Hopfield network
A Hopfield network is a form of recurrent artificial neural network popularized by John Hopfield in 1982, but described earlier by Little in 1974.[1][2] Hopfield networks serve as content-addressable ("associative") memory systems with binary threshold nodes. They are guaranteed to converge to a local minimum and, therefore, may converge to a false pattern (wrong local minimum) rather than the stored pattern (expected local minimum). Hopfield networks also provide a model for understanding human memory [3][4].
Structure
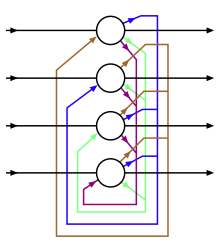
The units in Hopfield nets are binary threshold units, i.e. the units only take on two different values for their states and the value is determined by whether or not the units' input exceeds their threshold. Hopfield nets normally have units that take on values of 1 or -1, and this convention will be used throughout this article. However, other literature might use units that take values of 0 and 1.
Every pair of units i and j in a Hopfield network has a connection that is described by the connectivity weight . In this sense, the Hopfield network can be formally described as a complete undirected graph , where is a set of McCulloch-Pitts neurons and is a function that links pairs of units to a real value, the connectivity weight.




The connections in a Hopfield net typically have the following restrictions:
- (no unit has a connection with itself)
- (connections are symmetric)


The constraint that weights are symmetric guarantees that the energy function decreases monotonically while following the activation rules.[5] A network with asymmetric weights may exhibit some periodic or chaotic behaviour; however, Hopfield found that this behavior is confined to relatively small parts of the phase space and does not impair the network's ability to act as a content-addressable associative memory system.
Updating
Updating one unit (node in the graph simulating the artificial neuron) in the Hopfield network is performed using the following rule:

where:
- is the strength of the connection weight from unit j to unit i (the weight of the connection).
- is the state of unit i.
- is the threshold of unit i.


Updates in the Hopfield network can be performed in two different ways:
- Asynchronous: Only one unit is updated at a time. This unit can be picked at random, or a pre-defined order can be imposed from the very beginning.
- Synchronous: All units are updated at the same time. This requires a central clock to the system in order to maintain synchronization. This method is viewed by some as less realistic, based on an absence of observed global clock influencing analogous biological or physical systems of interest.
Neurons "attract or repel each other" in state-space
The weight between two units has a powerful impact upon the values of the neurons. Consider the connection weight between two neurons i and j. If , the updating rule implies that:

- when , the contribution of j in the weighted sum is positive. Thus, is pulled by j towards its value
- when , the contribution of j in the weighted sum is negative. Then again, is pushed by j towards its value




Thus, the values of neurons i and j will converge if the weight between them is positive. Similarly, they will diverge if the weight is negative.
Working Principles of Discrete Hopfield Network and Continuous Hopfield Network
Bruck shed light on the behavior of a neuron in the discrete Hopfield Network when proving its convergence in his paper in 1990 [6]. A very recent paper [7] has further investigated the behavior of any neuron in both discrete-time Hopfield Network and continuous-time Hopfield Network when the corresponding energy function is minimized during an optimization process. Bruck shows [6] that neuron j changes its state if and only if it further decreases the following biased pseudo-cut. The discrete Hopfield Network minimizes the following Biased Pseudo-Cut [7] for the synaptic weight matrix of the Hopfield net.

where and represents the set of neurons which are -1 and +1, respectively, at time . For further details, see the recent paper [7].



The discrete-time Hopfield Network always minimizes exactly the following pseudo-cut ([6] , [7])

The continuous-time Hopfield Network always minimizes an upper bound to the following weighted cut [7]

where is a zero-centered sigmoid function.

Complex Hopfield Network, on the other hand, generally tends to minimize the so-called Shadow-Cut of the complex weight matrix of the net [8].
Energy
Hopfield nets have a scalar value associated with each state of the network, referred to as the "energy", E, of the network, where:

This quantity is called "energy" because it either decreases or stays the same upon network units being updated. Furthermore, under repeated updating the network will eventually converge to a state which is a local minimum in the energy function (which is considered to be a Lyapunov function). Thus, if a state is a local minimum in the energy function it is a stable state for the network. Note that this energy function belongs to a general class of models in physics under the name of Ising models; these in turn are a special case of Markov networks, since the associated probability measure, the Gibbs measure, has the Markov property.
Hopfield Network in Optimization
Hopfield and Tank presented the Hopfield Network application in solving the classical Traveling-Salesman Problem in 1985 [9]. Since then the Hopfield Network has been widely used for optimization. The idea of using the Hopfield Network in optimization problems is straightforward: If a constrained/unconstrained cost function can be written in the form of the Hopfield Energy function E, then there exists a Hopfield Network whose equilibrium points represent solutions to the constrained/unconstrained optimization problem. Minimizing the Hopfield Energy function both minimizes the objective function and satisfies the constraints also as the constraints are “embedded” into the synaptic weights of the network. Although including the optimization constraints into the synaptic weights in the best possible way is a challenging task, indeed many various difficult optimization problems with constraints in different disciplines have been converted to the Hopfield Energy function: Associative memory systems, Analog-to-Digital conversion, job-shop scheduling problem, quadratic assignment and other related NP-complete problems, channel allocation problem in wireless networks, mobile ad-hoc network routing problem, image restoration, system identification, combinatorial optimization, etc, just to name a few. Further details can be found in e.g. the paper [7].
Initialization and running
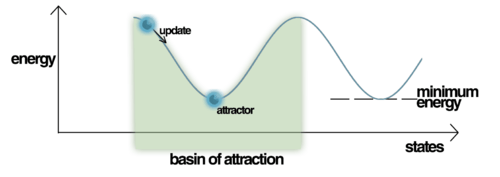
Initialization of the Hopfield Networks is done by setting the values of the units to the desired start pattern. Repeated updates are then performed until the network converges to an attractor pattern. Convergence is generally assured, as Hopfield proved that the attractors of this nonlinear dynamical system are stable, not periodic or chaotic as in some other systems. Therefore, in the context of Hopfield Networks, an attractor pattern is a final stable state, a pattern that cannot change any value within it under updating.
Training
Training a Hopfield net involves lowering the energy of states that the net should "remember". This allows the net to serve as a content addressable memory system, that is to say, the network will converge to a "remembered" state if it is given only part of the state. The net can be used to recover from a distorted input to the trained state that is most similar to that input. This is called associative memory because it recovers memories on the basis of similarity. For example, if we train a Hopfield net with five units so that the state (1, -1, 1, -1, 1) is an energy minimum, and we give the network the state (1, -1, -1, -1, 1) it will converge to (1, -1, 1, -1, 1). Thus, the network is properly trained when the energy of states which the network should remember are local minima. Note that, in contrast to Perceptron training, the thresholds of the neurons are never updated.
Learning rules
There are various different learning rules that can be used to store information in the memory of the Hopfield Network. It is desirable for a learning rule to have both of the following two properties:
- Local: A learning rule is local if each weight is updated using information available to neurons on either side of the connection that is associated with that particular weight.
- Incremental: New patterns can be learned without using information from the old patterns that have been also used for training. That is, when a new pattern is used for training, the new values for the weights only depend on the old values and on the new pattern.[10]
These properties are desirable, since a learning rule satisfying them is more biologically plausible. For example, since the human brain is always learning new concepts, one can reason that human learning is incremental. A learning system that was not incremental would generally be trained only once, with a huge batch of training data.
Hebbian learning rule for Hopfield networks
The Hebbian Theory was introduced by Donald Hebb in 1949, in order to explain "associative learning", in which simultaneous activation of neuron cells leads to pronounced increases in synaptic strength between those cells.[11] It is often summarized as "Neurons that fire together, wire together. Neurons that fire out of sync, fail to link".
The Hebbian rule is both local and incremental. For the Hopfield Networks, it is implemented in the following manner, when learning binary patterns:


where represents bit i from pattern .


If the bits corresponding to neurons i and j are equal in pattern , then the product will be positive. This would, in turn, have a positive effect on the weight and the values of i and j will tend to become equal. The opposite happens if the bits corresponding to neurons i and j are different.

The Storkey learning rule
This rule was introduced by Amos Storkey in 1997 and is both local and incremental. Storkey also showed that a Hopfield network trained using this rule has a greater capacity than a corresponding network trained using the Hebbian rule.[12] The weight matrix of an attractor neural network is said to follow the Storkey learning rule if it obeys:

where is a form of local field [10] at neuron i.

This learning rule is local, since the synapses take into account only neurons at their sides. The rule makes use of more information from the patterns and weights than the generalized Hebbian rule, due to the effect of the local field.
Spurious patterns
Patterns that the network uses for training (called retrieval states) become attractors of the system. Repeated updates would eventually lead to convergence to one of the retrieval states. However, sometimes the network will converge to spurious patterns (different from the training patterns).[13] The energy in these spurious patterns is also a local minimum. For each stored pattern x, the negation -x is also a spurious pattern.
A spurious state can also be a linear combination of an odd number of retrieval states. For example, when using 3 patterns , one can get the following spurious state:


Spurious patterns that have an even number of states cannot exist, since they might sum up to zero [13]
Capacity
The Network capacity of the Hopfield network model is determined by neuron amounts and connections within a given network. Therefore, the number of memories that are able to be stored is dependent on neurons and connections. Furthermore, it was shown that the recall accuracy between vectors and nodes was 0.138 (approximately 138 vectors can be recalled from storage for every 1000 nodes) (Hertz et al., 1991). Therefore, it is evident that many mistakes will occur if one tries to store a large number of vectors. When the Hopfield model does not recall the right pattern, it is possible that an intrusion has taken place, since semantically related items tend to confuse the individual, and recollection of the wrong pattern occurs. Therefore, the Hopfield network model is shown to confuse one stored item with that of another upon retrieval. Perfect recalls and high capacity, >0.14, can be loaded in the network by Storkey learning method; ETAM[14][15], ETAM experiments also in [16]. Ulterior models inspired by the Hopfield network were later devised to raise the storage limit and reduce the retrieval error rate, with some being capable of one-shot learning.[17]
The storage capacity can be given as where is the number of neurons in the net. Or approximately [18]


Human memory
The Hopfield model accounts for associative memory through the incorporation of memory vectors. Memory vectors can be slightly used, and this would spark the retrieval of the most similar vector in the network. However, we will find out that due to this process, intrusions can occur. In associative memory for the Hopfield network, there are two types of operations: auto-association and hetero-association. The first being when a vector is associated with itself, and the latter being when two different vectors are associated in storage. Furthermore, both types of operations are possible to store within a single memory matrix, but only if that given representation matrix is not one or the other of the operations, but rather the combination (auto-associative and hetero-associative) of the two. It is important to note that Hopfield's network model utilizes the same learning rule as Hebb's (1949) learning rule, which basically tried to show that learning occurs as a result of the strengthening of the weights by when activity is occurring.
Rizzuto and Kahana (2001) were able to show that the neural network model can account for repetition on recall accuracy by incorporating a probabilistic-learning algorithm. During the retrieval process, no learning occurs. As a result, the weights of the network remain fixed, showing that the model is able to switch from a learning stage to a recall stage. By adding contextual drift they were able to show the rapid forgetting that occurs in a Hopfield model during a cued-recall task. The entire network contributes to the change in the activation of any single node.
McCulloch and Pitts' (1943) dynamical rule, which describes the behavior of neurons, does so in a way that shows how the activations of multiple neurons map onto the activation of a new neuron's firing rate, and how the weights of the neurons strengthen the synaptic connections between the new activated neuron (and those that activated it). Hopfield would use McCulloch-Pitts's dynamical rule in order to show how retrieval is possible in the Hopfield network. However, it is important to note that Hopfield would do so in a repetitious fashion. Hopfield would use a nonlinear activation function, instead of using a linear function. This would therefore create the Hopfield dynamical rule and with this, Hopfield was able to show that with the nonlinear activation function, the dynamical rule will always modify the values of the state vector in the direction of one of the stored patterns.
See also
- Associative memory (disambiguation)
- Autoassociative memory
- Boltzmann machine – like a Hopfield net but uses annealed Gibbs sampling instead of gradient descent
- Dynamical systems model of cognition
- Ising model
- Hebbian theory
References
- Gurney, Kevin (2002). An Introduction to Neural Networks. Routledge. ISBN 978-1857285031.
- Sathasivam, Saratha (2008). "Logic Learning in Hopfield Networks". arXiv:0804.4075 [cs.LO].
- Amit, Daniel J. Modeling brain function: The world of attractor neural networks. Cambridge university press, 1992
- Rolls, Edmund T. Cerebral cortex: principles of operation. Oxford University Press, 2016
- MacKay, David J. C. (2003). "42. Hopfield Networks". Information Theory, Inference and Learning Algorithms. Cambridge University Press. p. 508. ISBN 978-0521642989.
This convergence proof depends crucially on the fact that the Hopfield network's connections are symmetric. It also depends on the updates being made asynchronously.
- J. Bruck, “On the convergence properties of the Hopfield model,” Proc. IEEE, vol. 78, pp. 1579–1585, Oct. 1990.
- Z. Uykan. "On the Working Principle of the Hopfield Neural Networks and its Equivalence to the GADIA in Optimization", IEEE Transactions on Neural Networks and Learning Systems, pp.1-11, 2019. (DOI: 10.1109/TNNLS.2019.2940920)
- Z. Uykan, "Shadow-Cuts Minimization/Maximization and Complex Hopfield Neural Networks", IEEE Transactions on Neural Networks and Learning Systems, pp.1-11, 2020. (DOI: 10.1109/TNNLS.2020.2980237). [Open Access]
- J.J. Hopfield, and D.W. Tank. "Neural computation of decisions in optimization problems." Biological Cybernetics 55, pp:141-146, (1985).
- Storkey, Amos J., and Romain Valabregue. "The basins of attraction of a new Hopfield learning rule." Neural Networks 12.6 (1999): 869-876.
- Hebb, Donald Olding. The organization of behavior: A neuropsychological theory. Lawrence Erlbaum, 2002.
- Storkey, Amos. "Increasing the capacity of a Hopfield network without sacrificing functionality." Artificial Neural Networks – ICANN'97 (1997): 451-456.
- Hertz, John A., Anders S. Krogh, and Richard G. Palmer. Introduction to the theory of neural computation. Vol. 1. Westview press, 1991.
- Liou, C.-Y.; Lin, S.-L. (2006). "Finite memory loading in hairy neurons". Natural Computing. 5 (1): 15–42. doi:10.1007/s11047-004-5490-x. S2CID 35025761.
- Liou, C.-Y.; Yuan, S.-K. (1999). "Error Tolerant Associative Memory". Biological Cybernetics. 81 (4): 331–342. doi:10.1007/s004220050566. PMID 10541936. S2CID 6168346.
- Yuan, S.-K. (June 1997). Expanding basins of attraction of the associative memory (Master thesis). National Taiwan University. 991010725609704786.
- ABOUDIB, Ala; GRIPON, Vincent; JIANG, Xiaoran (2014). "A study of retrieval algorithms of sparse messages in networks of neural cliques". COGNITIVE 2014 : The 6th International Conference on Advanced Cognitive Technologies and Applications: 140–146. arXiv:1308.4506. Bibcode:2013arXiv1308.4506A.
- Rajasekaran, Sundaramoorthy. (2003). Neural networks, fuzzy logic, and genetic algorithms : synthesis and applications. Pai, G. A. Vijayalakshmi. (Eastern economy ed.). New Delhi: Prentice-Hall of India. ISBN 81-203-2186-3. OCLC 56960832.
- J. J. Hopfield, "Neural networks and physical systems with emergent collective computational abilities", Proceedings of the National Academy of Sciences of the USA, vol. 79 no. 8 pp. 2554–2558, April 1982.
- Hebb, D.O. (1949). Organization of behavior. New York: Wiley
- Hertz, J., Krogh, A., & Palmer, R.G. (1991). Introduction to the theory of neural computation. Redwood City, CA: Addison-Wesley.
- McCulloch, W.S.; Pitts, W.H. (1943). "A logical calculus of the ideas immanent in nervous activity". Bulletin of Mathematical Biophysics. 5 (4): 115–133. doi:10.1007/BF02478259.
- Polyn, S.M.; Kahana, M.J. (2008). "Memory search and the neural representation of context". Trends in Cognitive Sciences. 12 (1): 24–30. doi:10.1016/j.tics.2007.10.010. PMC 2839453. PMID 18069046.
- Rizzuto, D.S.; Kahana, M.J. (2001). "An autoassociative neural network model of paired-associate learning". Neural Computation. 13 (9): 2075–2092. CiteSeerX 10.1.1.45.7929. doi:10.1162/089976601750399317. PMID 11516358. S2CID 7675117.
- Kruse, Borgelt, Klawonn, Moewes, Russ, Steinbrecher (2011). Computational Intelligence.
External links
| Wikimedia Commons has media related to Hopfield net. |
- Chapter 13 The Hopfield model of Neural Networks - A Systematic Introduction by Raul Rojas (ISBN 978-3-540-60505-8)
- Hopfield Network Javascript
- The Travelling Salesman Problem - Hopfield Neural Network JAVA Applet
- scholarpedia.org- Hopfield network - Article on Hopfield Networks by John Hopfield
- Hopfield Network Learning Using Deterministic Latent Variables - Tutorial by Tristan Fletcher
- Neural Lab Graphical Interface - Hopfield Neural Network graphical interface (Python & gtk)