Parsing
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part (of speech).[1]
The term has slightly different meanings in different branches of linguistics and computer science. Traditional sentence parsing is often performed as a method of understanding the exact meaning of a sentence or word, sometimes with the aid of devices such as sentence diagrams. It usually emphasizes the importance of grammatical divisions such as subject and predicate.
Within computational linguistics the term is used to refer to the formal analysis by a computer of a sentence or other string of words into its constituents, resulting in a parse tree showing their syntactic relation to each other, which may also contain semantic and other information. Some parsing algorithms may generate a parse forest or list of parse trees for a syntactically ambiguous input.[2]
The term is also used in psycholinguistics when describing language comprehension. In this context, parsing refers to the way that human beings analyze a sentence or phrase (in spoken language or text) "in terms of grammatical constituents, identifying the parts of speech, syntactic relations, etc."[1] This term is especially common when discussing what linguistic cues help speakers to interpret garden-path sentences.
Within computer science, the term is used in the analysis of computer languages, referring to the syntactic analysis of the input code into its component parts in order to facilitate the writing of compilers and interpreters. The term may also be used to describe a split or separation.
Human languages
Traditional methods
The traditional grammatical exercise of parsing, sometimes known as clause analysis, involves breaking down a text into its component parts of speech with an explanation of the form, function, and syntactic relationship of each part.[3] This is determined in large part from study of the language's conjugations and declensions, which can be quite intricate for heavily inflected languages. To parse a phrase such as 'man bites dog' involves noting that the singular noun 'man' is the subject of the sentence, the verb 'bites' is the third person singular of the present tense of the verb 'to bite', and the singular noun 'dog' is the object of the sentence. Techniques such as sentence diagrams are sometimes used to indicate relation between elements in the sentence.
Parsing was formerly central to the teaching of grammar throughout the English-speaking world, and widely regarded as basic to the use and understanding of written language. However, the general teaching of such techniques is no longer current.
Computational methods
In some machine translation and natural language processing systems, written texts in human languages are parsed by computer programs.[4] Human sentences are not easily parsed by programs, as there is substantial ambiguity in the structure of human language, whose usage is to convey meaning (or semantics) amongst a potentially unlimited range of possibilities but only some of which are germane to the particular case.[5] So an utterance "Man bites dog" versus "Dog bites man" is definite on one detail but in another language might appear as "Man dog bites" with a reliance on the larger context to distinguish between those two possibilities, if indeed that difference was of concern. It is difficult to prepare formal rules to describe informal behaviour even though it is clear that some rules are being followed.
In order to parse natural language data, researchers must first agree on the grammar to be used. The choice of syntax is affected by both linguistic and computational concerns; for instance some parsing systems use lexical functional grammar, but in general, parsing for grammars of this type is known to be NP-complete. Head-driven phrase structure grammar is another linguistic formalism which has been popular in the parsing community, but other research efforts have focused on less complex formalisms such as the one used in the Penn Treebank. Shallow parsing aims to find only the boundaries of major constituents such as noun phrases. Another popular strategy for avoiding linguistic controversy is dependency grammar parsing.
Most modern parsers are at least partly statistical; that is, they rely on a corpus of training data which has already been annotated (parsed by hand). This approach allows the system to gather information about the frequency with which various constructions occur in specific contexts. (See machine learning.) Approaches which have been used include straightforward PCFGs (probabilistic context-free grammars),[6] maximum entropy,[7] and neural nets.[8] Most of the more successful systems use lexical statistics (that is, they consider the identities of the words involved, as well as their part of speech). However such systems are vulnerable to overfitting and require some kind of smoothing to be effective.
Parsing algorithms for natural language cannot rely on the grammar having 'nice' properties as with manually designed grammars for programming languages. As mentioned earlier some grammar formalisms are very difficult to parse computationally; in general, even if the desired structure is not context-free, some kind of context-free approximation to the grammar is used to perform a first pass. Algorithms which use context-free grammars often rely on some variant of the CYK algorithm, usually with some heuristic to prune away unlikely analyses to save time. (See chart parsing.) However some systems trade speed for accuracy using, e.g., linear-time versions of the shift-reduce algorithm. A somewhat recent development has been parse reranking in which the parser proposes some large number of analyses, and a more complex system selects the best option. Semantic parsers convert texts into representations of their meanings.[9]
Psycholinguistics
In psycholinguistics, parsing involves not just the assignment of words to categories (formation of ontological insights), but the evaluation of the meaning of a sentence according to the rules of syntax drawn by inferences made from each word in the sentence (known as connotation). This normally occurs as words are being heard or read. Consequently, psycholinguistic models of parsing are of necessity incremental, meaning that they build up an interpretation as the sentence is being processed, which is normally expressed in terms of a partial syntactic structure. Creation of initially wrong structures occurs when interpreting garden-path sentences.
Discourse analysis
Discourse analysis examines ways to analyze language use and semiotic events. Persuasive language may be called rhetoric.
Computer languages
Parser
A parser is a software component that takes input data (frequently text) and builds a data structure – often some kind of parse tree, abstract syntax tree or other hierarchical structure, giving a structural representation of the input while checking for correct syntax. The parsing may be preceded or followed by other steps, or these may be combined into a single step. The parser is often preceded by a separate lexical analyser, which creates tokens from the sequence of input characters; alternatively, these can be combined in scannerless parsing. Parsers may be programmed by hand or may be automatically or semi-automatically generated by a parser generator. Parsing is complementary to templating, which produces formatted output. These may be applied to different domains, but often appear together, such as the scanf/printf pair, or the input (front end parsing) and output (back end code generation) stages of a compiler.
The input to a parser is often text in some computer language, but may also be text in a natural language or less structured textual data, in which case generally only certain parts of the text are extracted, rather than a parse tree being constructed. Parsers range from very simple functions such as scanf, to complex programs such as the frontend of a C++ compiler or the HTML parser of a web browser. An important class of simple parsing is done using regular expressions, in which a group of regular expressions defines a regular language and a regular expression engine automatically generating a parser for that language, allowing pattern matching and extraction of text. In other contexts regular expressions are instead used prior to parsing, as the lexing step whose output is then used by the parser.
The use of parsers varies by input. In the case of data languages, a parser is often found as the file reading facility of a program, such as reading in HTML or XML text; these examples are markup languages. In the case of programming languages, a parser is a component of a compiler or interpreter, which parses the source code of a computer programming language to create some form of internal representation; the parser is a key step in the compiler frontend. Programming languages tend to be specified in terms of a deterministic context-free grammar because fast and efficient parsers can be written for them. For compilers, the parsing itself can be done in one pass or multiple passes – see one-pass compiler and multi-pass compiler.
The implied disadvantages of a one-pass compiler can largely be overcome by adding fix-ups, where provision is made for code relocation during the forward pass, and the fix-ups are applied backwards when the current program segment has been recognized as having been completed. An example where such a fix-up mechanism would be useful would be a forward GOTO statement, where the target of the GOTO is unknown until the program segment is completed. In this case, the application of the fix-up would be delayed until the target of the GOTO was recognized. Conversely, a backward GOTO does not require a fix-up, as the location will already be known.
Context-free grammars are limited in the extent to which they can express all of the requirements of a language. Informally, the reason is that the memory of such a language is limited. The grammar cannot remember the presence of a construct over an arbitrarily long input; this is necessary for a language in which, for example, a name must be declared before it may be referenced. More powerful grammars that can express this constraint, however, cannot be parsed efficiently. Thus, it is a common strategy to create a relaxed parser for a context-free grammar which accepts a superset of the desired language constructs (that is, it accepts some invalid constructs); later, the unwanted constructs can be filtered out at the semantic analysis (contextual analysis) step.
For example, in Python the following is syntactically valid code:
x = 1
print(x)
The following code, however, is syntactically valid in terms of the context-free grammar, yielding a syntax tree with the same structure as the previous, but is syntactically invalid in terms of the context-sensitive grammar, which requires that variables be initialized before use:
x = 1
print(y)
Rather than being analyzed at the parsing stage, this is caught by checking the values in the syntax tree, hence as part of semantic analysis: context-sensitive syntax is in practice often more easily analyzed as semantics.
Overview of process
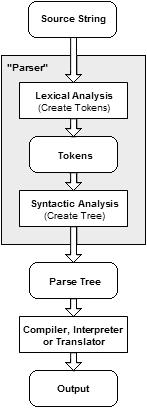
The following example demonstrates the common case of parsing a computer language with two levels of grammar: lexical and syntactic.
The first stage is the token generation, or lexical analysis, by which the input character stream is split into meaningful symbols defined by a grammar of regular expressions. For example, a calculator program would look at an input such as "12 * (3 + 4)^2" and split it into the tokens 12, *, (, 3, +, 4, ), ^, 2, each of which is a meaningful symbol in the context of an arithmetic expression. The lexer would contain rules to tell it that the characters *, +, ^, ( and ) mark the start of a new token, so meaningless tokens like "12*" or "(3" will not be generated.
The next stage is parsing or syntactic analysis, which is checking that the tokens form an allowable expression. This is usually done with reference to a context-free grammar which recursively defines components that can make up an expression and the order in which they must appear. However, not all rules defining programming languages can be expressed by context-free grammars alone, for example type validity and proper declaration of identifiers. These rules can be formally expressed with attribute grammars.
The final phase is semantic parsing or analysis, which is working out the implications of the expression just validated and taking the appropriate action.[10] In the case of a calculator or interpreter, the action is to evaluate the expression or program; a compiler, on the other hand, would generate some kind of code. Attribute grammars can also be used to define these actions.
Types of parsers
The task of the parser is essentially to determine if and how the input can be derived from the start symbol of the grammar. This can be done in essentially two ways:
- Top-down parsing - Top-down parsing can be viewed as an attempt to find left-most derivations of an input-stream by searching for parse trees using a top-down expansion of the given formal grammar rules. Tokens are consumed from left to right. Inclusive choice is used to accommodate ambiguity by expanding all alternative right-hand-sides of grammar rules.[11] This is known as the primordial soup approach. Very similar to sentence diagramming, primordial soup breaks down the constituencies of sentences.[12]
- Bottom-up parsing - A parser can start with the input and attempt to rewrite it to the start symbol. Intuitively, the parser attempts to locate the most basic elements, then the elements containing these, and so on. LR parsers are examples of bottom-up parsers. Another term used for this type of parser is Shift-Reduce parsing.
LL parsers and recursive-descent parser are examples of top-down parsers which cannot accommodate left recursive production rules. Although it has been believed that simple implementations of top-down parsing cannot accommodate direct and indirect left-recursion and may require exponential time and space complexity while parsing ambiguous context-free grammars, more sophisticated algorithms for top-down parsing have been created by Frost, Hafiz, and Callaghan[13][14] which accommodate ambiguity and left recursion in polynomial time and which generate polynomial-size representations of the potentially exponential number of parse trees. Their algorithm is able to produce both left-most and right-most derivations of an input with regard to a given context-free grammar.
An important distinction with regard to parsers is whether a parser generates a leftmost derivation or a rightmost derivation (see context-free grammar). LL parsers will generate a leftmost derivation and LR parsers will generate a rightmost derivation (although usually in reverse).[11]
Some graphical parsing algorithms have been designed for visual programming languages.[15][16] Parsers for visual languages are sometimes based on graph grammars.[17]
Adaptive parsing algorithms have been used to construct "self-extending" natural language user interfaces.[18]
Parser development software
Some of the well known parser development tools include the following:
Lookahead
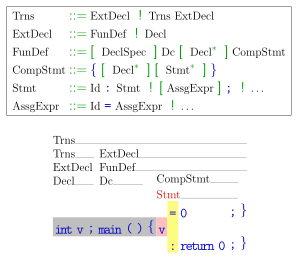
int v;main(){" and is about choose a rule to derive Stmt. Looking only at the first lookahead token "v", it cannot decide which of both alternatives for Stmt to choose; the latter requires peeking at the second token.Lookahead establishes the maximum incoming tokens that a parser can use to decide which rule it should use. Lookahead is especially relevant to LL, LR, and LALR parsers, where it is often explicitly indicated by affixing the lookahead to the algorithm name in parentheses, such as LALR(1).
Most programming languages, the primary target of parsers, are carefully defined in such a way that a parser with limited lookahead, typically one, can parse them, because parsers with limited lookahead are often more efficient. One important change to this trend came in 1990 when Terence Parr created ANTLR for his Ph.D. thesis, a parser generator for efficient LL(k) parsers, where k is any fixed value.
LR parsers typically have only a few actions after seeing each token. They are shift (add this token to the stack for later reduction), reduce (pop tokens from the stack and form a syntactic construct), end, error (no known rule applies) or conflict (does not know whether to shift or reduce).
Lookahead has two advantages.
- It helps the parser take the correct action in case of conflicts. For example, parsing the if statement in the case of an else clause.
- It eliminates many duplicate states and eases the burden of an extra stack. A C language non-lookahead parser will have around 10,000 states. A lookahead parser will have around 300 states.
Example: Parsing the Expression 1 + 2 * 3
| Set of expression parsing rules (called grammar) is as follows, | ||
| Rule1: | E → E + E | Expression is the sum of two expressions. |
| Rule2: | E → E * E | Expression is the product of two expressions. |
| Rule3: | E → number | Expression is a simple number |
| Rule4: | + has less precedence than * | |
Most programming languages (except for a few such as APL and Smalltalk) and algebraic formulas give higher precedence to multiplication than addition, in which case the correct interpretation of the example above is 1 + (2 * 3). Note that Rule4 above is a semantic rule. It is possible to rewrite the grammar to incorporate this into the syntax. However, not all such rules can be translated into syntax.
- Simple non-lookahead parser actions
Initially Input = [1, +, 2, *, 3]
- Shift "1" onto stack from input (in anticipation of rule3). Input = [+, 2, *, 3] Stack = [1]
- Reduces "1" to expression "E" based on rule3. Stack = [E]
- Shift "+" onto stack from input (in anticipation of rule1). Input = [2, *, 3] Stack = [E, +]
- Shift "2" onto stack from input (in anticipation of rule3). Input = [*, 3] Stack = [E, +, 2]
- Reduce stack element "2" to Expression "E" based on rule3. Stack = [E, +, E]
- Reduce stack items [E, +, E] and new input "E" to "E" based on rule1. Stack = [E]
- Shift "*" onto stack from input (in anticipation of rule2). Input = [3] Stack = [E,*]
- Shift "3" onto stack from input (in anticipation of rule3). Input = [] (empty) Stack = [E, *, 3]
- Reduce stack element "3" to expression "E" based on rule3. Stack = [E, *, E]
- Reduce stack items [E, *, E] and new input "E" to "E" based on rule2. Stack = [E]
The parse tree and resulting code from it is not correct according to language semantics.
To correctly parse without lookahead, there are three solutions:
- The user has to enclose expressions within parentheses. This often is not a viable solution.
- The parser needs to have more logic to backtrack and retry whenever a rule is violated or not complete. The similar method is followed in LL parsers.
- Alternatively, the parser or grammar needs to have extra logic to delay reduction and reduce only when it is absolutely sure which rule to reduce first. This method is used in LR parsers. This correctly parses the expression but with many more states and increased stack depth.
- Lookahead parser actions
- Shift 1 onto stack on input 1 in anticipation of rule3. It does not reduce immediately.
- Reduce stack item 1 to simple Expression on input + based on rule3. The lookahead is +, so we are on path to E +, so we can reduce the stack to E.
- Shift + onto stack on input + in anticipation of rule1.
- Shift 2 onto stack on input 2 in anticipation of rule3.
- Reduce stack item 2 to Expression on input * based on rule3. The lookahead * expects only E before it.
- Now stack has E + E and still the input is *. It has two choices now, either to shift based on rule2 or reduction based on rule1. Since * has higher precedence than + based on rule4, we shift * onto stack in anticipation of rule2.
- Shift 3 onto stack on input 3 in anticipation of rule3.
- Reduce stack item 3 to Expression after seeing end of input based on rule3.
- Reduce stack items E * E to E based on rule2.
- Reduce stack items E + E to E based on rule1.
The parse tree generated is correct and simply more efficient than non-lookahead parsers. This is the strategy followed in LALR parsers.
See also
- Backtracking
- Chart parser
- Compiler-compiler
- Deterministic parsing
- Generating strings
- Grammar checker
- LALR parser
- Lexical analysis
- Pratt parser
- Shallow parsing
- Left corner parser
- Parsing expression grammar
- ASF+SDF Meta Environment
- DMS Software Reengineering Toolkit
- Program transformation
- Source code generation
References
- "Parse". dictionary.reference.com. Retrieved 27 November 2010.
- Masaru Tomita (6 December 2012). Generalized LR Parsing. Springer Science & Business Media. ISBN 978-1-4615-4034-2.
- "Grammar and Composition".
- Christopher D.. Manning; Christopher D. Manning; Hinrich Schütze (1999). Foundations of Statistical Natural Language Processing. MIT Press. ISBN 978-0-262-13360-9.
- Jurafsky, Daniel (1996). "A Probabilistic Model of Lexical and Syntactic Access and Disambiguation". Cognitive Science. 20 (2): 137–194. CiteSeerX 10.1.1.150.5711. doi:10.1207/s15516709cog2002_1.
- Klein, Dan, and Christopher D. Manning. "Accurate unlexicalized parsing." Proceedings of the 41st Annual Meeting on Association for Computational Linguistics-Volume 1. Association for Computational Linguistics, 2003.
- Charniak, Eugene. "A maximum-entropy-inspired parser." Proceedings of the 1st North American chapter of the Association for Computational Linguistics conference. Association for Computational Linguistics, 2000.
- Chen, Danqi, and Christopher Manning. "A fast and accurate dependency parser using neural networks." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
- Jia, Robin; Liang, Percy (2016-06-11). "Data Recombination for Neural Semantic Parsing". arXiv:1606.03622 [cs.CL].
- Berant, Jonathan, and Percy Liang. "Semantic parsing via paraphrasing." Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2014.
- Aho, A.V., Sethi, R. and Ullman, J.D. (1986) " Compilers: principles, techniques, and tools." Addison-Wesley Longman Publishing Co., Inc. Boston, MA, USA.
- Sikkel, Klaas, 1954- (1997). Parsing schemata : a framework for specification and analysis of parsing algorithms. Berlin: Springer. ISBN 9783642605413. OCLC 606012644.CS1 maint: multiple names: authors list (link)
- Frost, R., Hafiz, R. and Callaghan, P. (2007) " Modular and Efficient Top-Down Parsing for Ambiguous Left-Recursive Grammars ." 10th International Workshop on Parsing Technologies (IWPT), ACL-SIGPARSE , Pages: 109 - 120, June 2007, Prague.
- Frost, R., Hafiz, R. and Callaghan, P. (2008) " Parser Combinators for Ambiguous Left-Recursive Grammars." 10th International Symposium on Practical Aspects of Declarative Languages (PADL), ACM-SIGPLAN , Volume 4902/2008, Pages: 167 - 181, January 2008, San Francisco.
- Rekers, Jan, and Andy Schürr. "Defining and parsing visual languages with layered graph grammars." Journal of Visual Languages & Computing 8.1 (1997): 27-55.
- Rekers, Jan, and A. Schurr. "A graph grammar approach to graphical parsing." Visual Languages, Proceedings., 11th IEEE International Symposium on. IEEE, 1995.
- Zhang, Da-Qian, Kang Zhang, and Jiannong Cao. "A context-sensitive graph grammar formalism for the specification of visual languages." The Computer Journal 44.3 (2001): 186-200.
- Jill Fain Lehman (6 December 2012). Adaptive Parsing: Self-Extending Natural Language Interfaces. Springer Science & Business Media. ISBN 978-1-4615-3622-2.
- taken from Brian W. Kernighan and Dennis M. Ritchie (Apr 1988). The C Programming Language. Prentice Hall Software Series (2nd ed.). Englewood Cliffs/NJ: Prentice Hall. ISBN 0131103628. (Appendix A.13 "Grammar", p.193 ff)
Further reading
- Chapman, Nigel P., LR Parsing: Theory and Practice, Cambridge University Press, 1987. ISBN 0-521-30413-X
- Grune, Dick; Jacobs, Ceriel J.H., Parsing Techniques - A Practical Guide, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands. Originally published by Ellis Horwood, Chichester, England, 1990; ISBN 0-13-651431-6
External links
| Look up parse or parsing in Wiktionary, the free dictionary. |
- The Lemon LALR Parser Generator
- Stanford Parser The Stanford Parser
- Turin University Parser Natural language parser for the Italian, open source, developed in Common Lisp by Leonardo Lesmo, University of Torino, Italy.
- Short history of parser construction