m-ary tree
In graph theory, an m-ary tree (also known as k-ary or k-way tree) is a rooted tree in which each node has no more than m children. A binary tree is the special case where m = 2, and a ternary tree is another case with m = 3 that limits its children to three.
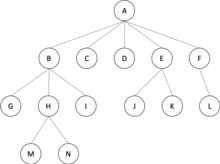
Types of m-ary trees
- A full m-ary tree is an m-ary tree where within each level every node has either 0 or m children.
- A complete m-ary tree is an m-ary tree which is maximally space efficient. It must be completely filled on every level except for the last level. However, if the last level is not complete, then all nodes of the tree must be "as far left as possible".[1]
- A perfect m-ary tree is a full[1] m-ary tree in which all leaf nodes are at the same depth.[2]
Properties of m-ary trees
- For an m-ary tree with height h, the upper bound for the maximum number of leaves is .
- The height h of an m-ary tree does not include the root node, with a tree containing only a root node having a height of 0.
- The height of a tree is equal to the maximum depth D of any node in the tree.
- The total number of nodes in a perfect m-ary tree is , while the height h is



- By the definition of Big-Ω, the maximum depth


- The height of a complete m-ary tree with n nodes is .
- The total number of possible m-ary tree with n nodes is (which is a Catalan number) [3].


Traversal methods for m-ary trees
Traversing a m-ary tree is very similar to binary tree traversal. The pre-order traversal goes to parent, left subtree and the right subtree, and for traversing post-order it goes by left subtree, right subtree, and parent node. For traversing in-order, since there are more than two children per node for m > 2, one must define the notion of left and right subtrees. One common method to establish left/right subtrees is to divide the list of children nodes into two groups. By defining an order on the m children of a node, the first nodes would constitute the left subtree and nodes would constitute the right subtree.


Convert a m-ary tree to binary tree
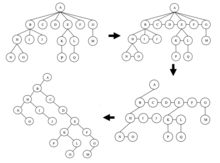
Using an array for representing a m-ary tree is inefficient, because most of the nodes in practical applications contain less than m children. As a result, this fact leads to a sparse array with large unused space in the memory. Converting an arbitrary m-ary tree to a binary tree would only increase the height of the tree by a constant factor and would not affect the overall worst-case time complexity. In other words, since .


First, we link all the immediate children nodes of a given parent node together in order to form a link list. Then, we keep the link from the parent to the first (i.e., the leftmost) child and remove all the other links to the rest of the children. We repeat this process for all the children (if they have any children) until we have processed all the internal nodes and rotate the tree by 45 degrees clockwise. The tree obtained is the desired binary tree obtained from the given m-ary tree.
Methods for storing m-ary trees
Arrays
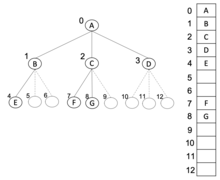
m-ary trees can also be stored in breadth-first order as an implicit data structure in arrays, and if the tree is a complete m-ary tree, this method wastes no space. In this compact arrangement, if a node has an index i, its c-th child in range {1,...,m} is found at index , while its parent (if any) is found at index (assuming the root has index zero, meaning a 0-based array). This method benefits from more compact storage and better locality of reference, particularly during a preorder traversal. The space complexity of this method is .



Pointer-based
Each node would have an internal array for storing pointers to each of its children:

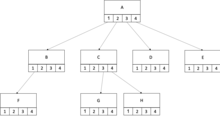
Compared to array-based implementation, this implementation method has superior space complexity of .

Enumeration of m-ary trees
Listing all possible m-ary trees are useful in many disciplines as a way of checking hypothesis or theories. Proper representation of m-ary tree objects can greatly simplify the generation process. One can construct a bit sequence representation using the depth-first search of a m-ary tree with n nodes indicating the presence of a node at a given index using binary values. For example, the bit sequence x=1110000100010001000 is representing a 3-ary tree with n=6 nodes as shown below.
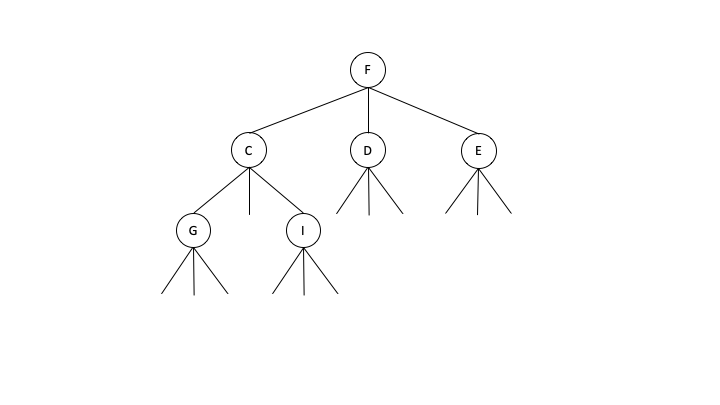
The problem with this representation is that listing all bit strings in lexicographic order would mean two successive strings might represent two trees that are lexicographically very different. Therefore, enumeration over binary strings would not necessarily result in an ordered generation of all m-ary trees.[4] A better representation is based on an integer string that indicates the number of zeroes between successive ones, known as Simple Zero Sequence. is a Simple Zero Sequence corresponding to the bit sequence where j is the number of zeroes needed at the tail end of the sequence to make the string have the appropriate length. For example, is the simple zero sequence representation of the above figure. A more compact representation of 00433 is , which is called zero sequence, which duplicate bases cannot be adjacent. This new representation allows to construct a next valid sequence in . A simple zero sequence is valid if






, that is to say that number of zeros in the bit sequence of a m-ary tree cannot exceed the total number of null pointers (i.e., pointers without any child node attached to them). This summation is putting restriction on nodes so that there is room for adding the without creating an invalid stracture (i.e. having an available null pointer to attached the last node to it).


The table below shows the list of all valid simple zero sequences of all 3-ary trees with 4 nodes:
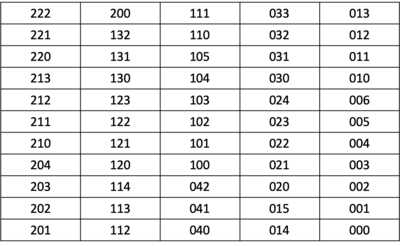
Starting from the bottom right of the table (i.e., "000"), there is a backbone template that governs the generation of the possible ordered trees starting from "000" to "006". The backbone template for this group ("00X") is depicted below, where an additional node is added in the positions labeled "x".
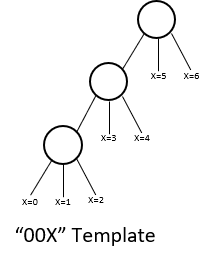
Once one has exhausted all possible positions in the backbone template, a new template will be constructed by shifting the 3rd node one position to the right as depicted below, and the same enumeration would occur until all possible positions labeled "X" is exhausted.

Going back to the table of enumeration of all m-ary trees, where and , we can easily observe the apparent jump from "006" to "010" can be explained trivially in an algorithmic fashion as depicted below:



The pseudocode for this enumeration is given below[4]:
Procedure NEXT() if for all i then finished else if i <n-1 then end if for end if end







Loopless enumeration
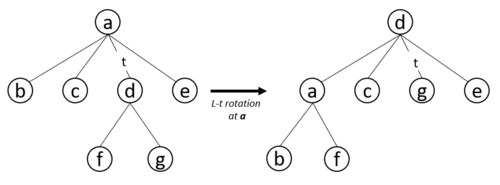
A generation algorithm that takes worst-case time are called loopless since the time complexity cannot involve a loop or recursion. Loopless enumeration of m-ary trees is said to be loopless if after initialization, it generates successive tree objects in . For a given a m-ary tree T with being one of its nodes and its child, a left-t rotation at is done by making the root node, and making and all of its subtrees a child of , additionally we assign the left most children of to and the right most child of stays attached to it while is promoted to root, as shown below:





Convert an m-ary tree to left-tree
for :
for :
while t child of node at depth :
L-t rotation at nodes at depth i
end while
end for
end for



A right-t rotation at d is the inverse of this operation. The left chain of T is a sequence of nodes such that is the root and all nodes except have one child connected to their left most (i.e., ) pointer. Any m-ary tree can be transformed to a left-chain tree using sequence of finite left-t rotations for t from 2 to m. Specifically, this can be done by performing left-t rotations on each node until all of its sub-tree become null at each depth. Then, the sequence of number of left-t rotations performed at depth i denoted by defines a codeword of a m-ary tree that can be recovered by performing the same sequence of right-t rotations.






Let the tuple of represent the number of L-2 rotations, L-3 rotations, ..., L-m rotations that has occurred at the root (i.e., i=1).Then, is the number of L-t rotations required at depth i.


Capturing counts of left-rotations at each depth is a way of encoding an m-ary tree. Thus, enumerating all possible legal encoding would helps us to generate all the m-ary trees for a given m and n. But, not all sequences of m non-negative integers represent a valid m-ary tree. A sequence of non-negative integers is a valid representation of a m-ary tree if and only if [5]


Lexicographically smallest code-word representation of a m-ary with n nodes is all zeros and the largest is n-1 ones followed by m-1 zero on its right.
Initialization
c[i] to zero for all i from 1 to
p[i] set to for i from 1 to n
Termination Condition
Terminate when c[1] = n-1
Procedure NEXT [5]
if then
end if
if then
else
end if
end












Application
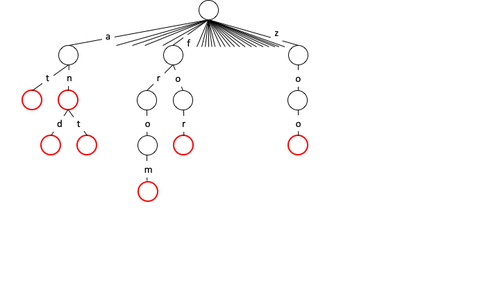
One of the applications of m-ary tree is creating a dictionary for validation of acceptable strings. In order to do that, let m be equal to the number of valid alphabets (e.g., number of letters of the English alphabet) with the root of the tree representing the starting point. Similarly, each of the children can have up to m children representing the next possible character in the string. Thus, characters along the paths can represent valid keys by marking the end character of the keys as "terminal node". For example, in the example below "at" and "and" are valid key strings with "t" and "d" marked as terminal nodes. Terminal nodes can store extra information to be associated with a given key. There are similar ways to building such a dictionary using B-tree, Octree and/or trie.
References
- "Ordered Trees". Retrieved 19 November 2012.
- Black, Paul E. (20 April 2011). "perfect k-ary tree". U.S. National Institute of Standards and Technology. Retrieved 10 October 2011.
- Graham, Ronald L.; Knuth, Donald E.; Patashnik, Oren (1994). Concrete Mathematics: A Foundation for Computer Science (2nd Edition). AIP.
- Baronaigien, Dominique Roelants van (2000). "Loop Free Generation of K-ary trees". Journal of Algorithms. 35 (1): 100–107. doi:10.1006/jagm.1999.1073.
- Korsh, James F (1994). "Loopless generation of k-ary tree sequences". Information Processing Letters. Elsevier. 52 (5): 243–247. doi:10.1016/0020-0190(94)00149-9.
- Storer, James A. (2001). An Introduction to Data Structures and Algorithms. Birkhäuser Boston. ISBN 3-7643-4253-6.