iDistance
In pattern recognition, the iDistance is an indexing and query processing technique for k-nearest neighbor queries on point data in multi-dimensional metric spaces. The kNN query is one of the hardest problems on multi-dimensional data, especially when the dimensionality of the data is high. The iDistance is designed to process kNN queries in high-dimensional spaces efficiently and it is especially good for skewed data distributions, which usually occur in real-life data sets.
Indexing
Building the iDistance index has two steps:
- A number of reference points in the data space are chosen. There are various ways of choosing reference points. Using cluster centers as reference points is the most efficient way.
- The distance between a data point and its closest reference point is calculated. This distance plus a scaling value is called the point's iDistance. By this means, points in a multi-dimensional space are mapped to one-dimensional values, and then a B+-tree can be adopted to index the points using the iDistance as the key.
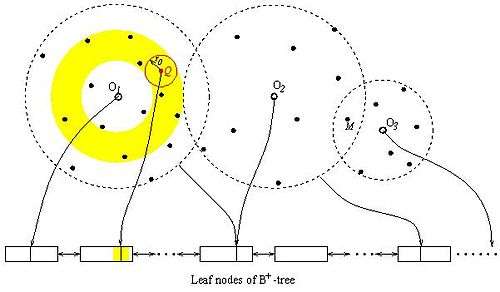
The figure on the right shows an example where three reference points (O1, O2, O3) are chosen. The data points are then mapped to a one-dimensional space and indexed in a B+-tree.
Query processing
To process a kNN query, the query is mapped to a number of one-dimensional range queries, which can be processed efficiently on a B+-tree. In the above figure, the query Q is mapped to a value in the B+-tree while the kNN search ``sphere" is mapped to a range in the B+-tree. The search sphere expands gradually until the k NNs are found. This corresponds to gradually expanding range searches in the B+-tree.
The iDistance technique can be viewed as a way of accelerating the sequential scan. Instead of scanning records from the beginning to the end of the data file, the iDistance starts the scan from spots where the nearest neighbors can be obtained early with a very high probability.
Applications
The iDistance has been used in many applications including
- Image retrieval [1]
- Video indexing [2]
- Similarity search in P2P systems [3]
- Mobile computing [4]
Historical background
The iDistance was first proposed by Cui Yu, Beng Chin Ooi, Kian-Lee Tan and H. V. Jagadish in 2001.[5] Later, together with Rui Zhang, they improved the technique and performed a more comprehensive study on it in 2005.[6]
References
- Junqi Zhang, Xiangdong Zhou, Wei Wang, Baile Shi, Jian Pei, Using High Dimensional Indexes to Support Relevance Feedback Based Interactive Images Retrieval, Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 1211-1214, 2006.
- Heng Tao Shen, Beng Chin Ooi, Xiaofang Zhou, Towards Effective Indexing for Very Large Video Sequence Database, Proceedings of the ACM SIGMOD International Conference on Management of Data, Baltimore, Maryland, United States, 730-741, 2005.
- Christos Doulkeridis, Akrivi Vlachou, Yannis Kotidis, Michalis Vazirgiannis, Peer-to-Peer Similarity Search in Metric Spaces, Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 986-997, 2007.
- Sergio Ilarri, Eduardo Mena, Arantza Illarramendi, Location-Dependent Queries in Mobile Contexts: Distributed Processing Using Mobile Agents, IEEE Transactions on Mobile Computing, Volume 5, Issue 8, Aug. 2006 Page(s): 1029 - 1043.
- Cui Yu, Beng Chin Ooi, Kian-Lee Tan and H. V. Jagadish Indexing the distance: an efficient method to KNN processing, Proceedings of the 27th International Conference on Very Large Data Bases, Rome, Italy, 421-430, 2001.
- H. V. Jagadish, Beng Chin Ooi, Kian-Lee Tan, Cui Yu and Rui Zhang iDistance: An Adaptive B+-tree Based Indexing Method for Nearest Neighbor Search, ACM Transactions on Data Base Systems (ACM TODS), 30, 2, 364-397, June 2005.