterns of gene expression can be identified through gene clustering analyses. This can uncover the existence of rare cell types within a cell population that may never have been seen before. For example, rare specialized cells in the lung called pulmonary ionocytes that express the Cystic Fibrosis Transmembrane Conductance Regulator were identified in 2018 by two groups performing scRNA-Seq on lung airway epithelia.[17][18]
Experimental procedures
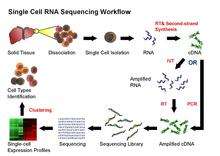
Current scRNA-Seq protocols involve the following steps: isolation of single cell and RNA, reverse transcription (RT), amplification, library generation and sequencing. Early methods separated individual cells into separate wells; more recent methods encapsulate individual cells in droplets in a microfluidic device, where the reverse transcription reaction takes place, converting RNAs to cDNAs. Each droplet carries a DNA "barcode" that uniquely labels the cDNAs derived from a single cell. Once reverse transcription is complete, the cDNAs from many cells can be mixed together for sequencing; transcripts from a particular cell are identified by the unique barcode.[19][20]
Challenges for scRNA-Seq include preserving the initial relative abundance of mRNA in a cell and identifying rare transcripts.[21] The reverse transcription step is critical as the efficiency of the RT reaction determines how much of the cell's RNA population will be eventually analyzed by the sequencer. The processivity of reverse transcriptases and the priming strategies used may affect full-length cDNA production and the generation of libraries biased toward 3’ or 5' end of genes.
In the amplification step, either PCR or in vitro transcription (IVT) is currently used to amplify cDNA. One of the advantages of PCR-based methods is the ability to generate full-length cDNA. However, different PCR efficiency on particular sequences (for instance, GC content and snapback structure) may also be exponentially amplified, producing libraries with uneven coverage. On the other hand, while libraries generated by IVT can avoid PCR-induced sequence bias, specific sequences may be transcribed inefficiently, thus causing sequence drop-out or generating incomplete sequences.[22][15] Several scRNA-Seq protocols have been published: Tang et al.,[23] STRT,[24] SMART-seq,[25] CEL-seq,[26] RAGE-seq,[27] , Quartz-seq.[28] and C1-CAGE.[29] These protocols differ in terms of strategies for reverse transcription, cDNA synthesis and amplification, and the possibility to accommodate sequence-specific barcodes (i.e. UMIs) or the ability to process pooled samples.[30]
In 2017, two approaches were introduced to simultaneously measure single-cell mRNA and protein expression through oligonucleotide-labeled antibodies known as REAP-seq,[31] and CITE-seq.[32]
Applications
scRNA-Seq is becoming widely used across biological disciplines including Development, Neurology,[33] Oncology,[34][35][36] Autoimmune disease,[37] and Infectious disease.[38]
scRNA-Seq has provided considerable insight into the development of embryos and organisms, including the worm Caenorhabditis elegans,[39] and the regenerative planarian Schmidtea mediterranea.[40][41] The first vertebrate animals to be mapped in this way were Zebrafish[42][43] and Xenopus laevis.[44] In each case multiple stages of the embryo were studied, allowing the entire process of development to be mapped on a cell-by-cell basis.[8] Science recognized these advances as the 2018 Breakthrough of the Year.[45]
Experimental considerations
A variety of parameters are considered when designing and conducting RNA-Seq experiments:
- Tissue specificity: Gene expression varies within and between tissues, and RNA-Seq measures this mix of cell types. This may make it difficult to isolate the biological mechanism of interest. Single cell sequencing can be used to study each cell individually, mitigating this issue.
- Time dependence: Gene expression changes over time, and RNA-Seq only takes a snapshot. Time course experiments can be performed to observe changes in the transcriptome.
- Coverage (also known as depth): RNA harbors the same mutations observed in DNA, and detection requires deeper coverage. With high enough coverage, RNA-Seq can be used to estimate the expression of each allele. This may provide insight into phenomena such as imprinting or cis-regulatory effects. The depth of sequencing required for specific applications can be extrapolated from a pilot experiment.[46]
- Data generation artifacts (also known as technical variance): The reagents (e.g., library preparation kit), personnel involved, and type of sequencer (e.g., Illumina, Pacific Biosciences) can result in technical artifacts that might be mis-interpreted as meaningful results. As with any scientific experiment, it is prudent to conduct RNA-Seq in a well controlled setting. If this is not possible or the study is a meta-analysis, another solution is to detect technical artifacts by inferring latent variables (typically principal component analysis or factor analysis) and subsequently correcting for these variables.[47]
- Data management: A single RNA-Seq experiment in humans is usually on the order of 1 Gb.[48] This large volume of data can pose storage issues. One solution is compressing the data using multi-purpose computational schemas (e.g., gzip) or genomics-specific schemas. The latter can be based on reference sequences or de novo. Another solution is to perform microarray experiments, which may be sufficient for hypothesis-driven work or replication studies (as opposed to exploratory research).
Analysis
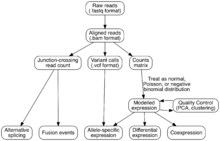
Transcriptome assembly
Two methods are used to assign raw sequence reads to genomic features (i.e., assemble the transcriptome):
- De novo: This approach does not require a reference genome to reconstruct the transcriptome, and is typically used if the genome is unknown, incomplete, or substantially altered compared to the reference.[49] Challenges when using short reads for de novo assembly include 1) determining which reads should be joined together into contiguous sequences (contigs), 2) robustness to sequencing errors and other artifacts, and 3) computational efficiency. The primary algorithm used for de novo assembly transitioned from overlap graphs, which identify all pair-wise overlaps between reads, to de Bruijn graphs, which break reads into sequences of length k and collapse all k-mers into a hash table.[50] Overlap graphs were used with Sanger sequencing, but do not scale well to the millions of reads generated with RNA-Seq. Examples of assemblers that use de Bruijn graphs are Velvet,[51] Trinity,[49] Oases,[52] and Bridger.[53] Paired end and long read sequencing of the same sample can mitigate the deficits in short read sequencing by serving as a template or skeleton. Metrics to assess the quality of a de novo assembly include median contig length, number of contigs and N50.[54]
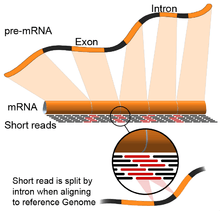
- Genome guided: This approach relies on the same methods used for DNA alignment, with the additional complexity of aligning reads that cover non-continuous portions of the reference genome.[55] These non-continuous reads are the result of sequencing spliced transcripts (see figure). Typically, alignment algorithms have two steps: 1) align short portions of the read (i.e., seed the genome), and 2) use dynamic programming to find an optimal alignment, sometimes in combination with known annotations. Software tools that use genome-guided alignment include Bowtie,[56] TopHat (which builds on BowTie results to align splice junctions),[57][58] Subread,[59] STAR,[55] HISAT2,[60] Sailfish,[61] Kallisto,[62] and GMAP.[63] The quality of a genome guided assembly can be measured with both 1) de novo assembly metrics (e.g., N50) and 2) comparisons to known transcript, splice junction, genome, and protein sequences using precision, recall, or their combination (e.g., F1 score).[54] In addition, in silico assessment could be performed using simulated reads.[64][65]
A note on assembly quality: The current consensus is that 1) assembly quality can vary depending on which metric is used, 2) assemblies that scored well in one species do not necessarily perform well in the other species, and 3) combining different approaches might be the most reliable.[66][67]
Gene expression quantification
Expression is quantified to study cellular changes in response to external stimuli, differences between healthy and diseased states, and other research questions. Gene expression is often used as a proxy for protein abundance, but these are often not equivalent due to post transcriptional events such as RNA interference and nonsense-mediated decay.[68]
Expression is quantified by counting the number of reads that mapped to each locus in the transcriptome assembly step. Expression can be quantified for exons or genes using contigs or reference transcript annotations.[8] These observed RNA-Seq read counts have been robustly validated against older technologies, including expression microarrays and qPCR.[46][69] Examples of tools that quantify counts are HTSeq,[70] FeatureCounts,[71] Rcount,[72] maxcounts,[73] FIXSEQ,[74] and Cuffquant. The read counts are then converted into appropriate metrics for hypothesis testing, regressions, and other analyses. Parameters for this conversion are:
- Sequencing depth/coverage: Although depth is pre-specified when conducting multiple RNA-Seq experiments, it will still vary widely between experiments.[75] Therefore, the total number of reads generated in a single experiment is typically normalized by converting counts to fragments, reads, or counts per million mapped reads (FPM, RPM, or CPM). Sequencing depth is sometimes referred to as library size, the number of intermediary cDNA molecules in the experiment.
- Gene length: Longer genes will have more fragments/reads/counts than shorter genes if transcript expression is the same. This is adjusted by dividing the FPM by the length of a gene, resulting in the metric fragments per kilobase of transcript per million mapped reads (FPKM).[76] When looking at groups of genes across samples, FPKM is converted to transcripts per million (TPM) by dividing each FPKM by the sum of FPKMs within a sample.[77][78][79]
- Total sample RNA output: Because the same amount of RNA is extracted from each sample, samples with more total RNA will have less RNA per gene. These genes appear to have decreased expression, resulting in false positives in downstream analyses.[75] Normalization strategies including quantile, DESeq2, TMM and Median Ratio attempt to account for this difference by comparing a set of non-differentially expressed genes between samples and scaling accordingly.[80]
- Variance for each gene's expression: is modeled to account for sampling error (important for genes with low read counts), increase power, and decrease false positives. Variance can be estimated as a normal, Poisson, or negative binomial distribution[81][82][83] and is frequently decomposed into technical and biological variance.
Absolute quantification
Absolute quantification of gene expression is not possible with most RNA-Seq experiments, which quantify expression relative to all transcripts. It is possible by performing RNA-Seq with spike-ins, samples of RNA at known concentrations. After sequencing, read counts of spike-in sequences are used to determine the relationship between each gene's read counts and absolute quantities of biological fragments.[11][84] In one example, this technique was used in Xenopus tropicalis embryos to determine transcription kinetics.[85]
Differential expression
The simplest but often most powerful use of RNA-Seq is finding differences in gene expression between two or more conditions (e.g., treated vs not treated); this process is called differential expression. The outputs are frequently referred to as differentially expressed genes (DEGs) and these genes can either be up- or down-regulated (i.e., higher or lower in the condition of interest). There are many tools that perform differential expression. Most are run in R, Python, or the Unix command line. Commonly used tools include DESeq,[82] edgeR,[83] and voom+limma,[81][86] all of which are available through R/Bioconductor.[87][88] These are the common considerations when performing differential expression:
- Inputs: Differential expression inputs include (1) an RNA-Seq expression matrix (M genes x N samples) and (2) a design matrix containing experimental conditions for N samples. The simplest design matrix contains one column, corresponding to labels for the condition being tested. Other covariates (also referred to as factors, features, labels, or parameters) can include batch effects, known artifacts, and any metadata that might confound or mediate gene expression. In addition to known covariates, unknown covariates can also be estimated through unsupervised machine learning approaches including principal component, surrogate variable,[89] and PEER[47] analyses. Hidden variable analyses are often employed for human tissue RNA-Seq data, which typically have additional artifacts not captured in the metadata (e.g., ischemic time, sourcing from multiple institutions, underlying clinical traits, collecting data across many years with many personnel).
- Methods: Most tools use regression or non-parametric statistics to identify differentially expressed genes, and are either count-based (DESeq2, limma, edgeR) or assembly-based (via alignment-free quantification, sleuth,[90] Cuffdiff,[91] Ballgown[92]).[93] Following regression, most tools employ either familywise error rate (FWER) or false discovery rate (FDR) p-value adjustments to account for multiple hypotheses (in human studies, ~20,000 protein-coding genes or ~50,000 biotypes).
- Outputs: A typical output consists of rows corresponding to the number of genes and at least three columns, each gene's log fold change (log-transform of the ratio in expression between conditions, a measure of effect size), p-value, and p-value adjusted for multiple comparisons. Genes are defined as biologically meaningful if they pass cut-offs for effect size (log fold change) and statistical significance. These cut-offs should ideally be specified a priori, but the nature of RNA-Seq experiments is often exploratory so it is difficult to predict effect sizes and pertinent cut-offs ahead of time.
- Pitfalls: The raison d'etre for these complex methods is to avoid the myriad of pitfalls that can lead to statistical errors and misleading interpretations. Pitfalls include increased false positive rates (due to multiple comparisons), sample preparation artifacts, sample heterogeneity (like mixed genetic backgrounds), highly correlated samples, unaccounted for multi-level experimental designs, and poor experimental design. One notable pitfall is viewing results in Microsoft Excel without utilizing the import feature to ensure that the gene names remain text.[94] Although convenient, Excel automatically converts some gene names (SEPT1, DEC1, MARCH2) into dates or floating point numbers.
- Choice of tools and benchmarking: There are numerous efforts that compare the results of these tools, with DESeq2 tending to moderately outperform other methods.[95][96][97][98][99][93][100] As with other methods, benchmarking consists of comparing tool outputs to each other and known gold standards.
Downstream analyses for a list of differentially expressed genes come in two flavors, validating observations and making biological inferences. Owing to the pitfalls of differential expression and RNA-Seq, important observations are replicated with (1) an orthogonal method in the same samples (like real-time PCR) or (2) another, sometimes pre-registered, experiment in a new cohort. The latter helps ensure generalizability and can typically be followed up with a meta-analysis of all the pooled cohorts. The most common method for obtaining higher-level biological understanding of the results is gene set enrichment analysis, although sometimes candidate gene approaches are employed. Gene set enrichment determines if the overlap between two gene sets is statistically significant, in this case the overlap between differentially expressed genes and gene sets from known pathways/databases (e.g., Gene Ontology, KEGG, Human Phenotype Ontology) or from complementary analyses in the same data (like co-expression networks). Common tools for gene set enrichment include web interfaces (e.g., ENRICHR, g:profiler) and software packages. When evaluating enrichment results, one heuristic is to first look for enrichment of known biology as a sanity check and then expand the scope to look for novel biology.
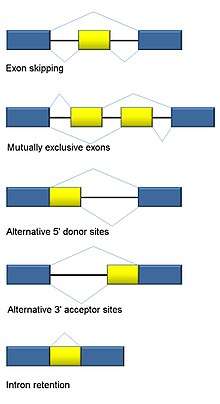
Alternative splicing
RNA splicing is integral to eukaryotes and contributes significantly to protein regulation and diversity, occurring in >90% of human genes.[101] There are multiple alternative splicing modes: exon skipping (most common splicing mode in humans and higher eukaryotes), mutually exclusive exons, alternative donor or acceptor sites, intron retention (most common splicing mode in plants, fungi, and protozoa), alternative transcription start site (promoter), and alternative polyadenylation.[101] One goal of RNA-Seq is to identify alternative splicing events and test if they differ between conditions. Long-read sequencing captures the full transcript and thus minimizes many of issues in estimating isoform abundance, like ambiguous read mapping. For short-read RNA-Seq, there are multiple methods to detect alternative splicing that can be classified into three main groups:[102][103][104]
- Count-based (also event-based, differential splicing): estimate exon retention. Examples are DEXSeq,[105] MATS,[106] and SeqGSEA.[107]
- Isoform-based (also multi-read modules, differential isoform expression): estimate isoform abundance first, and then relative abundance between conditions. Examples are Cufflinks 2[108] and DiffSplice.[109]
- Intron excision based: calculate alternative splicing using split reads. Examples are MAJIQ[110] and Leafcutter.[104]
Differential gene expression tools can also be used for differential isoform expression if isoforms are quantified ahead of time with other tools like RSEM.[111]
Coexpression networks
Coexpression networks are data-derived representations of genes behaving in a similar way across tissues and experimental conditions.[112] Their main purpose lies in hypothesis generation and guilt-by-association approaches for inferring functions of previously unknown genes.[112] RNA-Seq data has been used to infer genes involved in specific pathways based on Pearson correlation, both in plants[113] and mammals.[114] The main advantage of RNA-Seq data in this kind of analysis over the microarray platforms is the capability to cover the entire transcriptome, therefore allowing the possibility to unravel more complete representations of the gene regulatory networks. Differential regulation of the splice isoforms of the same gene can be detected and used to predict and their biological functions.[115][116] Weighted gene co-expression network analysis has been successfully used to identify co-expression modules and intramodular hub genes based on RNA seq data. Co-expression modules may correspond to cell types or pathways. Highly connected intramodular hubs can be interpreted as representatives of their respective module. An eigengene is a weighted sum of expression of all genes in a module. Eigengenes are useful biomarkers (features) for diagnosis and prognosis.[117] Variance-Stabilizing Transformation approaches for estimating correlation coefficients based on RNA seq data have been proposed.[113]
Variant discovery
RNA-Seq captures DNA variation, including single nucleotide variants, small insertions/deletions. and structural variation. Variant calling in RNA-Seq is similar to DNA variant calling and often employs the same tools (including SAMtools mpileup[118] and GATK HaplotypeCaller[119]) with adjustments to account for splicing. One unique dimension for RNA variants is allele-specific expression (ASE): the variants from only one haplotype might be preferentially expressed due to regulatory effects including imprinting and expression quantitative trait loci, and noncoding rare variants.[120][121] Limitations of RNA variant identification include that it only reflects expressed regions (in humans, <5% of the genome) and has lower quality when compared to direct DNA sequencing.
RNA editing (post-transcriptional alterations)
Having the matching genomic and transcriptomic sequences of an individual can help detect post-transcriptional edits (RNA editing).[3] A post-transcriptional modification event is identified if the gene's transcript has an allele/variant not observed in the genomic data.
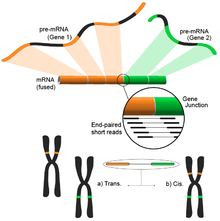
Fusion gene detection
Caused by different structural modifications in the genome, fusion genes have gained attention because of their relationship with cancer.[122] The ability of RNA-Seq to analyze a sample's whole transcriptome in an unbiased fashion makes it an attractive tool to find these kinds of common events in cancer.[4]
The idea follows from the process of aligning the short transcriptomic reads to a reference genome. Most of the short reads will fall within one complete exon, and a smaller but still large set would be expected to map to known exon-exon junctions. The remaining unmapped short reads would then be further analyzed to determine whether they match an exon-exon junction where the exons come from different genes. This would be evidence of a possible fusion event, however, because of the length of the reads, this could prove to be very noisy. An alternative approach is to use pair-end reads, when a potentially large number of paired reads would map each end to a different exon, giving better coverage of these events (see figure). Nonetheless, the end result consists of multiple and potentially novel combinations of genes providing an ideal starting point for further validation.
History
.png)
RNA-Seq was first developed in mid 2000s with the advent of next-generation sequencing technology.[123] The first manuscripts that used RNA-Seq even without using the term includes those of prostate cancer cell lines[124] (dated 2006), Medicago truncatula[125] (2006), maize[126] (2007), and Arabidopsis thaliana[127] (2007), while the term "RNA-Seq" itself was first mentioned in 2008.[128] The number of manuscripts referring to RNA-Seq in the title or abstract (Figure, blue line) is continuously increasing with 6754 manuscripts published in 2018 (link to PubMed search). The intersection of RNA-Seq and medicine (Figure, gold line, link to PubMed search) has similar celerity.
Applications to medicine
RNA-Seq has the potential to identify new disease biology, profile biomarkers for clinical indications, infer druggable pathways, and make genetic diagnoses. These results could be further personalized for subgroups or even individual patients, potentially highlighting more effective prevention, diagnostics, and therapy. The feasibility of this approach is in part dictated by costs in money and time; a related limitation is the required team of specialists (bioinformaticians, physicians/clinicians, basic researchers, technicians) to fully interpret the huge amount of data generated by this analysis.
Large-scale sequencing efforts
A lot of emphasis has been given to RNA-Seq data after the Encyclopedia of DNA Elements (ENCODE) and The Cancer Genome Atlas (TCGA) projects have used this approach to characterize dozens of cell lines[129] and thousands of primary tumor samples,[130] respectively. ENCODE aimed to identify genome-wide regulatory regions in different cohort of cell lines and transcriptomic data are paramount in order to understand the downstream effect of those epigenetic and genetic regulatory layers. TCGA, instead, aimed to collect and analyze thousands of patient's samples from 30 different tumor types in order to understand the underlying mechanisms of malignant transformation and progression. In this context RNA-Seq data provide a unique snapshot of the transcriptomic status of the disease and look at an unbiased population of transcripts that allows the identification of novel transcripts, fusion transcripts and non-coding RNAs that could be undetected with different technologies.
References
- Shafee T, Lowe R (2017). "Eukaryotic and prokaryotic gene structure". WikiJournal of Medicine. 4 (1). doi:10.15347/wjm/2017.002.
- Chu Y, Corey DR (August 2012). "RNA sequencing: platform selection, experimental design, and data interpretation". Nucleic Acid Therapeutics. 22 (4): 271–4. doi:10.1089/nat.2012.0367. PMC 3426205. PMID 22830413.
- Wang Z, Gerstein M, Snyder M (January 2009). "RNA-Seq: a revolutionary tool for transcriptomics". Nature Reviews. Genetics. 10 (1): 57–63. doi:10.1038/nrg2484. PMC 2949280. PMID 19015660.
- Maher CA, Kumar-Sinha C, Cao X, Kalyana-Sundaram S, Han B, Jing X, et al. (March 2009). "Transcriptome sequencing to detect gene fusions in cancer". Nature. 458 (7234): 97–101. Bibcode:2009Natur.458...97M. doi:10.1038/nature07638. PMC 2725402. PMID 19136943.
- Ingolia NT, Brar GA, Rouskin S, McGeachy AM, Weissman JS (July 2012). "The ribosome profiling strategy for monitoring translation in vivo by deep sequencing of ribosome-protected mRNA fragments". Nature Protocols. 7 (8): 1534–50. doi:10.1038/nprot.2012.086. PMC 3535016. PMID 22836135.
- Lee JH, Daugharthy ER, Scheiman J, Kalhor R, Yang JL, Ferrante TC, et al. (March 2014). "Highly multiplexed subcellular RNA sequencing in situ". Science. 343 (6177): 1360–3. Bibcode:2014Sci...343.1360L. doi:10.1126/science.1250212. PMC 4140943. PMID 24578530.
- Kukurba KR, Montgomery SB (April 2015). "RNA Sequencing and Analysis". Cold Spring Harbor Protocols. 2015 (11): 951–69. doi:10.1101/pdb.top084970. PMC 4863231. PMID 25870306.
- Griffith M, Walker JR, Spies NC, Ainscough BJ, Griffith OL (August 2015). "Informatics for RNA Sequencing: A Web Resource for Analysis on the Cloud". PLOS Computational Biology. 11 (8): e1004393. Bibcode:2015PLSCB..11E4393G. doi:10.1371/journal.pcbi.1004393. PMC 4527835. PMID 26248053.
- "RNA-seqlopedia". rnaseq.uoregon.edu. Retrieved 2017-02-08.
- Morin R, Bainbridge M, Fejes A, Hirst M, Krzywinski M, Pugh T, et al. (July 2008). "Profiling the HeLa S3 transcriptome using randomly primed cDNA and massively parallel short-read sequencing". BioTechniques. 45 (1): 81–94. doi:10.2144/000112900. PMID 18611170.
- Mortazavi A, Williams BA, McCue K, Schaeffer L, Wold B (July 2008). "Mapping and quantifying mammalian transcriptomes by RNA-Seq". Nature Methods. 5 (7): 621–8. doi:10.1038/nmeth.1226. PMID 18516045.
- Chen EA, Souaiaia T, Herstein JS, Evgrafov OV, Spitsyna VN, Rebolini DF, Knowles JA (October 2014). "Effect of RNA integrity on uniquely mapped reads in RNA-Seq". BMC Research Notes. 7 (1): 753. doi:10.1186/1756-0500-7-753. PMC 4213542. PMID 25339126.
- Liu D, Graber JH (February 2006). "Quantitative comparison of EST libraries requires compensation for systematic biases in cDNA generation". BMC Bioinformatics. 7: 77. doi:10.1186/1471-2105-7-77. PMC 1431573. PMID 16503995.
- Garalde DR, Snell EA, Jachimowicz D, Sipos B, Lloyd JH, Bruce M, et al. (March 2018). "Highly parallel direct RNA sequencing on an array of nanopores". Nature Methods. 15 (3): 201–206. doi:10.1038/nmeth.4577. PMID 29334379.
- "Shapiro E, Biezuner T, Linnarsson S (September 2013). "Single-cell sequencing-based technologies will revolutionize whole-organism science". Nature Reviews. Genetics. 14 (9): 618–30. doi:10.1038/nrg3542. PMID 23897237."
- Kolodziejczyk AA, Kim JK, Svensson V, Marioni JC, Teichmann SA (May 2015). "The technology and biology of single-cell RNA sequencing". Molecular Cell. 58 (4): 610–20. doi:10.1016/j.molcel.2015.04.005. PMID 26000846.
- Montoro DT, Haber AL, Biton M, Vinarsky V, Lin B, Birket SE, et al. (August 2018). "A revised airway epithelial hierarchy includes CFTR-expressing ionocytes". Nature. 560 (7718): 319–324. Bibcode:2018Natur.560..319M. doi:10.1038/s41586-018-0393-7. PMC 6295155. PMID 30069044.
- Plasschaert LW, Žilionis R, Choo-Wing R, Savova V, Knehr J, Roma G, et al. (August 2018). "A single-cell atlas of the airway epithelium reveals the CFTR-rich pulmonary ionocyte". Nature. 560 (7718): 377–381. Bibcode:2018Natur.560..377P. doi:10.1038/s41586-018-0394-6. PMC 6108322. PMID 30069046.
- Klein AM, Mazutis L, Akartuna I, Tallapragada N, Veres A, Li V, et al. (May 2015). "Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells". Cell. 161 (5): 1187–1201. doi:10.1016/j.cell.2015.04.044. PMC 4441768. PMID 26000487.
- Macosko EZ, Basu A, Satija R, Nemesh J, Shekhar K, Goldman M, et al. (May 2015). "Highly Parallel Genome-wide Expression Profiling of Individual Cells Using Nanoliter Droplets". Cell. 161 (5): 1202–1214. doi:10.1016/j.cell.2015.05.002. PMC 4481139. PMID 26000488.
- "Hebenstreit D (November 2012). "Methods, Challenges and Potentials of Single Cell RNA-seq". Biology. 1 (3): 658–67. doi:10.3390/biology1030658. PMC 4009822. PMID 24832513."
- Eberwine J, Sul JY, Bartfai T, Kim J (January 2014). "The promise of single-cell sequencing". Nature Methods. 11 (1): 25–7. doi:10.1038/nmeth.2769. PMID 24524134.
- Tang F, Barbacioru C, Wang Y, Nordman E, Lee C, Xu N, et al. (May 2009). "mRNA-Seq whole-transcriptome analysis of a single cell". Nature Methods. 6 (5): 377–82. doi:10.1038/NMETH.1315. PMID 19349980.
- Islam S, Kjällquist U, Moliner A, Zajac P, Fan JB, Lönnerberg P, Linnarsson S (July 2011). "Characterization of the single-cell transcriptional landscape by highly multiplex RNA-seq". Genome Research. 21 (7): 1160–7. doi:10.1101/gr.110882.110. PMC 3129258. PMID 21543516.
- Ramsköld D, Luo S, Wang YC, Li R, Deng Q, Faridani OR, et al. (August 2012). "Full-length mRNA-Seq from single-cell levels of RNA and individual circulating tumor cells". Nature Biotechnology. 30 (8): 777–82. doi:10.1038/nbt.2282. PMC 3467340. PMID 22820318.
- Hashimshony T, Wagner F, Sher N, Yanai I (September 2012). "CEL-Seq: single-cell RNA-Seq by multiplexed linear amplification". Cell Reports. 2 (3): 666–73. doi:10.1016/j.celrep.2012.08.003. PMID 22939981.
- Singh M, Al-Eryani G, Carswell S, Ferguson JM, Blackburn J, Barton K, Roden D, Luciani F, Phan T, Junankar S, Jackson K, Goodnow CC, Smith MA, Swarbrick A (2018). "High-throughput targeted long-read single cell sequencing reveals the clonal and transcriptional landscape of lymphocytes". bioRxiv. doi:10.1101/424945.
- Sasagawa Y, Nikaido I, Hayashi T, Danno H, Uno KD, Imai T, Ueda HR (April 2013). "Quartz-Seq: a highly reproducible and sensitive single-cell RNA sequencing method, reveals non-genetic gene-expression heterogeneity". Genome Biology. 14 (4): R31. doi:10.1186/gb-2013-14-4-r31. PMC 4054835. PMID 23594475.
- Kouno T, Moody J, Kwon AT, Shibayama Y, Kato S, Huang Y, et al. (January 2019). "C1 CAGE detects transcription start sites and enhancer activity at single-cell resolution". Nature Communications. 10 (1): 360. Bibcode:2019NatCo..10..360K. doi:10.1038/s41467-018-08126-5. PMC 6341120. PMID 30664627.
- Dal Molin A, Di Camillo B (2019). "How to design a single-cell RNA-sequencing experiment: pitfalls, challenges and perspectives". Briefings in Bioinformatics. 20 (4): 1384–1394. doi:10.1093/bib/bby007. PMID 29394315.
- Peterson VM, Zhang KX, Kumar N, Wong J, Li L, Wilson DC, et al. (October 2017). "Multiplexed quantification of proteins and transcripts in single cells". Nature Biotechnology. 35 (10): 936–939. doi:10.1038/nbt.3973. PMID 28854175.
- Stoeckius M, Hafemeister C, Stephenson W, Houck-Loomis B, Chattopadhyay PK, Swerdlow H, et al. (September 2017). "Simultaneous epitope and transcriptome measurement in single cells". Nature Methods. 14 (9): 865–868. doi:10.1038/nmeth.4380. PMC 5669064. PMID 28759029.
- Raj B, Wagner DE, McKenna A, Pandey S, Klein AM, Shendure J, et al. (June 2018). "Simultaneous single-cell profiling of lineages and cell types in the vertebrate brain". Nature Biotechnology. 36 (5): 442–450. doi:10.1038/nbt.4103. PMC 5938111. PMID 29608178.
- Olmos D, Arkenau HT, Ang JE, Ledaki I, Attard G, Carden CP, et al. (January 2009). "Circulating tumour cell (CTC) counts as intermediate end points in castration-resistant prostate cancer (CRPC): a single-centre experience". Annals of Oncology. 20 (1): 27–33. doi:10.1093/annonc/mdn544. PMID 18695026.
- Levitin HM, Yuan J, Sims PA (April 2018). "Single-Cell Transcriptomic Analysis of Tumor Heterogeneity". Trends in Cancer. 4 (4): 264–268. doi:10.1016/j.trecan.2018.02.003. PMC 5993208. PMID 29606308.
- Jerby-Arnon L, Shah P, Cuoco MS, Rodman C, Su MJ, Melms JC, et al. (November 2018). "A Cancer Cell Program Promotes T Cell Exclusion and Resistance to Checkpoint Blockade". Cell. 175 (4): 984–997.e24. doi:10.1016/j.cell.2018.09.006. PMC 6410377. PMID 30388455.
- Stephenson W, Donlin LT, Butler A, Rozo C, Bracken B, Rashidfarrokhi A, et al. (February 2018). "Single-cell RNA-seq of rheumatoid arthritis synovial tissue using low-cost microfluidic instrumentation". Nature Communications. 9 (1): 791. Bibcode:2018NatCo...9..791S. doi:10.1038/s41467-017-02659-x. PMC 5824814. PMID 29476078.
- Avraham R, Haseley N, Brown D, Penaranda C, Jijon HB, Trombetta JJ, et al. (September 2015). "Pathogen Cell-to-Cell Variability Drives Heterogeneity in Host Immune Responses". Cell. 162 (6): 1309–21. doi:10.1016/j.cell.2015.08.027. PMC 4578813. PMID 26343579.
- Cao J, Packer JS, Ramani V, Cusanovich DA, Huynh C, Daza R, et al. (August 2017). "Comprehensive single-cell transcriptional profiling of a multicellular organism". Science. 357 (6352): 661–667. Bibcode:2017Sci...357..661C. doi:10.1126/science.aam8940. PMC 5894354. PMID 28818938.
- Plass M, Solana J, Wolf FA, Ayoub S, Misios A, Glažar P, et al. (May 2018). "Cell type atlas and lineage tree of a whole complex animal by single-cell transcriptomics". Science. 360 (6391): eaaq1723. doi:10.1126/science.aaq1723. PMID 29674432.
- Fincher CT, Wurtzel O, de Hoog T, Kravarik KM, Reddien PW (May 2018). "Schmidtea mediterranea". Science. 360 (6391): eaaq1736. doi:10.1126/science.aaq1736. PMC 6563842. PMID 29674431.
- Wagner DE, Weinreb C, Collins ZM, Briggs JA, Megason SG, Klein AM (June 2018). "Single-cell mapping of gene expression landscapes and lineage in the zebrafish embryo". Science. 360 (6392): 981–987. Bibcode:2018Sci...360..981W. doi:10.1126/science.aar4362. PMC 6083445. PMID 29700229.
- Farrell JA, Wang Y, Riesenfeld SJ, Shekhar K, Regev A, Schier AF (June 2018). "Single-cell reconstruction of developmental trajectories during zebrafish embryogenesis". Science. 360 (6392): eaar3131. doi:10.1126/science.aar3131. PMC 6247916. PMID 29700225.
- Briggs JA, Weinreb C, Wagner DE, Megason S, Peshkin L, Kirschner MW, Klein AM (June 2018). "The dynamics of gene expression in vertebrate embryogenesis at single-cell resolution". Science. 360 (6392): eaar5780. doi:10.1126/science.aar5780. PMC 6038144. PMID 29700227.
- You J. "Science's 2018 Breakthrough of the Year: tracking development cell by cell". Science Magazine. American Association for the Advancement of Science.
- Li H, Lovci MT, Kwon YS, Rosenfeld MG, Fu XD, Yeo GW (December 2008). "Determination of tag density required for digital transcriptome analysis: application to an androgen-sensitive prostate cancer model". Proceedings of the National Academy of Sciences of the United States of America. 105 (51): 20179–84. Bibcode:2008PNAS..10520179L. doi:10.1073/pnas.0807121105. PMC 2603435. PMID 19088194.
- Stegle O, Parts L, Piipari M, Winn J, Durbin R (February 2012). "Using probabilistic estimation of expression residuals (PEER) to obtain increased power and interpretability of gene expression analyses". Nature Protocols. 7 (3): 500–7. doi:10.1038/nprot.2011.457. PMC 3398141. PMID 22343431.
- Kingsford C, Patro R (June 2015). "Reference-based compression of short-read sequences using path encoding". Bioinformatics. 31 (12): 1920–8. doi:10.1093/bioinformatics/btv071. PMC 4481695. PMID 25649622.
- Grabherr MG, Haas BJ, Yassour M, Levin JZ, Thompson DA, Amit I, et al. (May 2011). "Full-length transcriptome assembly from RNA-Seq data without a reference genome". Nature Biotechnology. 29 (7): 644–52. doi:10.1038/nbt.1883. PMC 3571712. PMID 21572440.
- "De Novo Assembly Using Illumina Reads" (PDF). Retrieved 22 October 2016.
- Zerbino DR, Birney E (May 2008). "Velvet: algorithms for de novo short read assembly using de Bruijn graphs". Genome Research. 18 (5): 821–9. doi:10.1101/gr.074492.107. PMC 2336801. PMID 18349386.
- Oases: a transcriptome assembler for very short reads
- Chang Z, Li G, Liu J, Zhang Y, Ashby C, Liu D, et al. (February 2015). "Bridger: a new framework for de novo transcriptome assembly using RNA-seq data". Genome Biology. 16 (1): 30. doi:10.1186/s13059-015-0596-2. PMC 4342890. PMID 25723335.
- Li B, Fillmore N, Bai Y, Collins M, Thomson JA, Stewart R, Dewey CN (December 2014). "Evaluation of de novo transcriptome assemblies from RNA-Seq data". Genome Biology. 15 (12): 553. doi:10.1186/s13059-014-0553-5. PMC 4298084. PMID 25608678.
- Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S, et al. (January 2013). "STAR: ultrafast universal RNA-seq aligner". Bioinformatics. 29 (1): 15–21. doi:10.1093/bioinformatics/bts635. PMC 3530905. PMID 23104886.
- Langmead B, Trapnell C, Pop M, Salzberg SL (2009). "Ultrafast and memory-efficient alignment of short DNA sequences to the human genome". Genome Biology. 10 (3): R25. doi:10.1186/gb-2009-10-3-r25. PMC 2690996. PMID 19261174.
- Trapnell C, Pachter L, Salzberg SL (May 2009). "TopHat: discovering splice junctions with RNA-Seq". Bioinformatics. 25 (9): 1105–11. doi:10.1093/bioinformatics/btp120. PMC 2672628. PMID 19289445.
- Trapnell C, Roberts A, Goff L, Pertea G, Kim D, Kelley DR, et al. (March 2012). "Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks". Nature Protocols. 7 (3): 562–78. doi:10.1038/nprot.2012.016. PMC 3334321. PMID 22383036.
- Liao Y, Smyth GK, Shi W (May 2013). "The Subread aligner: fast, accurate and scalable read mapping by seed-and-vote". Nucleic Acids Research. 41 (10): e108. doi:10.1093/nar/gkt214. PMC 3664803. PMID 23558742.
- Kim D, Langmead B, Salzberg SL (April 2015). "HISAT: a fast spliced aligner with low memory requirements". Nature Methods. 12 (4): 357–60. doi:10.1038/nmeth.3317. PMC 4655817. PMID 25751142.
- Patro R, Mount SM, Kingsford C (May 2014). "Sailfish enables alignment-free isoform quantification from RNA-seq reads using lightweight algorithms". Nature Biotechnology. 32 (5): 462–4. arXiv:1308.3700. doi:10.1038/nbt.2862. PMC 4077321. PMID 24752080.
- Bray NL, Pimentel H, Melsted P, Pachter L (May 2016). "Near-optimal probabilistic RNA-seq quantification". Nature Biotechnology. 34 (5): 525–7. doi:10.1038/nbt.3519. PMID 27043002.
- Wu TD, Watanabe CK (May 2005). "GMAP: a genomic mapping and alignment program for mRNA and EST sequences". Bioinformatics. 21 (9): 1859–75. doi:10.1093/bioinformatics/bti310. PMID 15728110.
- Baruzzo G, Hayer KE, Kim EJ, Di Camillo B, FitzGerald GA, Grant GR (February 2017). "Simulation-based comprehensive benchmarking of RNA-seq aligners". Nature Methods. 14 (2): 135–139. doi:10.1038/nmeth.4106. PMC 5792058. PMID 27941783.
- Engström PG, Steijger T, Sipos B, Grant GR, Kahles A, Rätsch G, et al. (December 2013). "Systematic evaluation of spliced alignment programs for RNA-seq data". Nature Methods. 10 (12): 1185–91. doi:10.1038/nmeth.2722. PMC 4018468. PMID 24185836.
- Lu B, Zeng Z, Shi T (February 2013). "Comparative study of de novo assembly and genome-guided assembly strategies for transcriptome reconstruction based on RNA-Seq". Science China Life Sciences. 56 (2): 143–55. doi:10.1007/s11427-013-4442-z. PMID 23393030.
- Bradnam KR, Fass JN, Alexandrov A, Baranay P, Bechner M, Birol I, et al. (July 2013). "Assemblathon 2: evaluating de novo methods of genome assembly in three vertebrate species". GigaScience. 2 (1): 10. arXiv:1301.5406. Bibcode:2013arXiv1301.5406B. doi:10.1186/2047-217X-2-10. PMC 3844414. PMID 23870653.
- Greenbaum D, Colangelo C, Williams K, Gerstein M (2003). "Comparing protein abundance and mRNA expression levels on a genomic scale". Genome Biology. 4 (9): 117. doi:10.1186/gb-2003-4-9-117. PMC 193646. PMID 12952525.
- Zhang ZH, Jhaveri DJ, Marshall VM, Bauer DC, Edson J, Narayanan RK, et al. (August 2014). "A comparative study of techniques for differential expression analysis on RNA-Seq data". PLOS ONE. 9 (8): e103207. Bibcode:2014PLoSO...9j3207Z. doi:10.1371/journal.pone.0103207. PMC 4132098. PMID 25119138.
- Anders S, Pyl PT, Huber W (January 2015). "HTSeq--a Python framework to work with high-throughput sequencing data". Bioinformatics. 31 (2): 166–9. doi:10.1093/bioinformatics/btu638. PMC 4287950. PMID 25260700.
- Liao Y, Smyth GK, Shi W (April 2014). "featureCounts: an efficient general purpose program for assigning sequence reads to genomic features". Bioinformatics. 30 (7): 923–30. arXiv:1305.3347. doi:10.1093/bioinformatics/btt656. PMID 24227677.
- Schmid MW, Grossniklaus U (February 2015). "Rcount: simple and flexible RNA-Seq read counting". Bioinformatics. 31 (3): 436–7. doi:10.1093/bioinformatics/btu680. PMID 25322836.
- Finotello F, Lavezzo E, Bianco L, Barzon L, Mazzon P, Fontana P, et al. (2014). "Reducing bias in RNA sequencing data: a novel approach to compute counts". BMC Bioinformatics. 15 Suppl 1 (Suppl 1): S7. doi:10.1186/1471-2105-15-s1-s7. PMC 4016203. PMID 24564404.
- Hashimoto TB, Edwards MD, Gifford DK (March 2014). "Universal count correction for high-throughput sequencing". PLOS Computational Biology. 10 (3): e1003494. Bibcode:2014PLSCB..10E3494H. doi:10.1371/journal.pcbi.1003494. PMC 3945112. PMID 24603409.
- Robinson MD, Oshlack A (2010). "A scaling normalization method for differential expression analysis of RNA-seq data". Genome Biology. 11 (3): R25. doi:10.1186/gb-2010-11-3-r25. PMC 2864565. PMID 20196867.
- Trapnell C, Williams BA, Pertea G, Mortazavi A, Kwan G, van Baren MJ, et al. (May 2010). "Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation". Nature Biotechnology. 28 (5): 511–5. doi:10.1038/nbt.1621. PMC 3146043. PMID 20436464.
- Pachter L (19 April 2011). "Models for transcript quantification from RNA-Seq". arXiv:1104.3889 [q-bio.GN].
- "What the FPKM? A review of RNA-Seq expression units". The farrago. 8 May 2014. Retrieved 28 March 2018.
- Wagner GP, Kin K, Lynch VJ (December 2012). "Measurement of mRNA abundance using RNA-seq data: RPKM measure is inconsistent among samples". Theory in Biosciences = Theorie in den Biowissenschaften. 131 (4): 281–5. doi:10.1007/s12064-012-0162-3. PMID 22872506.
- Evans, Ciaran; Hardin, Johanna; Stoebel, Daniel M (28 September 2018). "Selecting between-sample RNA-Seq normalization methods from the perspective of their assumptions". Briefings in Bioinformatics. 19 (5): 776–792. doi:10.1093/bib/bbx008.
- Law CW, Chen Y, Shi W, Smyth GK (February 2014). "voom: Precision weights unlock linear model analysis tools for RNA-seq read counts". Genome Biology. 15 (2): R29. doi:10.1186/gb-2014-15-2-r29. PMC 4053721. PMID 24485249.
- Anders S, Huber W (2010). "Differential expression analysis for sequence count data". Genome Biology. 11 (10): R106. doi:10.1186/gb-2010-11-10-r106. PMC 3218662. PMID 20979621.
- Robinson MD, McCarthy DJ, Smyth GK (January 2010). "edgeR: a Bioconductor package for differential expression analysis of digital gene expression data". Bioinformatics. 26 (1): 139–40. doi:10.1093/bioinformatics/btp616. PMC 2796818. PMID 19910308.
- Marguerat S, Schmidt A, Codlin S, Chen W, Aebersold R, Bähler J (October 2012). "Quantitative analysis of fission yeast transcriptomes and proteomes in proliferating and quiescent cells". Cell. 151 (3): 671–83. doi:10.1016/j.cell.2012.09.019. PMC 3482660. PMID 23101633.
- Owens ND, Blitz IL, Lane MA, Patrushev I, Overton JD, Gilchrist MJ, et al. (January 2016). "Measuring Absolute RNA Copy Numbers at High Temporal Resolution Reveals Transcriptome Kinetics in Development". Cell Reports. 14 (3): 632–647. doi:10.1016/j.celrep.2015.12.050. PMC 4731879. PMID 26774488.
- Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W, Smyth GK (April 2015). "limma powers differential expression analyses for RNA-sequencing and microarray studies". Nucleic Acids Research. 43 (7): e47. doi:10.1093/nar/gkv007. PMC 4402510. PMID 25605792.
- "Bioconductor - Open source software for bioinformatics".
- Huber W, Carey VJ, Gentleman R, Anders S, Carlson M, Carvalho BS, et al. (February 2015). "Orchestrating high-throughput genomic analysis with Bioconductor". Nature Methods. 12 (2): 115–21. doi:10.1038/nmeth.3252. PMC 4509590. PMID 25633503.
- Leek JT, Storey JD (September 2007). "Capturing heterogeneity in gene expression studies by surrogate variable analysis". PLOS Genetics. 3 (9): 1724–35. doi:10.1371/journal.pgen.0030161. PMC 1994707. PMID 17907809.
- Pimentel H, Bray NL, Puente S, Melsted P, Pachter L (July 2017). "Differential analysis of RNA-seq incorporating quantification uncertainty". Nature Methods. 14 (7): 687–690. doi:10.1038/nmeth.4324. PMID 28581496.
- Trapnell C, Hendrickson DG, Sauvageau M, Goff L, Rinn JL, Pachter L (January 2013). "Differential analysis of gene regulation at transcript resolution with RNA-seq" (PDF). Nature Biotechnology. 31 (1): 46–53. doi:10.1038/nbt.2450. PMC 3869392. PMID 23222703.
- Frazee AC, Pertea G, Jaffe AE, Langmead B, Salzberg SL, Leek JT (March 2015). "Ballgown bridges the gap between transcriptome assembly and expression analysis". Nature Biotechnology. 33 (3): 243–6. doi:10.1038/nbt.3172. PMC 4792117. PMID 25748911.
- Sahraeian SM, Mohiyuddin M, Sebra R, Tilgner H, Afshar PT, Au KF, et al. (July 2017). "Gaining comprehensive biological insight into the transcriptome by performing a broad-spectrum RNA-seq analysis". Nature Communications. 8 (1): 59. Bibcode:2017NatCo...8...59S. doi:10.1038/s41467-017-00050-4. PMC 5498581. PMID 28680106.
- Ziemann M, Eren Y, El-Osta A (August 2016). "Gene name errors are widespread in the scientific literature". Genome Biology. 17 (1): 177. doi:10.1186/s13059-016-1044-7. PMC 4994289. PMID 27552985.
- Soneson C, Delorenzi M (March 2013). "A comparison of methods for differential expression analysis of RNA-seq data". BMC Bioinformatics. 14: 91. doi:10.1186/1471-2105-14-91. PMC 3608160. PMID 23497356.
- Fonseca NA, Marioni J, Brazma A (30 September 2014). "RNA-Seq gene profiling--a systematic empirical comparison". PLOS ONE. 9 (9): e107026. Bibcode:2014PLoSO...9j7026F. doi:10.1371/journal.pone.0107026. PMC 4182317. PMID 25268973.
- Seyednasrollah F, Laiho A, Elo LL (January 2015). "Comparison of software packages for detecting differential expression in RNA-seq studies". Briefings in Bioinformatics. 16 (1): 59–70. doi:10.1093/bib/bbt086. PMC 4293378. PMID 24300110.
- Rapaport F, Khanin R, Liang Y, Pirun M, Krek A, Zumbo P, et al. (2013). "Comprehensive evaluation of differential gene expression analysis methods for RNA-seq data". Genome Biology. 14 (9): R95. doi:10.1186/gb-2013-14-9-r95. PMC 4054597. PMID 24020486.
- Conesa A, Madrigal P, Tarazona S, Gomez-Cabrero D, Cervera A, McPherson A, et al. (January 2016). "A survey of best practices for RNA-seq data analysis". Genome Biology. 17 (1): 13. doi:10.1186/s13059-016-0881-8. PMC 4728800. PMID 26813401.
- Costa-Silva J, Domingues D, Lopes FM (21 December 2017). "RNA-Seq differential expression analysis: An extended review and a software tool". PLOS ONE. 12 (12): e0190152. Bibcode:2017PLoSO..1290152C. doi:10.1371/journal.pone.0190152. PMC 5739479. PMID 29267363.
- Keren H, Lev-Maor G, Ast G (May 2010). "Alternative splicing and evolution: diversification, exon definition and function". Nature Reviews. Genetics. 11 (5): 345–55. doi:10.1038/nrg2776. PMID 20376054.
- Liu R, Loraine AE, Dickerson JA (December 2014). "Comparisons of computational methods for differential alternative splicing detection using RNA-seq in plant systems". BMC Bioinformatics. 15 (1): 364. doi:10.1186/s12859-014-0364-4. PMC 4271460. PMID 25511303.
- Pachter, Lior (19 April 2011). "Models for transcript quantification from RNA-Seq". arXiv:1104.3889 [q-bio.GN].
- Li YI, Knowles DA, Humphrey J, Barbeira AN, Dickinson SP, Im HK, Pritchard JK (January 2018). "Annotation-free quantification of RNA splicing using LeafCutter". Nature Genetics. 50 (1): 151–158. doi:10.1038/s41588-017-0004-9. PMC 5742080. PMID 29229983.
- Anders S, Reyes A, Huber W (October 2012). "Detecting differential usage of exons from RNA-seq data". Genome Research. 22 (10): 2008–17. doi:10.1101/gr.133744.111. PMC 3460195. PMID 22722343.
- Shen S, Park JW, Huang J, Dittmar KA, Lu ZX, Zhou Q, et al. (April 2012). "MATS: a Bayesian framework for flexible detection of differential alternative splicing from RNA-Seq data". Nucleic Acids Research. 40 (8): e61. doi:10.1093/nar/gkr1291. PMC 3333886. PMID 22266656.
- Wang X, Cairns MJ (June 2014). "SeqGSEA: a Bioconductor package for gene set enrichment analysis of RNA-Seq data integrating differential expression and splicing". Bioinformatics. 30 (12): 1777–9. doi:10.1093/bioinformatics/btu090. PMID 24535097.
- Trapnell C, Hendrickson DG, Sauvageau M, Goff L, Rinn JL, Pachter L (January 2013). "Differential analysis of gene regulation at transcript resolution with RNA-seq". Nature Biotechnology. 31 (1): 46–53. doi:10.1038/nbt.2450. PMC 3869392. PMID 23222703.
- Hu Y, Huang Y, Du Y, Orellana CF, Singh D, Johnson AR, et al. (January 2013). "DiffSplice: the genome-wide detection of differential splicing events with RNA-seq". Nucleic Acids Research. 41 (2): e39. doi:10.1093/nar/gks1026. PMC 3553996. PMID 23155066.
- Vaquero-Garcia J, Barrera A, Gazzara MR, González-Vallinas J, Lahens NF, Hogenesch JB, et al. (February 2016). "A new view of transcriptome complexity and regulation through the lens of local splicing variations". eLife. 5: e11752. doi:10.7554/eLife.11752. PMC 4801060. PMID 26829591.
- Merino GA, Conesa A, Fernández EA (March 2019). "A benchmarking of workflows for detecting differential splicing and differential expression at isoform level in human RNA-seq studies". Briefings in Bioinformatics. 20 (2): 471–481. doi:10.1093/bib/bbx122. PMID 29040385.
- Marcotte EM, Pellegrini M, Thompson MJ, Yeates TO, Eisenberg D (November 1999). "A combined algorithm for genome-wide prediction of protein function". Nature. 402 (6757): 83–6. Bibcode:1999Natur.402...83M. doi:10.1038/47048. PMID 10573421.
- Giorgi FM, Del Fabbro C, Licausi F (March 2013). "Comparative study of RNA-seq- and microarray-derived coexpression networks in Arabidopsis thaliana". Bioinformatics. 29 (6): 717–24. doi:10.1093/bioinformatics/btt053. PMID 23376351.
- Iancu OD, Kawane S, Bottomly D, Searles R, Hitzemann R, McWeeney S (June 2012). "Utilizing RNA-Seq data for de novo coexpression network inference". Bioinformatics. 28 (12): 1592–7. doi:10.1093/bioinformatics/bts245. PMC 3493127. PMID 22556371.
- Eksi R, Li HD, Menon R, Wen Y, Omenn GS, Kretzler M, Guan Y (Nov 2013). "Systematically differentiating functions for alternatively spliced isoforms through integrating RNA-seq data". PLOS Computational Biology. 9 (11): e1003314. Bibcode:2013PLSCB...9E3314E. doi:10.1371/journal.pcbi.1003314. PMC 3820534. PMID 24244129.
- Li HD, Menon R, Omenn GS, Guan Y (August 2014). "The emerging era of genomic data integration for analyzing splice isoform function". Trends in Genetics. 30 (8): 340–7. doi:10.1016/j.tig.2014.05.005. PMC 4112133. PMID 24951248.
- Foroushani A, Agrahari R, Docking R, Chang L, Duns G, Hudoba M, et al. (March 2017). "Large-scale gene network analysis reveals the significance of extracellular matrix pathway and homeobox genes in acute myeloid leukemia: an introduction to the Pigengene package and its applications". BMC Medical Genomics. 10 (1): 16. doi:10.1186/s12920-017-0253-6. PMC 5353782. PMID 28298217.
- Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, et al. (August 2009). "The Sequence Alignment/Map format and SAMtools". Bioinformatics. 25 (16): 2078–9. doi:10.1093/bioinformatics/btp352. PMC 2723002. PMID 19505943.
- DePristo MA, Banks E, Poplin R, Garimella KV, Maguire JR, Hartl C, et al. (May 2011). "A framework for variation discovery and genotyping using next-generation DNA sequencing data". Nature Genetics. 43 (5): 491–8. doi:10.1038/ng.806. PMC 3083463. PMID 21478889.
- Battle A, Brown CD, Engelhardt BE, Montgomery SB (October 2017). "Genetic effects on gene expression across human tissues". Nature. 550 (7675): 204–213. Bibcode:2017Natur.550..204A. doi:10.1038/nature24277. PMC 5776756. PMID 29022597.
- Richter F, Hoffman GE, Manheimer KB, Patel N, Sharp AJ, McKean D, et al. (March 2019). "ORE Identifies Extreme Expression Effects Enriched for Rare Variants". Bioinformatics. 35 (20): 3906–3912. doi:10.1093/bioinformatics/btz202. PMC 6792115. PMID 30903145.
- Teixeira MR (December 2006). "Recurrent fusion oncogenes in carcinomas". Critical Reviews in Oncogenesis. 12 (3–4): 257–71. doi:10.1615/critrevoncog.v12.i3-4.40. PMID 17425505.
- Weber AP (November 2015). "Discovering New Biology through Sequencing of RNA". Plant Physiology. 169 (3): 1524–31. doi:10.1104/pp.15.01081. PMC 4634082. PMID 26353759.
- Bainbridge MN, Warren RL, Hirst M, Romanuik T, Zeng T, Go A, et al. (September 2006). "Analysis of the prostate cancer cell line LNCaP transcriptome using a sequencing-by-synthesis approach". BMC Genomics. 7: 246. doi:10.1186/1471-2164-7-246. PMC 1592491. PMID 17010196.
- Cheung F, Haas BJ, Goldberg SM, May GD, Xiao Y, Town CD (October 2006). "Sequencing Medicago truncatula expressed sequenced tags using 454 Life Sciences technology". BMC Genomics. 7: 272. doi:10.1186/1471-2164-7-272. PMC 1635983. PMID 17062153.
- Emrich SJ, Barbazuk WB, Li L, Schnable PS (January 2007). "Gene discovery and annotation using LCM-454 transcriptome sequencing". Genome Research. 17 (1): 69–73. doi:10.1101/gr.5145806. PMC 1716268. PMID 17095711.
- Weber AP, Weber KL, Carr K, Wilkerson C, Ohlrogge JB (May 2007). "Sampling the Arabidopsis transcriptome with massively parallel pyrosequencing". Plant Physiology. 144 (1): 32–42. doi:10.1104/pp.107.096677. PMC 1913805. PMID 17351049.
- Nagalakshmi U, Wang Z, Waern K, Shou C, Raha D, Gerstein M, Snyder M (June 2008). "The transcriptional landscape of the yeast genome defined by RNA sequencing". Science. 320 (5881): 1344–9. Bibcode:2008Sci...320.1344N. doi:10.1126/science.1158441. PMC 2951732. PMID 18451266.
- "ENCODE Data Matrix". Retrieved 2013-07-28.
- "The Cancer Genome Atlas - Data Portal". Retrieved 2013-07-28.
External links
- RNA-Seq for Everyone: a high-level guide to designing and implementing an RNA-Seq experiment.
- Taguchi, Y.-h. (2019). "Comparative Transcriptomics Analysis". Encyclopedia of Bioinformatics and Computational Biology. pp. 814–818. doi:10.1016/B978-0-12-809633-8.20163-5. ISBN 9780128114322.
- Reference Module in Life Sciences