E-aksharayan
e-Aksharayan is an optical character recognition engine for Indian languages. Some of research work from e-Aksharayan has been published in different conferences and journals.[1][2][3][4]
| Written in | C++ |
|---|---|
| Operating system | Linux (32 & 64-bit), Windows (32-bit) |
| Available in | Interface: English Recognition: Assamese, Bengali, Bodo, Devanagari, Kannada, Gujarati, Gurumukhi, Oriya, Malayalam, Meitei, Marathi, Tamil, Telugu, Tibetan and Urdu |
| Type | Optical character recognition |
| Website | ocr |
Bangla typos
Screenshots
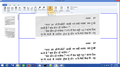 OCR output for Devanagari
OCR output for Devanagari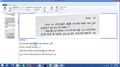 OCR output for Devanagari OCR output for Devanagari, sync between image and output
OCR output for Devanagari OCR output for Devanagari, sync between image and output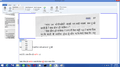 OCR output for Devanagari OCR output for Devanagari, spell checker
OCR output for Devanagari OCR output for Devanagari, spell checker
gollark: Quite easily, the new orbital laser target UI is great.
gollark: There will be minor but surely acceptable collateral damage.
gollark: I see. I will ready the lasers to remove "Italy".
gollark: Anyway, you *can* probably just install one of the many apps which does this using Android's VPN interface.
gollark: I imagine you could probably thingy the manifest somehow.
References
- Greedy Search for Active Learning of OCR Greedy Search for Active Learning of OCR
- Text graphic separation in Indian newspapers Text graphic separation in Indian newspapers
- An OCR System for the Meetei Mayek Script An OCR System for the Meetei Mayek Script
- Experiences of Integration and Performance Testing of Multilingual OCR for Printed Indian Scripts Experiences of Integration and Performance Testing of Multilingual OCR for Printed Indian Scripts
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.