Amazon DynamoDB
Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures[2] and is offered by Amazon.com as part of the Amazon Web Services portfolio.[3] DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation. Dynamo had a multi-master design requiring the client to resolve version conflicts and DynamoDB uses synchronous replication across multiple data centers[4] for high durability and availability. DynamoDB was announced by Amazon CTO Werner Vogels on January 18, 2012,[5] and is presented as an evolution of Amazon SimpleDB solution.[6]
 | |
| Developer(s) | Amazon.com |
|---|---|
| Initial release | January 2012[1] |
| Operating system | Cross-platform |
| Available in | English |
| Type |
|
| License | Proprietary |
| Website | aws |
Background
Vogels motivates the project in his 2012 announcement.[5] Amazon began as a decentralized network of services. Originally, services had direct access to each other's databases. When this became a bottleneck on engineering operations, services moved away from this direct access pattern in favor of public-facing APIs. Still, third-party relational database management systems struggled to handle Amazon's client base. This culminated during the 2004 holiday season, when several technologies failed under high traffic.
Engineers were normalizing these relational systems to reduce data redundancy, a design that optimizes for storage. The sacrifice: they stored a given "item" of data (e.g., the information pertaining to a product in a product database) over several relations, and it takes time to assemble disjoint parts for a query. Many of Amazon's services demanded mostly primary-key reads on their data, and with speed a top priority, putting these pieces together was extremely taxing.[7]
Content with compromising storage efficiency, Amazon's response was Dynamo: a highly available key-value store built for internal use.[5] Dynamo, it seemed, was everything their engineers needed, but adoption lagged. Amazon's developers opted for "just works" design patterns with S3 and SimpleDB. While these systems had noticeable design flaws, they did not demand the overhead of provisioning hardware and scaling and re-partitioning data. Amazon's next iteration of NoSQL technology, DynamoDB, automated these database management operations.
Overview
DynamoDB differs from other Amazon services by allowing developers to purchase a service based on throughput, rather than storage. If Auto Scaling is enabled, then the database will scale automatically.[8] Additionally, administrators can request throughput changes and DynamoDB will spread the data and traffic over a number of servers using solid-state drives, allowing predictable performance.[3] It offers integration with Hadoop via Elastic MapReduce.[9]
In September 2013, Amazon made a local development version of DynamoDB available so developers could test DynamoDB-backed applications locally.[10]
Development considerations
Data modeling
A DynamoDB table features items that have attributes, some of which form a primary key.[11] In relational systems, however, an item features each table attribute (or juggles "null" and "unknown" values in their absence), DynamoDB items are schema-less. The only exception: when creating a table, a developer specifies a primary key, and the table requires a key for every item. Primary keys must be scalar (strings, numbers, or binary) and can take one of two forms. A single-attribute primary key is known as the table's "partition key", which determines the partition that an item hashes to––more on partitioning below––so an ideal partition key has a uniform distribution over its range. A primary key can also feature a second attribute, which DynamoDB calls the table's "sort key". In this case, partition keys do not have to be unique; they are paired with sort keys to make a unique identifier for each item. The partition key is still used to determine which partition the item is stored in, but within each partition, items are sorted by the sort key.
Indices
In the relational model, indices typically serve as "helper" data structures to supplement a table. They allow the DBMS to optimize queries under the hood and they do not improve query functionality. In DynamoDB, there is no query optimizer, and an index is simply another table with a different key (or two) that sits beside the original.[11] When a developer creates an index, they create a new copy of their data, but only the fields that they specified get copied over (at a minimum, the fields that they index on and the original table's primary key).
DynamoDB users issue queries directly to their indices. There are two types of indices available. A global secondary index features a partition key (and optional sort key) that's different from the original table's partition key. A local secondary index features the same partition key as the original table, but a different sort key. Both indices introduce entirely new query functionality to a DynamoDB database by allowing queries on new keys. Similar to relational database management systems, DynamoDB updates indices automatically on addition/update/deletion, so you must be judicious when creating them or risk slowing down a write-heavy database with a slew of index updates.
Syntax
DynamoDB uses JSON for its syntax because of its ubiquity. The create table action demands just three arguments: TableName, KeySchema––a list containing a partition key and an optional sort key––and AttributeDefinitions––a list of attributes to be defined which must at least contain definitions for the attributes used as partition and sort keys. Whereas relational databases offer robust query languages, DynamoDB offers just Put, Get, Update, and Delete operations. Put requests contain the TableName attribute and an Item attribute, which consists of all the attributes and values the item has. An Update request follows the same syntax. Similarly, to get or delete an item, simply specify a TableName and Key.
System architecture
Data structures
DynamoDB uses hashing and B-trees to manage data. Upon entry, data is first distributed into different partitions by hashing on the partition key. Each partition can store up to 10GB of data and handle by default 1,000 write capacity units (WCU) and 3,000 read capacity units (RCU).[12] One RCU represents one strongly consistent read per second or two eventually consistent reads per second for items up to 4KB in size.[11] One WCU represents one write per second for an item up to 1KB in size.
To prevent data loss, DynamoDB features a two-tier backup system of replication and long-term storage.[13] Each partition features three nodes, each of which contains a copy of that partition's data. Each node also contains two data structures: a B tree used to locate items, and a replication log that notes all changes made to the node. DynamoDB periodically takes snapshots of these two data structures and stores them for a month in S3 so that engineers can perform point-in-time restores of their databases.
Within each partition, one of the three nodes is designated the "leader node". All write operations travel first through the leader node before propagating, which makes writes consistent in DynamoDB. To maintain its status, the leader sends a "heartbeat" to each other node every 1.5 seconds. Should another node stop receiving heartbeats, it can initiate a new leader election. DynamoDB uses the Paxos algorithm to elect leaders.
Amazon engineers originally avoided Dynamo due to engineering overheads like provisioning and managing partitions and nodes.[7] In response, the DynamoDB team built a service it calls AutoAdmin to manage a database.[13] AutoAdmin replaces a node when it stops responding by copying data from another node. When a partition exceeds any of its three thresholds (RCU, WCU, or 10GB), AutoAdmin will automatically add additional partitions to further segment the data.[12]
Just like indexing systems in the relational model, DynamoDB demands that any updates to a table be reflected in each of the table's indices. DynamoDB handles this using a service it calls the "log propagator", which subscribes to the replication logs in each node and sends additional Put, Update, and Delete requests to indices as necessary.[13] Because indices result in substantial performance hits for write requests, DynamoDB allows a user at most five of them on any given table.
Query execution
Suppose that a DynamoDB user issues a write operation (a Put, Update, or Delete). While a typical relational system would convert the SQL query to relational algebra and run optimization algorithms, DynamoDB skips both processes and gets right to work.[13] The request arrives at the DynamoDB request router, which authenticates––"Is the request coming from where/whom it claims to be?"––and checks for authorization––"Does the user submitting the request have the requisite permissions?" Assuming these checks pass, the system hashes the request's partition key to arrive in the appropriate partition. There are three nodes within, each with a copy of the partition's data. The system first writes to the leader node, then writes to a second node, then sends a "success" message, and finally continues propagating to the third node. Writes are consistent because they always travel first through the leader node.
Finally, the log propagator propagates the change to all indices. For each index, it grabs that index's primary key value from the item, then performs the same write on that index without log propagation. If the operation is an Update to a preexisting item, the updated attribute may serve as a primary key for an index, and thus the B tree for that index must update as well. B trees only handle insert, delete, and read operations, so in practice, when the log propagator receives an Update operation, it issues both a Delete operation and a Put operation to all indices.
Now suppose that a DynamoDB user issues a Get operation. The request router proceeds as before with authentication and authorization. Next, as above, we hash our partition key to arrive in the appropriate hash. Now, we encounter a problem: with three nodes in eventual consistency with one another, how can we decide which to investigate? DynamoDB affords the user two options when issuing a read: consistent and eventually consistent. A consistent read visits the leader node. But the consistency-availability trade-off rears its head again here: in read-heavy systems, always reading from the leader can overwhelm a single node and reduce availability.
The second option, an eventually consistent read, selects a random node. In practice, this is where DynamoDB trades consistency for availability. If we take this route, what are the odds of an inconsistency? We'd need a write operation to return "success" and begin propagating to the third node, but not finish. We'd also need our Get to target this third node. This means a 1-in-3 chance of inconsistency within the write operation's propagation window. How long is this window? Any number of catastrophes could cause a node to fall behind, but in the vast majority of cases, the third node is up-to-date within milliseconds of the leader.
Performance
DynamoDB exposes performance metrics that help users provision it correctly and keep applications using DynamoDB running smoothly:
- Requests and throttling
- Errors: ProvisionedThroughputExceededException,ConditionalCheckFailedException,Internal Server Error(HTTP 500)
- Metrics related to Global Secondary Index creation[14]
These metrics can be tracked using the AWS Management Console, using the AWS Command Line Interface, or a monitoring tool integrating with Amazon CloudWatch.[15]
Language bindings
Languages and frameworks with a DynamoDB binding include Java, JavaScript, Node.js, Go, C# .NET, Perl, PHP, Python, Ruby, Haskell, Erlang, Django, and Grails.[16]
Code examples
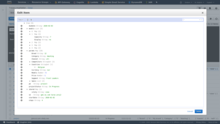
Against HTTP API, query items:
POST / HTTP/1.1
Host: dynamodb.<region>.<domain>;
Accept-Encoding: identity
Content-Length: <PayloadSizeBytes>
User-Agent: <UserAgentString>
Content-Type: application/x-amz-json-1.0
Authorization: AWS4-HMAC-SHA256 Credential=<Credential>, SignedHeaders=<Headers>, Signature=<Signature>
X-Amz-Date: <Date>
X-Amz-Target: DynamoDB_20120810.Query
{
"TableName": "Reply",
"IndexName": "PostedBy-Index",
"Limit": 3,
"ConsistentRead": true,
"ProjectionExpression": "Id, PostedBy, ReplyDateTime",
"KeyConditionExpression": "Id = :v1 AND PostedBy BETWEEN :v2a AND :v2b",
"ExpressionAttributeValues": {
":v1": {"S": "Amazon DynamoDB#DynamoDB Thread 1"},
":v2a": {"S": "User A"},
":v2b": {"S": "User C"}
},
"ReturnConsumedCapacity": "TOTAL"
}
Sample response:
HTTP/1.1 200 OK
x-amzn-RequestId: <RequestId>
x-amz-crc32: <Checksum>
Content-Type: application/x-amz-json-1.0
Content-Length: <PayloadSizeBytes>
Date: <Date>
{
"ConsumedCapacity": {
"CapacityUnits": 1,
"TableName": "Reply"
},
"Count": 2,
"Items": [
{
"ReplyDateTime": {"S": "2015-02-18T20:27:36.165Z"},
"PostedBy": {"S": "User A"},
"Id": {"S": "Amazon DynamoDB#DynamoDB Thread 1"}
},
{
"ReplyDateTime": {"S": "2015-02-25T20:27:36.165Z"},
"PostedBy": {"S": "User B"},
"Id": {"S": "Amazon DynamoDB#DynamoDB Thread 1"}
}
],
"ScannedCount": 2
}
GetItem in Go:
getItemInput := &dynamodb.GetItemInput{
TableName: aws.String("happy-marketer"),
Key: map[string]*dynamodb.AttributeValue{
"pk": {
S: aws.String("project"),
},
"sk": {
S: aws.String(email + " " + name),
},
},
}
getItemOutput, err := dynamodbClient.GetItem(getItemInput)
DeleteItem in Go:
deleteItemInput := &dynamodb.DeleteItemInput{
TableName: aws.String("happy-marketer"),
Key: map[string]*dynamodb.AttributeValue{
"pk": {
S: aws.String("project"),
},
"sk": {
S: aws.String(email + " " + name),
},
},
}
_, err := dynamodbClient.DeleteItem(deleteItemInput)
if err != nil {
panic(err)
}
UpdateItem in Go using Expression Builder:
update := expression.Set(
expression.Name(name),
expression.Value(value),
)
expr, err := expression.NewBuilder().WithUpdate(update).Build()
if err != nil {
panic(err)
}
updateItemInput := &dynamodb.UpdateItemInput{
TableName: aws.String(tableName),
Key: map[string]*dynamodb.AttributeValue{
"pk": {
S: aws.String("project"),
},
"sk": {
S: aws.String("mySortKeyValue"),
},
},
UpdateExpression: expr.Update(),
ExpressionAttributeNames: expr.Names(),
ExpressionAttributeValues: expr.Values(),
}
fmt.Printf("updateItemInput: %#v\n", updateItemInput)
_, err = dynamodbClient.UpdateItem(updateItemInput)
if err != nil {
panic(err)
}
See also
References
- "Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications - All Things Distributed". www.allthingsdistributed.com.
- "Amazon DynamoDB - FAQs". Amazon Web Services, Inc.
- Clark, Jack (2012-01-19). "Amazon switches on DynamoDB cloud database service". ZDNet. Retrieved 2012-01-21.
- "FAQs: Scalability, Availability & Durability". Amazon Web Services.
- Vogels, Werner (2012-01-18). "Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications". All Things Distributed blog. Retrieved 2012-01-21.
- "Amazon DynamoDB - FAQs". Amazon Web Services, Inc. Retrieved 2019-06-03.
- DeCandia, Giuseppe; Hastorun, Deniz; Jampani, Madan; Kakulapati, Gunavardhan; Lakshman, Avinash; Pilchin, Alex; Sivasubramanian, Swaminathan; Vosshall, Peter; Vogels, Werner (October 2007). "Dynamo: Amazon's Highly Available Key-value Store". SIGOPS Oper. Syst. Rev. 41 (6): 205–220. doi:10.1145/1323293.1294281. ISSN 0163-5980.
- "Managing Throughput Capacity Automatically with DynamoDB Auto Scaling". Amazon DynamoDB. Retrieved 2017-07-05.
- Gray, Adam (25 January 2012). "AWS HowTo: Using Amazon Elastic MapReduce with DynamoDB (Guest Post)". AWS News Blog. Retrieved 29 October 2019.
- "DynamoDB Local for Desktop Development". Amazon Web Services. 12 September 2013. Retrieved 13 September 2013.
- "Amazon DynamoDB Developer Guide". AWS. August 10, 2012. Retrieved July 18, 2019.
- Gunasekara, Archie (2016-06-27). "A Deep Dive into DynamoDB Partitions". Shine Solutions Group. Retrieved 2019-08-03.
- AWS re:Invent 2018: Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database (DAT321), retrieved 2019-08-03
- "Top DynamoDB performance metrics".
- "How to collect DynamoDB metrics".
- "Amazon DynamoDB Libraries, Mappers, and Mock Implementations Galore!". Amazon Web Services.
External links
- Official website
- Video: AWS re:Invent 2019: [REPEAT 1] Amazon DynamoDB deep dive: Advanced design patterns (DAT403-R1)
| People |
| ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Facilities | |||||||||||||||||||
| Products and services |
| ||||||||||||||||||
| Other | |||||||||||||||||||