Protein splicing
Protein splicing is an intramolecular reaction of a particular protein in which an internal protein segment (called an intein) is removed from a precursor protein with a ligation of C-terminal and N-terminal external proteins (called exteins) on both sides. The splicing junction of the precursor protein is mainly a cysteine or a serine, which are amino acids containing a nucleophilic side chain. The protein splicing reactions which are known now do not require exogenous cofactors or energy sources such as adenosine triphosphate (ATP) or guanosine triphosphate (GTP). Normally, splicing is associated only with pre-mRNA splicing. This precursor protein contains three segments—an N-extein followed by the intein followed by a C-extein. After splicing has taken place, the resulting protein contains the N-extein linked to the C-extein; this splicing product is also termed an extein.
History
The first intein was discovered in 1988 through sequence comparison between the Neurospora crassa[1] and carrot[2] vacuolar ATPase (without intein) and the homologous gene in yeast (with intein) that was first described as a putative calcium ion transporter.[3] In 1990 Hirata et al.[4] demonstrated that the extra sequence in the yeast gene was transcribed into mRNA and removed itself from the host protein only after translation. Since then, inteins have been found in all three domains of life (eukaryotes, bacteria, and archaea) and in viruses.
Protein splicing was unanticipated and its mechanisms were discovered by two groups (Anraku [5] and Stevens[6]) in 1990. They both discovered a Saccharomyces cerevisiae VMA1 in a precursor of a vacuolar H+-ATPase enzyme. The amino acid sequence of the N- and C-termini corresponded to 70% DNA sequence of that of a vacuolar H+-ATPase from other organisms, while the amino acid sequence of the central position corresponded to 30% of the total DNA sequence of the yeast HO nuclease.
Many genes have unrelated intein-coding segments inserted at different positions. For these and other reasons, inteins (or more properly, the gene segments coding for inteins) are sometimes called selfish genetic elements, but it may be more accurate to call them parasitic. According to the gene centered view of evolution, most genes are "selfish" only insofar as to compete with other genes or alleles but usually they fulfill a function for the organisms, whereas "parasitic genetic elements", at least initially, do not make a positive contribution to the fitness of the organism.[7] [8]
Within the database of all known inteins (), 113 known inteins are present in eukaryotes with minimum length of 138 amino acids and maximum length of 844 amino acids. The first intein was found encoded within the VMA gene of Saccharomyces cerevisiae. They were later found in fungi (ascomycetes, basidiomycetes, zygomycetes and chytrids) and in diverse proteins as well. A protein distantly related to known inteins containing protein, but closely related to metazoan hedgehog proteins, has been described to have the intein sequence from Glomeromycota. Many of the newly described inteins contain homing endonucleases and some of these are apparently active.[9] The abundance of intein in fungi indicates lateral transfer of intein-containing genes. While in eubacteria and archaea, there are 289 and 182 currently known inteins. Not surprisingly, most intein in eubacteria and archaea are found to be inserted into nucleic acid metabolic protein, like fungi.[9]
Mechanism
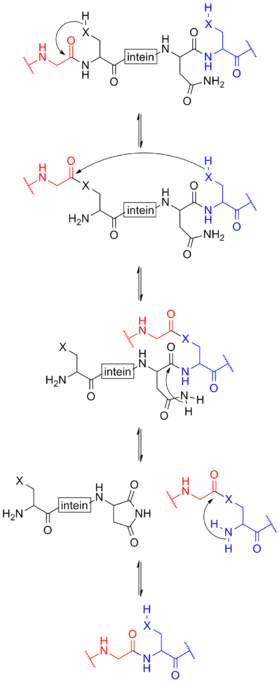
The process begins with an N-O or N-S shift when the side chain of the first residue (a serine, threonine, or cysteine) of the intein portion of the precursor protein nucleophilically attacks the peptide bond of the residue immediately upstream (that is, the final residue of the N-extein) to form a linear ester (or thioester) intermediate. A transesterification occurs when the side chain of the first residue of the C-extein attacks the newly formed (thio)ester to free the N-terminal end of the intein. This forms a branched intermediate in which the N-extein and C-extein are attached, albeit not through a peptide bond. The last residue of the intein is always an asparagine, and the amide nitrogen atom of this side chain cleaves apart the peptide bond between the intein and the C-extein, resulting in a free intein segment with a terminal cyclic imide. Finally, the free amino group of the C-extein now attacks the (thio)ester linking the N- and C-exteins together. An O-N or S-N shift produces a peptide bond and the functional, ligated protein.[10]
The mechanism for the splicing effect is a naturally occurring analogy to the technique for chemically generating medium-sized proteins called native chemical ligation.
Intein
An intein is a segment of a protein that is able to excise itself and join the remaining portions (the exteins) with a peptide bond during protein splicing.[11] Inteins have also been called protein introns, by analogy with (RNA) introns.
Naming conventions
The first part of an intein name is based on the scientific name of the organism in which it is found, and the second part is based on the name of the corresponding gene or extein. For example, the intein found in Thermoplasma acidophilum and associated with Vacuolar ATPase subunit A (VMA) is called "Tac VMA".
Normally, as in this example, just three letters suffice to specify the organism, but there are variations. For example, additional letters may be added to indicate a strain. If more than one intein is encoded in the corresponding gene, the inteins are given a numerical suffix starting from 5′ to 3′ or in order of their identification (for example, "Msm dnaB-1").
The segment of the gene that encodes the intein is usually given the same name as the intein, but to avoid confusion the name of the intein proper is usually capitalized (e.g., Pfu RIR1-1), whereas the name of the corresponding gene segment is italicized (e.g., Pfu rir1-1).
Types of inteins
The type of the splicing proteins is categorized into four classes: maxi-intein, mini-intein, trans-splicing intein, and alanine intein. Maxi-inteins are N- and C-terminal splicing domains containing an endonuclease domain. The mini-inteins are typical N- and C-terminal splicing domains; however, the endonuclease domain is not present. In trans-splicing inteins, the intein is split into two (or perhaps more) domains, which are then divided into N-termini and C-termini. Alanine inteins have the splicing junction of an alanine instead of a cysteine or a serine, in both of which the protein splicing occurs.
Full and mini inteins
Inteins can contain a homing endonuclease gene (HEG) domain in addition to the splicing domains. This domain is responsible for the spread of the intein by cleaving DNA at an intein-free allele on the homologous chromosome, triggering the DNA double-stranded break repair (DSBR) system, which then repairs the break, thus copying the intein-coding DNA into a previously intein-free site. The HEG domain is not necessary for intein splicing, and so it can be lost, forming a minimal, or mini, intein. Several studies have demonstrated the modular nature of inteins by adding or removing HEG domains and determining the activity of the new construct.
Split inteins
Sometimes, the intein of the precursor protein comes from two genes. In this case, the intein is said to be a split intein. For example, in cyanobacteria, DnaE, the catalytic subunit α of DNA polymerase III, is encoded by two separate genes, dnaE-n and dnaE-c. The dnaE-n product consists of an N-extein sequence followed by a 123-AA intein sequence, whereas the dnaE-c product consists of a 36-AA intein sequence followed by a C-extein sequence.[12]
Applications in biotechnology
Inteins are very efficient at protein splicing, and they have accordingly found an important role in biotechnology. There are more than 200 inteins identified to date; sizes range from 100–800 AAs. Inteins have been engineered for particular applications such as protein semisynthesis[13] and the selective labeling of protein segments, which is useful for NMR studies of large proteins.[14]
Pharmaceutical inhibition of intein excision may be a useful tool for drug development; the protein that contains the intein will not carry out its normal function if the intein does not excise, since its structure will be disrupted.
It has been suggested that inteins could prove useful for achieving allotopic expression of certain highly hydrophobic proteins normally encoded by the mitochondrial genome, for example in gene therapy.[15] The hydrophobicity of these proteins is an obstacle to their import into mitochondria. Therefore, the insertion of a non-hydrophobic intein may allow this import to proceed. Excision of the intein after import would then restore the protein to wild-type.
Affinity tags have been widely used to purify recombinant proteins, as they allow the accumulation of recombinant protein with little impurities. However, the affinity tag must be removed by proteases in the final purification step. The extra proteolysis step raises the problems of protease specificity in removing affinity tags from recombinant protein, and the removal of the digestion product. This problem can be avoided by fusing an affinity tag to self-cleavable inteins in a controlled environment. The first generation of expression vectors of this kind used modified Saccharomyces cerevisiae VMA (Sce VMA) intein. Chong et al.[16] used a chitin binding domain (CBD) from Bacillus circulans as an affinity tag, and fused this tag with a modified Sce VMA intein. The modified intein undergoes a self-cleavage reaction at its N-terminal peptide linkage with 1,4-dithiothreitol (DTT), β-mercaptoethanol (β-ME), or cystine at low temperatures over a broad pH range. After expressing the recombinant protein, the cell homogenate is passed through the column containing chitin. This allows the CBD of the chimeric protein to bind to the column. Furthermore, when the temperature is lowered and the molecules described above pass through the column, the chimeric protein undergoes self-splicing and only the target protein is eluted. This novel technique eliminates the need for a proteolysis step, and modified Sce VMA stays in column attached to chitin through CBD.[16]
Recently inteins have been used to purify proteins based on self aggregating peptides. Elastin-like polypeptides (ELPs) are a useful tool in biotechnology. Fused with target protein, they tend to form aggregates inside the cells.[17] This eliminates the chromatographic step needed in protein purification. The ELP tags have been used in the fusion protein of intein, so that the aggregates can be isolated without chromatography (by centrifugation) and then intein and tag can be cleaved in controlled manner to release the target protein into solution. This protein isolation can be done using continuous media flow, yielding high amounts of protein, making this process more economically efficient than conventional methods.[17] Another group of researchers used smaller self aggregating tags to isolate target protein. Small amphipathic peptides 18A and ELK16 (figure 5) were used to form self cleaving aggregating protein.[18]
References
- Bowman, EJ; Tenney, K; Bowman, BJ (Oct 1988). "Isolation of genes encoding the Neurospora vacuolar ATPase. Analysis of vma-1 encoding the 67-kDa subunit reveals homology to other ATPases". J Biol Chem. 263 (28): 13994–4001.
- Zimniak, L; Dittrich, P; Gogarten, JP; Kibak, H; Taiz, L (Jul 1988). "The cDNA sequence of the 69-kDa subunit of the carrot vacuolar H+-ATPase. Homology to the beta-chain of F0F1-ATPases". J Biol Chem. 263 (19): 9102–12.
- Shih, CK; Wagner, R; Feinstein, S; Kanik-Ennulat, C; Neff, N (Aug 1988). "A dominant trifluoperazine resistance gene from Saccharomyces cerevisiae has homology with F0F1 ATP synthase and confers calcium-sensitive growth". Mol Cell Biol. 8 (8): 3094–103. doi:10.1128/mcb.8.8.3094. PMC 363536. PMID 2905423.
- Hirata, R; Ohsumk, Y; Nakano, A; Kawasaki, H; Suzuki, K; Anraku, Y (Apr 1990). "Molecular structure of a gene, VMA1, encoding the catalytic subunit of H(+)-translocating adenosine triphosphatase from vacuolar membranes of Saccharomyces cerevisiae". J Biol Chem. 265 (12): 6726–33.
- Hirata R, Ohsumk Y, Nakano A, Kawasaki H, Suzuki K, Anraku Y (April 1990). "Molecular structure of a gene, VMA1, encoding the catalytic subunit of H(+)-translocating adenosine triphosphatase from vacuolar membranes of Saccharomyces cerevisiae". J. Biol. Chem. 265 (12): 6726–33. PMID 2139027.
- Kane PM, Yamashiro CT, Wolczyk DF, Neff N, Goebl M, Stevens TH (November 1990). "Protein splicing converts the yeast TFP1 gene product to the 69-kD subunit of the vacuolar H(+)-adenosine triphosphatase". Science. 250 (4981): 651–7. doi:10.1126/science.2146742. PMID 2146742.
- Swithers, Kristen S.; Soucy, Shannon M.; Gogarten, J. Peter (2012). "The Role of Reticulate Evolution in Creating Innovation and Complexity". International Journal of Evolutionary Biology. 2012: 1–10. doi:10.1155/2012/418964. ISSN 2090-8032. PMC 3403396. PMID 22844638.
- Dawkins, Richard (1976). The Selfish Gene. Oxford University Press.
- Perler, F. B. (2002). "InBase: the Intein Database". Nucleic Acids Research. 30 (1): 383–384. doi:10.1093/nar/30.1.383. ISSN 1362-4962. PMC 99080. PMID 11752343.
- Noren CJ, Wang J, Perler FB (2000). "Dissecting the chemistry of protein splicing and its applications". Angew Chem Int Ed Engl. 39 (3): 450–66. doi:10.1002/(sici)1521-3773(20000204)39:3<450::aid-anie450>3.3.co;2-6. PMID 10671234.
- Anraku, Y; Mizutani, R; Satow, Y (2005). "Protein splicing: its discovery and structural insight into novel chemical mechanisms". IUBMB Life. 57 (8): 563–74. doi:10.1080/15216540500215499. PMID 16118114.
- Wu, H.; Hu, Z.; Liu, X. Q. (1998). "Protein trans-splicing by a split intein encoded in a split DnaE gene of Synechocystis sp. PCC6803". Proceedings of the National Academy of Sciences of the United States of America. 95 (16): 9226–9231. doi:10.1073/pnas.95.16.9226. PMC 21320. PMID 9689062.
- Schwarzer D, Cole PA (2005). "Protein semisynthesis and expressed protein ligation: chasing a protein's tail". Curr Opin Chem Biol. 9 (6): 561–9. doi:10.1016/j.cbpa.2005.09.018. PMID 16226484.
- Muralidharan V, Muir TW (2006). "Protein ligation: an enabling technology for the biophysical analysis of proteins". Nat. Methods. 3 (6): 429–38. doi:10.1038/nmeth886. PMID 16721376.
- de Grey, Aubrey D.N.J (2000). "Mitochondrial gene therapy: an arena for the biomedical use of inteins". Trends in Biotechnology. 18 (9): 394–399. doi:10.1016/S0167-7799(00)01476-1. ISSN 0167-7799. PMID 10942964.
- Chong, Shaorong; Mersha, Fana B; Comb, Donald G; Scott, Melissa E; Landry, David; Vence, Luis M; Perler, Francine B; Benner, Jack; Kucera, Rebecca B; Hirvonen, Christine A; Pelletier, John J; Paulus, Henry; Xu, Ming-Qun (1997). "Single-column purification of free recombinant proteins using a self-cleavable affinity tag derived from a protein splicing element". Gene. 192 (2): 271–281. doi:10.1016/S0378-1119(97)00105-4. ISSN 0378-1119.
- Fong, Baley A; Wood, David W (2010). "Expression and purification of ELP-intein-tagged target proteins in high cell density E. coli fermentation". Microbial Cell Factories. 9 (1): 77. doi:10.1186/1475-2859-9-77. ISSN 1475-2859. PMC 2978133. PMID 20959011.
- Xing, Lei; Wu, Wei; Zhou, Bihong; Lin, Zhanglin (2011). "Streamlined protein expression and purification using cleavable self-aggregating tags". Microbial Cell Factories. 10 (1): 42. doi:10.1186/1475-2859-10-42. ISSN 1475-2859. PMC 3124420. PMID 21631955.
Further reading
- Gogarten, J Peter; Elena Hilario (2006). "Inteins, introns, and homing endonucleases: recent revelations about the life cycle of parasitic genetic elements". BMC Evol Biol. 6 (1): 94. doi:10.1186/1471-2148-6-94. ISSN 1471-2148. PMC 1654191. PMID 17101053.
External links
- The Intein Database
- Shmuel Pietrokovski's Intein database
- Short review
- Starokadomskyy PL. Protein Splicing, 2007
- Protein splicing mechanism and intein structure
- Protein+Splicing at the US National Library of Medicine Medical Subject Headings (MeSH)