Big data
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. Data with many cases (rows) offer greater statistical power, while data with higher complexity (more attributes or columns) may lead to a higher false discovery rate.[2] Big data challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy and data source. Big data was originally associated with three key concepts: volume, variety, and velocity. When we handle big data, we may not sample but simply observe and track what happens. Therefore, big data often includes data with sizes that exceed the capacity of traditional software to process within an acceptable time and value.
Current usage of the term big data tends to refer to the use of predictive analytics, user behavior analytics, or certain other advanced data analytics methods that extract value from data, and seldom to a particular size of data set. "There is little doubt that the quantities of data now available are indeed large, but that's not the most relevant characteristic of this new data ecosystem."[3] Analysis of data sets can find new correlations to "spot business trends, prevent diseases, combat crime and so on."[4] Scientists, business executives, practitioners of medicine, advertising and governments alike regularly meet difficulties with large data-sets in areas including Internet searches, fintech, urban informatics, and business informatics. Scientists encounter limitations in e-Science work, including meteorology, genomics,[5] connectomics, complex physics simulations, biology and environmental research.[6]
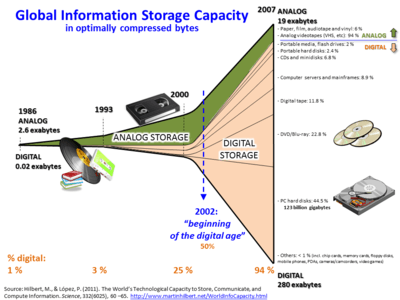
Data sets grow rapidly, to a certain extent because they are increasingly gathered by cheap and numerous information-sensing Internet of things devices such as mobile devices, aerial (remote sensing), software logs, cameras, microphones, radio-frequency identification (RFID) readers and wireless sensor networks.[7][8] The world's technological per-capita capacity to store information has roughly doubled every 40 months since the 1980s;[9] as of 2012, every day 2.5 exabytes (2.5×260 bytes) of data are generated.[10] Based on an IDC report prediction, the global data volume was predicted to grow exponentially from 4.4 zettabytes to 44 zettabytes between 2013 and 2020. By 2025, IDC predicts there will be 163 zettabytes of data.[11] One question for large enterprises is determining who should own big-data initiatives that affect the entire organization.[12]
Relational database management systems, desktop statistics and software packages used to visualize data often have difficulty handling big data. The work may require "massively parallel software running on tens, hundreds, or even thousands of servers".[13] What qualifies as being "big data" varies depending on the capabilities of the users and their tools, and expanding capabilities make big data a moving target. "For some organizations, facing hundreds of gigabytes of data for the first time may trigger a need to reconsider data management options. For others, it may take tens or hundreds of terabytes before data size becomes a significant consideration."[14]
Definition
The term has been in use since the 1990s, with some giving credit to John Mashey for popularizing the term.[15][16] Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time.[17] Big data philosophy encompasses unstructured, semi-structured and structured data, however the main focus is on unstructured data.[18] Big data "size" is a constantly moving target, as of 2012 ranging from a few dozen terabytes to many zettabytes of data.[19] Big data requires a set of techniques and technologies with new forms of integration to reveal insights from data-sets that are diverse, complex, and of a massive scale.[20]
"Variety", "veracity" and various other "Vs" are added by some organizations to describe it, a revision challenged by some industry authorities.[21]
A 2018 definition states "Big data is where parallel computing tools are needed to handle data", and notes, "This represents a distinct and clearly defined change in the computer science used, via parallel programming theories, and losses of some of the guarantees and capabilities made by Codd's relational model."[22]
The growing maturity of the concept more starkly delineates the difference between "big data" and "Business Intelligence":[23]
- Business Intelligence uses applied mathematics tools and descriptive statistics with data with high information density to measure things, detect trends, etc.
- Big data uses mathematical analysis, optimization, inductive statistics and concepts from nonlinear system identification[24] to infer laws (regressions, nonlinear relationships, and causal effects) from large sets of data with low information density[25] to reveal relationships and dependencies, or to perform predictions of outcomes and behaviors.[24][26]
Characteristics
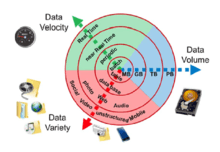
Big data can be described by the following characteristics:
- Volume
- The quantity of generated and stored data. The size of the data determines the value and potential insight, and whether it can be considered big data or not.
- Variety
- The type and nature of the data. This helps people who analyze it to effectively use the resulting insight. Big data draws from text, images, audio, video; plus it completes missing pieces through data fusion.
- Velocity
- The speed at which the data is generated and processed to meet the demands and challenges that lie in the path of growth and development. Big data is often available in real-time. Compared to small data, big data are produced more continually. Two kinds of velocity related to big data are the frequency of generation and the frequency of handling, recording, and publishing.[27]
- Veracity
- It is the extended definition for big data, which refers to the data quality and the data value.[28] The data quality of captured data can vary greatly, affecting the accurate analysis.[29]
Other important characteristics of Big Data are:[30]
- Exhaustive
- Whether the entire system (i.e., =all) is captured or recorded or not.

- Fine-grained and uniquely lexical
- Respectively, the proportion of specific data of each element per element collected and if the element and its characteristics are properly indexed or identified.
- Relational
- If the data collected contains common fields that would enable a conjoining, or meta-analysis, of different data sets.
- Extensional
- If new fields in each element of the data collected can be added or changed easily.
- Scalability
- If the size of the data can expand rapidly.
- Value
- The utility that can be extracted from the data.
- Variability
- It refers to data whose value or other characteristics are shifting in relation to the context in which they are being generated.
Architecture
Big data repositories have existed in many forms, often built by corporations with a special need. Commercial vendors historically offered parallel database management systems for big data beginning in the 1990s. For many years, WinterCorp published the largest database report.[31]
Teradata Corporation in 1984 marketed the parallel processing DBC 1012 system. Teradata systems were the first to store and analyze 1 terabyte of data in 1992. Hard disk drives were 2.5 GB in 1991 so the definition of big data continuously evolves according to Kryder's Law. Teradata installed the first petabyte class RDBMS based system in 2007. As of 2017, there are a few dozen petabyte class Teradata relational databases installed, the largest of which exceeds 50 PB. Systems up until 2008 were 100% structured relational data. Since then, Teradata has added unstructured data types including XML, JSON, and Avro.
In 2000, Seisint Inc. (now LexisNexis Risk Solutions) developed a C++-based distributed platform for data processing and querying known as the HPCC Systems platform. This system automatically partitions, distributes, stores and delivers structured, semi-structured, and unstructured data across multiple commodity servers. Users can write data processing pipelines and queries in a declarative dataflow programming language called ECL. Data analysts working in ECL are not required to define data schemas upfront and can rather focus on the particular problem at hand, reshaping data in the best possible manner as they develop the solution. In 2004, LexisNexis acquired Seisint Inc.[32] and their high-speed parallel processing platform and successfully utilized this platform to integrate the data systems of Choicepoint Inc. when they acquired that company in 2008.[33] In 2011, the HPCC systems platform was open-sourced under the Apache v2.0 License.
CERN and other physics experiments have collected big data sets for many decades, usually analyzed via high-throughput computing rather than the map-reduce architectures usually meant by the current "big data" movement.
In 2004, Google published a paper on a process called MapReduce that uses a similar architecture. The MapReduce concept provides a parallel processing model, and an associated implementation was released to process huge amounts of data. With MapReduce, queries are split and distributed across parallel nodes and processed in parallel (the Map step). The results are then gathered and delivered (the Reduce step). The framework was very successful,[34] so others wanted to replicate the algorithm. Therefore, an implementation of the MapReduce framework was adopted by an Apache open-source project named Hadoop.[35] Apache Spark was developed in 2012 in response to limitations in the MapReduce paradigm, as it adds the ability to set up many operations (not just map followed by reducing).
MIKE2.0 is an open approach to information management that acknowledges the need for revisions due to big data implications identified in an article titled "Big Data Solution Offering".[36] The methodology addresses handling big data in terms of useful permutations of data sources, complexity in interrelationships, and difficulty in deleting (or modifying) individual records.[37]
2012 studies showed that a multiple-layer architecture is one option to address the issues that big data presents. A distributed parallel architecture distributes data across multiple servers; these parallel execution environments can dramatically improve data processing speeds. This type of architecture inserts data into a parallel DBMS, which implements the use of MapReduce and Hadoop frameworks. This type of framework looks to make the processing power transparent to the end-user by using a front-end application server.[38]
The data lake allows an organization to shift its focus from centralized control to a shared model to respond to the changing dynamics of information management. This enables quick segregation of data into the data lake, thereby reducing the overhead time.[39][40]
Technologies
A 2011 McKinsey Global Institute report characterizes the main components and ecosystem of big data as follows:[41]
- Techniques for analyzing data, such as A/B testing, machine learning and natural language processing
- Big data technologies, like business intelligence, cloud computing and databases
- Visualization, such as charts, graphs and other displays of the data
Multidimensional big data can also be represented as OLAP data cubes or, mathematically, tensors. Array Database Systems have set out to provide storage and high-level query support on this data type. Additional technologies being applied to big data include efficient tensor-based computation,[42] such as multilinear subspace learning.,[43] massively parallel-processing (MPP) databases, search-based applications, data mining,[44] distributed file systems, distributed cache (e.g., burst buffer and Memcached), distributed databases, cloud and HPC-based infrastructure (applications, storage and computing resources)[45] and the Internet. Although, many approaches and technologies have been developed, it still remains difficult to carry out machine learning with big data.[46]
Some MPP relational databases have the ability to store and manage petabytes of data. Implicit is the ability to load, monitor, back up, and optimize the use of the large data tables in the RDBMS.[47]
DARPA's Topological Data Analysis program seeks the fundamental structure of massive data sets and in 2008 the technology went public with the launch of a company called Ayasdi.[48]
The practitioners of big data analytics processes are generally hostile to slower shared storage,[49] preferring direct-attached storage (DAS) in its various forms from solid state drive (SSD) to high capacity SATA disk buried inside parallel processing nodes. The perception of shared storage architectures—Storage area network (SAN) and Network-attached storage (NAS) —is that they are relatively slow, complex, and expensive. These qualities are not consistent with big data analytics systems that thrive on system performance, commodity infrastructure, and low cost.
Real or near-real time information delivery is one of the defining characteristics of big data analytics. Latency is therefore avoided whenever and wherever possible. Data in direct-attached memory or disk is good—data on memory or disk at the other end of a FC SAN connection is not. The cost of a SAN at the scale needed for analytics applications is very much higher than other storage techniques.
There are advantages as well as disadvantages to shared storage in big data analytics, but big data analytics practitioners as of 2011 did not favour it.[50]
Applications
.jpg)
Big data has increased the demand of information management specialists so much so that Software AG, Oracle Corporation, IBM, Microsoft, SAP, EMC, HP and Dell have spent more than $15 billion on software firms specializing in data management and analytics. In 2010, this industry was worth more than $100 billion and was growing at almost 10 percent a year: about twice as fast as the software business as a whole.[4]
Developed economies increasingly use data-intensive technologies. There are 4.6 billion mobile-phone subscriptions worldwide, and between 1 billion and 2 billion people accessing the internet.[4] Between 1990 and 2005, more than 1 billion people worldwide entered the middle class, which means more people became more literate, which in turn led to information growth. The world's effective capacity to exchange information through telecommunication networks was 281 petabytes in 1986, 471 petabytes in 1993, 2.2 exabytes in 2000, 65 exabytes in 2007[9] and predictions put the amount of internet traffic at 667 exabytes annually by 2014.[4] According to one estimate, one-third of the globally stored information is in the form of alphanumeric text and still image data,[51] which is the format most useful for most big data applications. This also shows the potential of yet unused data (i.e. in the form of video and audio content).
While many vendors offer off-the-shelf solutions for big data, experts recommend the development of in-house solutions custom-tailored to solve the company's problem at hand if the company has sufficient technical capabilities.[52]
Government
The use and adoption of big data within governmental processes allows efficiencies in terms of cost, productivity, and innovation,[53] but does not come without its flaws. Data analysis often requires multiple parts of government (central and local) to work in collaboration and create new and innovative processes to deliver the desired outcome.
CRVS (civil registration and vital statistics) collects all certificates status from birth to death. CRVS is a source of big data for governments.
International development
Research on the effective usage of information and communication technologies for development (also known as ICT4D) suggests that big data technology can make important contributions but also present unique challenges to International development.[54][55] Advancements in big data analysis offer cost-effective opportunities to improve decision-making in critical development areas such as health care, employment, economic productivity, crime, security, and natural disaster and resource management.[56][57][58] Additionally, user-generated data offers new opportunities to give the unheard a voice.[59] However, longstanding challenges for developing regions such as inadequate technological infrastructure and economic and human resource scarcity exacerbate existing concerns with big data such as privacy, imperfect methodology, and interoperability issues.[56]
Healthcare
Big data analytics has helped healthcare improve by providing personalized medicine and prescriptive analytics, clinical risk intervention and predictive analytics, waste and care variability reduction, automated external and internal reporting of patient data, standardized medical terms and patient registries and fragmented point solutions.[60][61][62][63] Some areas of improvement are more aspirational than actually implemented. The level of data generated within healthcare systems is not trivial. With the added adoption of mHealth, eHealth and wearable technologies the volume of data will continue to increase. This includes electronic health record data, imaging data, patient generated data, sensor data, and other forms of difficult to process data. There is now an even greater need for such environments to pay greater attention to data and information quality.[64] "Big data very often means 'dirty data' and the fraction of data inaccuracies increases with data volume growth." Human inspection at the big data scale is impossible and there is a desperate need in health service for intelligent tools for accuracy and believability control and handling of information missed.[65] While extensive information in healthcare is now electronic, it fits under the big data umbrella as most is unstructured and difficult to use.[66] The use of big data in healthcare has raised significant ethical challenges ranging from risks for individual rights, privacy and autonomy, to transparency and trust.[67]
Big data in health research is particularly promising in terms of exploratory biomedical research, as data-driven analysis can move forward more quickly than hypothesis-driven research.[68] Then, trends seen in data analysis can be tested in traditional, hypothesis-driven followup biological research and eventually clinical research.
A related application sub-area, that heavily relies on big data, within the healthcare field is that of computer-aided diagnosis in medicine. [69] One only needs to recall that, for instance, for epilepsy monitoring it is customary to create 5 to 10 GB of data daily. [70] Similarly, a single uncompressed image of breast tomosynthesis averages 450 MB of data. [71] These are just few of the many examples where computer-aided diagnosis uses big data. For this reason, big data has been recognized as one of the seven key challenges that computer-aided diagnosis systems need to overcome in order to reach the next level of performance. [72]
Education
A McKinsey Global Institute study found a shortage of 1.5 million highly trained data professionals and managers[41] and a number of universities[73] including University of Tennessee and UC Berkeley, have created masters programs to meet this demand. Private boot camps have also developed programs to meet that demand, including free programs like The Data Incubator or paid programs like General Assembly.[74] In the specific field of marketing, one of the problems stressed by Wedel and Kannan[75] is that marketing has several sub domains (e.g., advertising, promotions, product development, branding) that all use different types of data. Because one-size-fits-all analytical solutions are not desirable, business schools should prepare marketing managers to have wide knowledge on all the different techniques used in these sub domains to get a big picture and work effectively with analysts.
Media
To understand how the media utilizes big data, it is first necessary to provide some context into the mechanism used for media process. It has been suggested by Nick Couldry and Joseph Turow that practitioners in Media and Advertising approach big data as many actionable points of information about millions of individuals. The industry appears to be moving away from the traditional approach of using specific media environments such as newspapers, magazines, or television shows and instead taps into consumers with technologies that reach targeted people at optimal times in optimal locations. The ultimate aim is to serve or convey, a message or content that is (statistically speaking) in line with the consumer's mindset. For example, publishing environments are increasingly tailoring messages (advertisements) and content (articles) to appeal to consumers that have been exclusively gleaned through various data-mining activities.[76]
- Targeting of consumers (for advertising by marketers)[77]
- Data capture
- Data journalism: publishers and journalists use big data tools to provide unique and innovative insights and infographics.
Channel 4, the British public-service television broadcaster, is a leader in the field of big data and data analysis.[78]
Insurance
Health insurance providers are collecting data on social "determinants of health" such as food and TV consumption, marital status, clothing size and purchasing habits, from which they make predictions on health costs, in order to spot health issues in their clients. It is controversial whether these predictions are currently being used for pricing.[79]
Internet of Things (IoT)
Big data and the IoT work in conjunction. Data extracted from IoT devices provides a mapping of device inter-connectivity. Such mappings have been used by the media industry, companies and governments to more accurately target their audience and increase media efficiency. IoT is also increasingly adopted as a means of gathering sensory data, and this sensory data has been used in medical,[80] manufacturing[81] and transportation[82] contexts.
Kevin Ashton, digital innovation expert who is credited with coining the term,[83] defines the Internet of Things in this quote: “If we had computers that knew everything there was to know about things—using data they gathered without any help from us—we would be able to track and count everything, and greatly reduce waste, loss, and cost. We would know when things needed replacing, repairing or recalling, and whether they were fresh or past their best.”
Information technology
Especially since 2015, big data has come to prominence within business operations as a tool to help employees work more efficiently and streamline the collection and distribution of information technology (IT). The use of big data to resolve IT and data collection issues within an enterprise is called IT operations analytics (ITOA).[84] By applying big data principles into the concepts of machine intelligence and deep computing, IT departments can predict potential issues and move to provide solutions before the problems even happen.[84] In this time, ITOA businesses were also beginning to play a major role in systems management by offering platforms that brought individual data silos together and generated insights from the whole of the system rather than from isolated pockets of data.
Case studies
Government
China
- The Integrated Joint Operations Platform (IJOP, 一体化联合作战平台) is used by the government to monitor the population, particularly Uyghurs.[85] Biometrics, including DNA samples, are gathered through a program of free physicals.[86]
- By 2020, China plans to give all its citizens a personal "Social Credit" score based on how they behave.[87] The Social Credit System, now being piloted in a number of Chinese cities, is considered a form of mass surveillance which uses big data analysis technology.[88][89]
India
- Big data analysis was tried out for the BJP to win the Indian General Election 2014.[90]
- The Indian government utilizes numerous techniques to ascertain how the Indian electorate is responding to government action, as well as ideas for policy augmentation.
Israel
- Personalized diabetic treatments can be created through GlucoMe's big data solution.[91]
United Kingdom
Examples of uses of big data in public services:
- Data on prescription drugs: by connecting origin, location and the time of each prescription, a research unit was able to exemplify the considerable delay between the release of any given drug, and a UK-wide adaptation of the National Institute for Health and Care Excellence guidelines. This suggests that new or most up-to-date drugs take some time to filter through to the general patient.[92]
- Joining up data: a local authority blended data about services, such as road gritting rotas, with services for people at risk, such as 'meals on wheels'. The connection of data allowed the local authority to avoid any weather-related delay.[93]
United States of America
- In 2012, the Obama administration announced the Big Data Research and Development Initiative, to explore how big data could be used to address important problems faced by the government.[94] The initiative is composed of 84 different big data programs spread across six departments.[95]
- Big data analysis played a large role in Barack Obama's successful 2012 re-election campaign.[96]
- The United States Federal Government owns five of the ten most powerful supercomputers in the world.[97][98]
- The Utah Data Center has been constructed by the United States National Security Agency. When finished, the facility will be able to handle a large amount of information collected by the NSA over the Internet. The exact amount of storage space is unknown, but more recent sources claim it will be on the order of a few exabytes.[99][100][101] This has posed security concerns regarding the anonymity of the data collected.[102]
Retail
- Walmart handles more than 1 million customer transactions every hour, which are imported into databases estimated to contain more than 2.5 petabytes (2560 terabytes) of data—the equivalent of 167 times the information contained in all the books in the US Library of Congress.[4]
- Windermere Real Estate uses location information from nearly 100 million drivers to help new home buyers determine their typical drive times to and from work throughout various times of the day.[103]
- FICO Card Detection System protects accounts worldwide.[104]
Science
- The Large Hadron Collider experiments represent about 150 million sensors delivering data 40 million times per second. There are nearly 600 million collisions per second. After filtering and refraining from recording more than 99.99995%[105] of these streams, there are 1,000 collisions of interest per second.[106][107][108]
- As a result, only working with less than 0.001% of the sensor stream data, the data flow from all four LHC experiments represents 25 petabytes annual rate before replication (as of 2012). This becomes nearly 200 petabytes after replication.
- If all sensor data were recorded in LHC, the data flow would be extremely hard to work with. The data flow would exceed 150 million petabytes annual rate, or nearly 500 exabytes per day, before replication. To put the number in perspective, this is equivalent to 500 quintillion (5×1020) bytes per day, almost 200 times more than all the other sources combined in the world.
- The Square Kilometre Array is a radio telescope built of thousands of antennas. It is expected to be operational by 2024. Collectively, these antennas are expected to gather 14 exabytes and store one petabyte per day.[109][110] It is considered one of the most ambitious scientific projects ever undertaken.[111]
- When the Sloan Digital Sky Survey (SDSS) began to collect astronomical data in 2000, it amassed more in its first few weeks than all data collected in the history of astronomy previously. Continuing at a rate of about 200 GB per night, SDSS has amassed more than 140 terabytes of information.[4] When the Large Synoptic Survey Telescope, successor to SDSS, comes online in 2020, its designers expect it to acquire that amount of data every five days.[4]
- Decoding the human genome originally took 10 years to process; now it can be achieved in less than a day. The DNA sequencers have divided the sequencing cost by 10,000 in the last ten years, which is 100 times cheaper than the reduction in cost predicted by Moore's Law.[112]
- The NASA Center for Climate Simulation (NCCS) stores 32 petabytes of climate observations and simulations on the Discover supercomputing cluster.[113][114]
- Google's DNAStack compiles and organizes DNA samples of genetic data from around the world to identify diseases and other medical defects. These fast and exact calculations eliminate any 'friction points,' or human errors that could be made by one of the numerous science and biology experts working with the DNA. DNAStack, a part of Google Genomics, allows scientists to use the vast sample of resources from Google's search server to scale social experiments that would usually take years, instantly.[115][116]
- 23andme's DNA database contains genetic information of over 1,000,000 people worldwide.[117] The company explores selling the "anonymous aggregated genetic data" to other researchers and pharmaceutical companies for research purposes if patients give their consent.[118][119][120][121][122] Ahmad Hariri, professor of psychology and neuroscience at Duke University who has been using 23andMe in his research since 2009 states that the most important aspect of the company's new service is that it makes genetic research accessible and relatively cheap for scientists.[118] A study that identified 15 genome sites linked to depression in 23andMe's database lead to a surge in demands to access the repository with 23andMe fielding nearly 20 requests to access the depression data in the two weeks after publication of the paper.[123]
- Computational Fluid Dynamics (CFD) and hydrodynamic turbulence research generate massive data sets. The Johns Hopkins Turbulence Databases (JHTDB) contains over 350 terabytes of spatiotemporal fields from Direct Numerical simulations of various turbulent flows. Such data have been difficult to share using traditional methods such as downloading flat simulation output files. The data within JHTDB can be accessed using "virtual sensors" with various access modes ranging from direct web-browser queries, access through Matlab, Python, Fortran and C programs executing on clients' platforms, to cut out services to download raw data. The data have been used in over 150 scientific publications.
Sports
Big data can be used to improve training and understanding competitors, using sport sensors. It is also possible to predict winners in a match using big data analytics.[124] Future performance of players could be predicted as well. Thus, players' value and salary is determined by data collected throughout the season.[125]
In Formula One races, race cars with hundreds of sensors generate terabytes of data. These sensors collect data points from tire pressure to fuel burn efficiency.[126] Based on the data, engineers and data analysts decide whether adjustments should be made in order to win a race. Besides, using big data, race teams try to predict the time they will finish the race beforehand, based on simulations using data collected over the season.[127]
Technology
- eBay.com uses two data warehouses at 7.5 petabytes and 40PB as well as a 40PB Hadoop cluster for search, consumer recommendations, and merchandising.[128]
- Amazon.com handles millions of back-end operations every day, as well as queries from more than half a million third-party sellers. The core technology that keeps Amazon running is Linux-based and as of 2005 they had the world's three largest Linux databases, with capacities of 7.8 TB, 18.5 TB, and 24.7 TB.[129]
- Facebook handles 50 billion photos from its user base.[130] As of June 2017, Facebook reached 2 billion monthly active users.[131]
- Google was handling roughly 100 billion searches per month as of August 2012.[132]
Research activities
Encrypted search and cluster formation in big data were demonstrated in March 2014 at the American Society of Engineering Education. Gautam Siwach engaged at Tackling the challenges of Big Data by MIT Computer Science and Artificial Intelligence Laboratory and Dr. Amir Esmailpour at UNH Research Group investigated the key features of big data as the formation of clusters and their interconnections. They focused on the security of big data and the orientation of the term towards the presence of different types of data in an encrypted form at cloud interface by providing the raw definitions and real-time examples within the technology. Moreover, they proposed an approach for identifying the encoding technique to advance towards an expedited search over encrypted text leading to the security enhancements in big data.[133]
In March 2012, The White House announced a national "Big Data Initiative" that consisted of six Federal departments and agencies committing more than $200 million to big data research projects.[134]
The initiative included a National Science Foundation "Expeditions in Computing" grant of $10 million over 5 years to the AMPLab[135] at the University of California, Berkeley.[136] The AMPLab also received funds from DARPA, and over a dozen industrial sponsors and uses big data to attack a wide range of problems from predicting traffic congestion[137] to fighting cancer.[138]
The White House Big Data Initiative also included a commitment by the Department of Energy to provide $25 million in funding over 5 years to establish the scalable Data Management, Analysis and Visualization (SDAV) Institute,[139] led by the Energy Department's Lawrence Berkeley National Laboratory. The SDAV Institute aims to bring together the expertise of six national laboratories and seven universities to develop new tools to help scientists manage and visualize data on the Department's supercomputers.
The U.S. state of Massachusetts announced the Massachusetts Big Data Initiative in May 2012, which provides funding from the state government and private companies to a variety of research institutions.[140] The Massachusetts Institute of Technology hosts the Intel Science and Technology Center for Big Data in the MIT Computer Science and Artificial Intelligence Laboratory, combining government, corporate, and institutional funding and research efforts.[141]
The European Commission is funding the 2-year-long Big Data Public Private Forum through their Seventh Framework Program to engage companies, academics and other stakeholders in discussing big data issues. The project aims to define a strategy in terms of research and innovation to guide supporting actions from the European Commission in the successful implementation of the big data economy. Outcomes of this project will be used as input for Horizon 2020, their next framework program.[142]
The British government announced in March 2014 the founding of the Alan Turing Institute, named after the computer pioneer and code-breaker, which will focus on new ways to collect and analyze large data sets.[143]
At the University of Waterloo Stratford Campus Canadian Open Data Experience (CODE) Inspiration Day, participants demonstrated how using data visualization can increase the understanding and appeal of big data sets and communicate their story to the world.[144]
Computational social sciences – Anyone can use Application Programming Interfaces (APIs) provided by big data holders, such as Google and Twitter, to do research in the social and behavioral sciences.[145] Often these APIs are provided for free.[145] Tobias Preis et al. used Google Trends data to demonstrate that Internet users from countries with a higher per capita gross domestic product (GDP) are more likely to search for information about the future than information about the past. The findings suggest there may be a link between online behaviour and real-world economic indicators.[146][147][148] The authors of the study examined Google queries logs made by ratio of the volume of searches for the coming year ('2011') to the volume of searches for the previous year ('2009'), which they call the 'future orientation index'.[149] They compared the future orientation index to the per capita GDP of each country, and found a strong tendency for countries where Google users inquire more about the future to have a higher GDP. The results hint that there may potentially be a relationship between the economic success of a country and the information-seeking behavior of its citizens captured in big data.
Tobias Preis and his colleagues Helen Susannah Moat and H. Eugene Stanley introduced a method to identify online precursors for stock market moves, using trading strategies based on search volume data provided by Google Trends.[150] Their analysis of Google search volume for 98 terms of varying financial relevance, published in Scientific Reports,[151] suggests that increases in search volume for financially relevant search terms tend to precede large losses in financial markets.[152][153][154][155][156][157][158]
Big data sets come with algorithmic challenges that previously did not exist. Hence, there is a need to fundamentally change the processing ways.[159]
The Workshops on Algorithms for Modern Massive Data Sets (MMDS) bring together computer scientists, statisticians, mathematicians, and data analysis practitioners to discuss algorithmic challenges of big data.[160] Regarding big data, one needs to keep in mind that such concepts of magnitude are relative. As it is stated "If the past is of any guidance, then today’s big data most likely will not be considered as such in the near future."[69]
Sampling big data
An important research question that can be asked about big data sets is whether you need to look at the full data to draw certain conclusions about the properties of the data or is a sample good enough. The name big data itself contains a term related to size and this is an important characteristic of big data. But Sampling (statistics) enables the selection of right data points from within the larger data set to estimate the characteristics of the whole population. For example, there are about 600 million tweets produced every day. Is it necessary to look at all of them to determine the topics that are discussed during the day? Is it necessary to look at all the tweets to determine the sentiment on each of the topics? In manufacturing different types of sensory data such as acoustics, vibration, pressure, current, voltage and controller data are available at short time intervals. To predict downtime it may not be necessary to look at all the data but a sample may be sufficient. Big Data can be broken down by various data point categories such as demographic, psychographic, behavioral, and transactional data. With large sets of data points, marketers are able to create and utilize more customized segments of consumers for more strategic targeting.
There has been some work done in Sampling algorithms for big data. A theoretical formulation for sampling Twitter data has been developed.[161]
Critique
Critiques of the big data paradigm come in two flavors: those that question the implications of the approach itself, and those that question the way it is currently done.[162] One approach to this criticism is the field of critical data studies.
Critiques of the big data paradigm
"A crucial problem is that we do not know much about the underlying empirical micro-processes that lead to the emergence of the[se] typical network characteristics of Big Data".[17] In their critique, Snijders, Matzat, and Reips point out that often very strong assumptions are made about mathematical properties that may not at all reflect what is really going on at the level of micro-processes. Mark Graham has leveled broad critiques at Chris Anderson's assertion that big data will spell the end of theory:[163] focusing in particular on the notion that big data must always be contextualized in their social, economic, and political contexts.[164] Even as companies invest eight- and nine-figure sums to derive insight from information streaming in from suppliers and customers, less than 40% of employees have sufficiently mature processes and skills to do so. To overcome this insight deficit, big data, no matter how comprehensive or well analyzed, must be complemented by "big judgment," according to an article in the Harvard Business Review.[165]
Much in the same line, it has been pointed out that the decisions based on the analysis of big data are inevitably "informed by the world as it was in the past, or, at best, as it currently is".[56] Fed by a large number of data on past experiences, algorithms can predict future development if the future is similar to the past.[166] If the system's dynamics of the future change (if it is not a stationary process), the past can say little about the future. In order to make predictions in changing environments, it would be necessary to have a thorough understanding of the systems dynamic, which requires theory.[166] As a response to this critique Alemany Oliver and Vayre suggest to use "abductive reasoning as a first step in the research process in order to bring context to consumers' digital traces and make new theories emerge".[167] Additionally, it has been suggested to combine big data approaches with computer simulations, such as agent-based models[56] and complex systems. Agent-based models are increasingly getting better in predicting the outcome of social complexities of even unknown future scenarios through computer simulations that are based on a collection of mutually interdependent algorithms.[168][169] Finally, the use of multivariate methods that probe for the latent structure of the data, such as factor analysis and cluster analysis, have proven useful as analytic approaches that go well beyond the bi-variate approaches (cross-tabs) typically employed with smaller data sets.
In health and biology, conventional scientific approaches are based on experimentation. For these approaches, the limiting factor is the relevant data that can confirm or refute the initial hypothesis.[170] A new postulate is accepted now in biosciences: the information provided by the data in huge volumes (omics) without prior hypothesis is complementary and sometimes necessary to conventional approaches based on experimentation.[171][172] In the massive approaches it is the formulation of a relevant hypothesis to explain the data that is the limiting factor.[173] The search logic is reversed and the limits of induction ("Glory of Science and Philosophy scandal", C. D. Broad, 1926) are to be considered.
Privacy advocates are concerned about the threat to privacy represented by increasing storage and integration of personally identifiable information; expert panels have released various policy recommendations to conform practice to expectations of privacy.[174][175][176] The misuse of Big Data in several cases by media, companies and even the government has allowed for abolition of trust in almost every fundamental institution holding up society.[177]
Nayef Al-Rodhan argues that a new kind of social contract will be needed to protect individual liberties in a context of Big Data and giant corporations that own vast amounts of information. The use of Big Data should be monitored and better regulated at the national and international levels.[178] Barocas and Nissenbaum argue that one way of protecting individual users is by being informed about the types of information being collected, with whom it is shared, under what constrains and for what purposes.[179]
Critiques of the 'V' model
The 'V' model of Big Data is concerting as it centres around computational scalability and lacks in a loss around the perceptibility and understandability of information. This led to the framework of cognitive big data, which characterizes Big Data application according to:[180]
- Data completeness: understanding of the non-obvious from data;
- Data correlation, causation, and predictability: causality as not essential requirement to achieve predictability;
- Explainability and interpretability: humans desire to understand and accept what they understand, where algorithms don't cope with this;
- Level of automated decision making: algorithms that support automated decision making and algorithmic self-learning;
Critiques of novelty
Large data sets have been analyzed by computing machines for well over a century, including the US census analytics performed by IBM's punch-card machines which computed statistics including means and variances of populations across the whole continent. In more recent decades, science experiments such as CERN have produced data on similar scales to current commercial "big data". However, science experiments have tended to analyze their data using specialized custom-built high-performance computing (super-computing) clusters and grids, rather than clouds of cheap commodity computers as in the current commercial wave, implying a difference in both culture and technology stack.
Critiques of big data execution
Ulf-Dietrich Reips and Uwe Matzat wrote in 2014 that big data had become a "fad" in scientific research.[145] Researcher Danah Boyd has raised concerns about the use of big data in science neglecting principles such as choosing a representative sample by being too concerned about handling the huge amounts of data.[181] This approach may lead to results bias in one way or another. Integration across heterogeneous data resources—some that might be considered big data and others not—presents formidable logistical as well as analytical challenges, but many researchers argue that such integrations are likely to represent the most promising new frontiers in science.[182] In the provocative article "Critical Questions for Big Data",[183] the authors title big data a part of mythology: "large data sets offer a higher form of intelligence and knowledge [...], with the aura of truth, objectivity, and accuracy". Users of big data are often "lost in the sheer volume of numbers", and "working with Big Data is still subjective, and what it quantifies does not necessarily have a closer claim on objective truth".[183] Recent developments in BI domain, such as pro-active reporting especially target improvements in usability of big data, through automated filtering of non-useful data and correlations.[184] Big structures are full of spurious correlations[185] either because of non-causal coincidences (law of truly large numbers), solely nature of big randomness[186] (Ramsey theory) or existence of non-included factors so the hope, of early experimenters to make large databases of numbers "speak for themselves" and revolutionize scientific method, is questioned.[187]
Big data analysis is often shallow compared to analysis of smaller data sets.[188] In many big data projects, there is no large data analysis happening, but the challenge is the extract, transform, load part of data pre-processing.[188]
Big data is a buzzword and a "vague term",[189][190] but at the same time an "obsession"[190] with entrepreneurs, consultants, scientists and the media. Big data showcases such as Google Flu Trends failed to deliver good predictions in recent years, overstating the flu outbreaks by a factor of two. Similarly, Academy awards and election predictions solely based on Twitter were more often off than on target. Big data often poses the same challenges as small data; adding more data does not solve problems of bias, but may emphasize other problems. In particular data sources such as Twitter are not representative of the overall population, and results drawn from such sources may then lead to wrong conclusions. Google Translate—which is based on big data statistical analysis of text—does a good job at translating web pages. However, results from specialized domains may be dramatically skewed. On the other hand, big data may also introduce new problems, such as the multiple comparisons problem: simultaneously testing a large set of hypotheses is likely to produce many false results that mistakenly appear significant. Ioannidis argued that "most published research findings are false"[191] due to essentially the same effect: when many scientific teams and researchers each perform many experiments (i.e. process a big amount of scientific data; although not with big data technology), the likelihood of a "significant" result being false grows fast – even more so, when only positive results are published. Furthermore, big data analytics results are only as good as the model on which they are predicated. In an example, big data took part in attempting to predict the results of the 2016 U.S. Presidential Election[192] with varying degrees of success.
Critiques of big data policing and surveillance
Big Data has been used in policing and surveillance by institutions like law enforcement and corporations.[193] Due to the less visible nature of data-based surveillance as compared to traditional method of policing, objections to big data policing are less likely to arise. According to Sarah Brayne's Big Data Surveillance: The Case of Policing,[194] big data policing can reproduce existing societal inequalities in three ways:
- Placing suspected criminals under increased surveillance by using the justification of a mathematical and therefore unbiased algorithm;
- Increasing the scope and number of people that are subject to law enforcement tracking and exacerbating existing racial overrepresentation in the criminal justice system;
- Encouraging members of society to abandon interactions with institutions that would create a digital trace, thus creating obstacles to social inclusion.
If these potential problems are not corrected or regulating, the effects of big data policing continue to shape societal hierarchies. Conscientious usage of big data policing could prevent individual level biases from becoming institutional biases, Brayne also notes.
See also
References
- Hilbert, Martin; López, Priscila (2011). "The World's Technological Capacity to Store, Communicate, and Compute Information". Science. 332 (6025): 60–65. Bibcode:2011Sci...332...60H. doi:10.1126/science.1200970. PMID 21310967. Retrieved 13 April 2016.
- Breur, Tom (July 2016). "Statistical Power Analysis and the contemporary "crisis" in social sciences". Journal of Marketing Analytics. 4 (2–3): 61–65. doi:10.1057/s41270-016-0001-3. ISSN 2050-3318.
- boyd, dana; Crawford, Kate (21 September 2011). "Six Provocations for Big Data". Social Science Research Network: A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society. doi:10.2139/ssrn.1926431.
- "Data, data everywhere". The Economist. 25 February 2010. Retrieved 9 December 2012.
- "Community cleverness required". Nature. 455 (7209): 1. September 2008. Bibcode:2008Natur.455....1.. doi:10.1038/455001a. PMID 18769385.
- Reichman OJ, Jones MB, Schildhauer MP (February 2011). "Challenges and opportunities of open data in ecology". Science. 331 (6018): 703–5. Bibcode:2011Sci...331..703R. doi:10.1126/science.1197962. PMID 21311007.
- Hellerstein, Joe (9 November 2008). "Parallel Programming in the Age of Big Data". Gigaom Blog.
- Segaran, Toby; Hammerbacher, Jeff (2009). Beautiful Data: The Stories Behind Elegant Data Solutions. O'Reilly Media. p. 257. ISBN 978-0-596-15711-1.
- Hilbert M, López P (April 2011). "The world's technological capacity to store, communicate, and compute information" (PDF). Science. 332 (6025): 60–5. Bibcode:2011Sci...332...60H. doi:10.1126/science.1200970. PMID 21310967.CS1 maint: ref=harv (link)
- "IBM What is big data? – Bringing big data to the enterprise". ibm.com. Retrieved 26 August 2013.
- Reinsel, David; Gantz, John; Rydning, John (13 April 2017). "Data Age 2025: The Evolution of Data to Life-Critical" (PDF). seagate.com. Framingham, MA, US: International Data Corporation. Retrieved 2 November 2017.
- Oracle and FSN, "Mastering Big Data: CFO Strategies to Transform Insight into Opportunity" Archived 4 August 2013 at the Wayback Machine, December 2012
- Jacobs, A. (6 July 2009). "The Pathologies of Big Data". ACMQueue.
- Magoulas, Roger; Lorica, Ben (February 2009). "Introduction to Big Data". Release 2.0. Sebastopol CA: O'Reilly Media (11).
- John R. Mashey (25 April 1998). "Big Data ... and the Next Wave of InfraStress" (PDF). Slides from invited talk. Usenix. Retrieved 28 September 2016.
- Steve Lohr (1 February 2013). "The Origins of 'Big Data': An Etymological Detective Story". The New York Times. Retrieved 28 September 2016.
- Snijders, C.; Matzat, U.; Reips, U.-D. (2012). "'Big Data': Big gaps of knowledge in the field of Internet". International Journal of Internet Science. 7: 1–5.
- Dedić, N.; Stanier, C. (2017). "Towards Differentiating Business Intelligence, Big Data, Data Analytics and Knowledge Discovery". Innovations in Enterprise Information Systems Management and Engineering. Lecture Notes in Business Information Processing. 285. Berlin ; Heidelberg: Springer International Publishing. pp. 114–122. doi:10.1007/978-3-319-58801-8_10. ISBN 978-3-319-58800-1. ISSN 1865-1356. OCLC 909580101.
- Everts, Sarah (2016). "Information Overload". Distillations. Vol. 2 no. 2. pp. 26–33. Retrieved 22 March 2018.
- Ibrahim; Targio Hashem, Abaker; Yaqoob, Ibrar; Badrul Anuar, Nor; Mokhtar, Salimah; Gani, Abdullah; Ullah Khan, Samee (2015). "big data" on cloud computing: Review and open research issues". Information Systems. 47: 98–115. doi:10.1016/j.is.2014.07.006.
- Grimes, Seth. "Big Data: Avoid 'Wanna V' Confusion". InformationWeek. Retrieved 5 January 2016.
- Fox, Charles (25 March 2018). Data Science for Transport. Springer Textbooks in Earth Sciences, Geography and Environment. Springer. ISBN 9783319729527.
- "avec focalisation sur Big Data & Analytique" (PDF). Bigdataparis.com. Retrieved 8 October 2017.
- Billings S.A. "Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains". Wiley, 2013
- "le Blog ANDSI » DSI Big Data". Andsi.fr. Retrieved 8 October 2017.
- Les Echos (3 April 2013). "Les Echos – Big Data car Low-Density Data ? La faible densité en information comme facteur discriminant – Archives". Lesechos.fr. Retrieved 8 October 2017.
- Kitchin, Rob; McArdle, Gavin (17 February 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Big Data & Society. 3 (1): 205395171663113. doi:10.1177/2053951716631130.
- Onay, Ceylan; Öztürk, Elif (2018). "A review of credit scoring research in the age of Big Data". Journal of Financial Regulation and Compliance. 26 (3): 382–405. doi:10.1108/JFRC-06-2017-0054.
- Big Data's Fourth V
- Kitchin, Rob; McArdle, Gavin (5 January 2016). "What makes Big Data, Big Data? Exploring the ontological characteristics of 26 datasets". Big Data & Society. 3 (1): 205395171663113. doi:10.1177/2053951716631130. ISSN 2053-9517.
- "Survey: Biggest Databases Approach 30 Terabytes". Eweek.com. Retrieved 8 October 2017.
- "LexisNexis To Buy Seisint For $775 Million". Washington Post. Retrieved 15 July 2004.
- https://www.washingtonpost.com/wp-dyn/content/article/2008/02/21/AR2008022100809.html
- Bertolucci, Jeff "Hadoop: From Experiment To Leading Big Data Platform", "Information Week", 2013. Retrieved on 14 November 2013.
- Webster, John. "MapReduce: Simplified Data Processing on Large Clusters", "Search Storage", 2004. Retrieved on 25 March 2013.
- "Big Data Solution Offering". MIKE2.0. Retrieved 8 December 2013.
- "Big Data Definition". MIKE2.0. Retrieved 9 March 2013.
- Boja, C; Pocovnicu, A; Bătăgan, L. (2012). "Distributed Parallel Architecture for Big Data". Informatica Economica. 16 (2): 116–127.
- "SOLVING KEY BUSINESS CHALLENGES WITH A BIG DATA LAKE" (PDF). Hcltech.com. August 2014. Retrieved 8 October 2017.
- "Method for testing the fault tolerance of MapReduce frameworks" (PDF). Computer Networks. 2015.
- Manyika, James; Chui, Michael; Bughin, Jaques; Brown, Brad; Dobbs, Richard; Roxburgh, Charles; Byers, Angela Hung (May 2011). "Big Data: The next frontier for innovation, competition, and productivity". McKinsey Global Institute. Retrieved 16 January 2016. Cite journal requires
|journal=(help) - "Future Directions in Tensor-Based Computation and Modeling" (PDF). May 2009.
- Lu, Haiping; Plataniotis, K.N.; Venetsanopoulos, A.N. (2011). "A Survey of Multilinear Subspace Learning for Tensor Data" (PDF). Pattern Recognition. 44 (7): 1540–1551. doi:10.1016/j.patcog.2011.01.004.
- Pllana, Sabri; Janciak, Ivan; Brezany, Peter; Wöhrer, Alexander (2016). "A Survey of the State of the Art in Data Mining and Integration Query Languages". 2011 14th International Conference on Network-Based Information Systems. 2011 International Conference on Network-Based Information Systems (NBIS 2011). IEEE Computer Society. pp. 341–348. arXiv:1603.01113. Bibcode:2016arXiv160301113P. doi:10.1109/NBiS.2011.58. ISBN 978-1-4577-0789-6.
- Wang, Yandong; Goldstone, Robin; Yu, Weikuan; Wang, Teng (October 2014). "Characterization and Optimization of Memory-Resident MapReduce on HPC Systems". 2014 IEEE 28th International Parallel and Distributed Processing Symposium. IEEE. pp. 799–808. doi:10.1109/IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
- L'Heureux, A.; Grolinger, K.; Elyamany, H. F.; Capretz, M. A. M. (2017). "Machine Learning With Big Data: Challenges and Approaches". IEEE Access. 5: 7776–7797. doi:10.1109/ACCESS.2017.2696365. ISSN 2169-3536.
- Monash, Curt (30 April 2009). "eBay's two enormous data warehouses".
Monash, Curt (6 October 2010). "eBay followup – Greenplum out, Teradata > 10 petabytes, Hadoop has some value, and more". - "Resources on how Topological Data Analysis is used to analyze big data". Ayasdi.
- CNET News (1 April 2011). "Storage area networks need not apply".
- "How New Analytic Systems will Impact Storage". September 2011. Archived from the original on 1 March 2012.
- Hilbert, Martin (2014). "What is the Content of the World's Technologically Mediated Information and Communication Capacity: How Much Text, Image, Audio, and Video?". The Information Society. 30 (2): 127–143. doi:10.1080/01972243.2013.873748.
- Rajpurohit, Anmol (11 July 2014). "Interview: Amy Gershkoff, Director of Customer Analytics & Insights, eBay on How to Design Custom In-House BI Tools". KDnuggets. Retrieved 14 July 2014.
Dr. Amy Gershkoff: "Generally, I find that off-the-shelf business intelligence tools do not meet the needs of clients who want to derive custom insights from their data. Therefore, for medium-to-large organizations with access to strong technical talent, I usually recommend building custom, in-house solutions."
- "The Government and big data: Use, problems and potential". Computerworld. 21 March 2012. Retrieved 12 September 2016.
- "White Paper: Big Data for Development: Opportunities & Challenges (2012) – United Nations Global Pulse". Unglobalpulse.org. Retrieved 13 April 2016.
- "WEF (World Economic Forum), & Vital Wave Consulting. (2012). Big Data, Big Impact: New Possibilities for International Development". World Economic Forum. Retrieved 24 August 2012.
- Hilbert, Martin (15 January 2013). "Big Data for Development: From Information- to Knowledge Societies". SSRN 2205145. Cite journal requires
|journal=(help) - "Elena Kvochko, Four Ways To talk About Big Data (Information Communication Technologies for Development Series)". worldbank.org. 4 December 2012. Retrieved 30 May 2012.
- "Daniele Medri: Big Data & Business: An on-going revolution". Statistics Views. 21 October 2013.
- Tobias Knobloch and Julia Manske (11 January 2016). "Responsible use of data". D+C, Development and Cooperation.
- Huser V, Cimino JJ (July 2016). "Impending Challenges for the Use of Big Data". International Journal of Radiation Oncology, Biology, Physics. 95 (3): 890–894. doi:10.1016/j.ijrobp.2015.10.060. PMC 4860172. PMID 26797535.
- Sejdic, Ervin; Falk, Tiago H. (4 July 2018). Signal Processing and Machine Learning for Biomedical Big Data. Sejdić, Ervin,, Falk, Tiago H. [Place of publication not identified]. ISBN 9781351061216. OCLC 1044733829.
- Raghupathi W, Raghupathi V (December 2014). "Big data analytics in healthcare: promise and potential". Health Information Science and Systems. 2 (1): 3. doi:10.1186/2047-2501-2-3. PMC 4341817. PMID 25825667.
- Viceconti M, Hunter P, Hose R (July 2015). "Big data, big knowledge: big data for personalized healthcare" (PDF). IEEE Journal of Biomedical and Health Informatics. 19 (4): 1209–15. doi:10.1109/JBHI.2015.2406883. PMID 26218867.
- O'Donoghue, John; Herbert, John (1 October 2012). "Data Management Within mHealth Environments: Patient Sensors, Mobile Devices, and Databases". Journal of Data and Information Quality. 4 (1): 5:1–5:20. doi:10.1145/2378016.2378021. S2CID 2318649.
- Mirkes EM, Coats TJ, Levesley J, Gorban AN (August 2016). "Handling missing data in large healthcare dataset: A case study of unknown trauma outcomes". Computers in Biology and Medicine. 75: 203–16. arXiv:1604.00627. Bibcode:2016arXiv160400627M. doi:10.1016/j.compbiomed.2016.06.004. PMID 27318570.
- Murdoch TB, Detsky AS (April 2013). "The inevitable application of big data to health care". JAMA. 309 (13): 1351–2. doi:10.1001/jama.2013.393. PMID 23549579.
- Vayena E, Salathé M, Madoff LC, Brownstein JS (February 2015). "Ethical challenges of big data in public health". PLOS Computational Biology. 11 (2): e1003904. Bibcode:2015PLSCB..11E3904V. doi:10.1371/journal.pcbi.1003904. PMC 4321985. PMID 25664461.
- Copeland, CS (July–August 2017). "Data Driving Discovery" (PDF). Healthcare Journal of New Orleans: 22–27.
- Yanase J, Triantaphyllou E (2019). "A Systematic Survey of Computer-Aided Diagnosis in Medicine: Past and Present Developments". Expert Systems with Applications. 138: 112821. doi:10.1016/j.eswa.2019.112821.
- Dong X, Bahroos N, Sadhu E, Jackson T, Chukhman M, Johnson R, Boyd A, Hynes D (2013). "Leverage Hadoop framework for large scale clinical informatics applications". AMIA Joint Summits on Translational Science Proceedings. AMIA Joint Summits on Translational Science. 2013: 53. PMID 24303235.
- Clunie D (2013). "Breast tomosynthesis challenges digital imaging infrastructure". Cite journal requires
|journal=(help) - Yanase J, Triantaphyllou E (2019). "The Seven Key Challenges for the Future of Computer-Aided Diagnosis in Medicine". Journal of Medical Informatics. 129: 413–422. doi:10.1016/j.ijmedinf.2019.06.017. PMID 31445285.
- "Degrees in Big Data: Fad or Fast Track to Career Success". Forbes. Retrieved 21 February 2016.
- "NY gets new boot camp for data scientists: It's free but harder to get into than Harvard". Venture Beat. Retrieved 21 February 2016.
- Wedel, Michel; Kannan, PK (2016). "Marketing Analytics for Data-Rich Environments". Journal of Marketing. 80 (6): 97–121. doi:10.1509/jm.15.0413.
- Couldry, Nick; Turow, Joseph (2014). "Advertising, Big Data, and the Clearance of the Public Realm: Marketers' New Approaches to the Content Subsidy". International Journal of Communication. 8: 1710–1726.
- "Why Digital Advertising Agencies Suck at Acquisition and are in Dire Need of an AI Assisted Upgrade". Ishti.org. 15 April 2018. Retrieved 15 April 2018.
- "Big data and analytics: C4 and Genius Digital". Ibc.org. Retrieved 8 October 2017.
- Marshall Allen (17 July 2018). "Health Insurers Are Vacuuming Up Details About You – And It Could Raise Your Rates". www.propublica.org. Retrieved 21 July 2018.
- "QuiO Named Innovation Champion of the Accenture HealthTech Innovation Challenge". Businesswire.com. 10 January 2017. Retrieved 8 October 2017.
- "A Software Platform for Operational Technology Innovation" (PDF). Predix.com. Retrieved 8 October 2017.
- Z. Jenipher Wang (March 2017). "Big Data Driven Smart Transportation: the Underlying Story of IoT Transformed Mobility".
- "That Internet Of Things Thing".
- Solnik, Ray. "The Time Has Come: Analytics Delivers for IT Operations". Data Center Journal. Retrieved 21 June 2016.
- Josh Rogin (2 August 2018). "Ethnic cleansing makes a comeback – in China" (Washington Post). Retrieved 4 August 2018.
Add to that the unprecedented security and surveillance state in Xinjiang, which includes all-encompassing monitoring based on identity cards, checkpoints, facial recognition and the collection of DNA from millions of individuals. The authorities feed all this data into an artificial-intelligence machine that rates people's loyalty to the Communist Party in order to control every aspect of their lives.
- "China: Big Data Fuels Crackdown in Minority Region: Predictive Policing Program Flags Individuals for Investigations, Detentions". hrw.org. Human Rights Watch. 26 February 2018. Retrieved 4 August 2018.
- "Discipline and Punish: The Birth of China's Social-Credit System". The Nation. 23 January 2019.
- "China's behavior monitoring system bars some from travel, purchasing property". CBS News. 24 April 2018.
- "The complicated truth about China's social credit system". WIRED. 21 January 2019.
- "News: Live Mint". Are Indian companies making enough sense of Big Data?. Live Mint. 23 June 2014. Retrieved 22 November 2014.
- "Israeli startup uses big data, minimal hardware to treat diabetes". Retrieved 28 February 2018.
- "Survey on Big Data Using Data Mining" (PDF). International Journal of Engineering Development and Research. 2015. Retrieved 14 September 2016.
- "Recent advances delivered by Mobile Cloud Computing and Internet of Things for Big Data applications: a survey". International Journal of Network Management. 11 March 2016. Retrieved 14 September 2016.
- Kalil, Tom (29 March 2012). "Big Data is a Big Deal". White House. Retrieved 26 September 2012.
- Executive Office of the President (March 2012). "Big Data Across the Federal Government" (PDF). White House. Archived from the original (PDF) on 11 December 2016. Retrieved 26 September 2012.
- Lampitt, Andrew (14 February 2013). "The real story of how big data analytics helped Obama win". InfoWorld. Retrieved 31 May 2014.
- "November 2018 | TOP500 Supercomputer Sites".
- Hoover, J. Nicholas. "Government's 10 Most Powerful Supercomputers". Information Week. UBM. Retrieved 26 September 2012.
- Bamford, James (15 March 2012). "The NSA Is Building the Country's Biggest Spy Center (Watch What You Say)". Wired Magazine. Retrieved 18 March 2013.
- "Groundbreaking Ceremony Held for $1.2 Billion Utah Data Center". National Security Agency Central Security Service. Archived from the original on 5 September 2013. Retrieved 18 March 2013.
- Hill, Kashmir. "Blueprints of NSA's Ridiculously Expensive Data Center in Utah Suggest It Holds Less Info Than Thought". Forbes. Retrieved 31 October 2013.
- Smith, Gerry; Hallman, Ben (12 June 2013). "NSA Spying Controversy Highlights Embrace of Big Data". Huffington Post. Retrieved 7 May 2018.
- Wingfield, Nick (12 March 2013). "Predicting Commutes More Accurately for Would-Be Home Buyers – NYTimes.com". Bits.blogs.nytimes.com. Retrieved 21 July 2013.
- "FICO® Falcon® Fraud Manager". Fico.com. Retrieved 21 July 2013.
- Alexandru, Dan. "Prof" (PDF). cds.cern.ch. CERN. Retrieved 24 March 2015.
- "LHC Brochure, English version. A presentation of the largest and the most powerful particle accelerator in the world, the Large Hadron Collider (LHC), which started up in 2008. Its role, characteristics, technologies, etc. are explained for the general public". CERN-Brochure-2010-006-Eng. LHC Brochure, English version. CERN. Retrieved 20 January 2013.
- "LHC Guide, English version. A collection of facts and figures about the Large Hadron Collider (LHC) in the form of questions and answers". CERN-Brochure-2008-001-Eng. LHC Guide, English version. CERN. Retrieved 20 January 2013.
- Brumfiel, Geoff (19 January 2011). "High-energy physics: Down the petabyte highway". Nature. 469. pp. 282–83. Bibcode:2011Natur.469..282B. doi:10.1038/469282a.
- "IBM Research – Zurich" (PDF). Zurich.ibm.com. Retrieved 8 October 2017.
- "Future telescope array drives development of Exabyte processing". Ars Technica. Retrieved 15 April 2015.
- "Australia's bid for the Square Kilometre Array – an insider's perspective". The Conversation. 1 February 2012. Retrieved 27 September 2016.
- "Delort P., OECD ICCP Technology Foresight Forum, 2012" (PDF). Oecd.org. Retrieved 8 October 2017.
- "NASA – NASA Goddard Introduces the NASA Center for Climate Simulation". Nasa.gov. Retrieved 13 April 2016.
- Webster, Phil. "Supercomputing the Climate: NASA's Big Data Mission". CSC World. Computer Sciences Corporation. Archived from the original on 4 January 2013. Retrieved 18 January 2013.
- "These six great neuroscience ideas could make the leap from lab to market". The Globe and Mail. 20 November 2014. Retrieved 1 October 2016.
- "DNAstack tackles massive, complex DNA datasets with Google Genomics". Google Cloud Platform. Retrieved 1 October 2016.
- "23andMe – Ancestry". 23andme.com. Retrieved 29 December 2016.
- Potenza, Alessandra (13 July 2016). "23andMe wants researchers to use its kits, in a bid to expand its collection of genetic data". The Verge. Retrieved 29 December 2016.
- "This Startup Will Sequence Your DNA, So You Can Contribute To Medical Research". Fast Company. 23 December 2016. Retrieved 29 December 2016.
- Seife, Charles. "23andMe Is Terrifying, but Not for the Reasons the FDA Thinks". Scientific American. Retrieved 29 December 2016.
- Zaleski, Andrew (22 June 2016). "This biotech start-up is betting your genes will yield the next wonder drug". CNBC. Retrieved 29 December 2016.
- Regalado, Antonio. "How 23andMe turned your DNA into a $1 billion drug discovery machine". MIT Technology Review. Retrieved 29 December 2016.
- "23andMe reports jump in requests for data in wake of Pfizer depression study | FierceBiotech". fiercebiotech.com. Retrieved 29 December 2016.
- Admire Moyo. "Data scientists predict Springbok defeat". itweb.co.za. Retrieved 12 December 2015.
- Regina Pazvakavambwa. "Predictive analytics, big data transform sports". itweb.co.za. Retrieved 12 December 2015.
- Dave Ryan. "Sports: Where Big Data Finally Makes Sense". huffingtonpost.com. Retrieved 12 December 2015.
- Frank Bi. "How Formula One Teams Are Using Big Data To Get The Inside Edge". Forbes. Retrieved 12 December 2015.
- Tay, Liz. "Inside eBay's 90PB data warehouse". ITNews. Retrieved 12 February 2016.
- Layton, Julia. "Amazon Technology". Money.howstuffworks.com. Retrieved 5 March 2013.
- "Scaling Facebook to 500 Million Users and Beyond". Facebook.com. Retrieved 21 July 2013.
- Constine, Josh (27 June 2017). "Facebook now has 2 billion monthly users… and responsibility". TechCrunch. Retrieved 3 September 2018.
- "Google Still Doing at Least 1 Trillion Searches Per Year". Search Engine Land. 16 January 2015. Retrieved 15 April 2015.
- Siwach, Gautam; Esmailpour, Amir (March 2014). Encrypted Search & Cluster Formation in Big Data (PDF). ASEE 2014 Zone I Conference. University of Bridgeport, Bridgeport, Connecticut, US. Archived from the original (PDF) on 9 August 2014. Retrieved 26 July 2014.
- "Obama Administration Unveils "Big Data" Initiative:Announces $200 Million in New R&D Investments" (PDF). The White House. Archived from the original (PDF) on 1 November 2012.
- "AMPLab at the University of California, Berkeley". Amplab.cs.berkeley.edu. Retrieved 5 March 2013.
- "NSF Leads Federal Efforts in Big Data". National Science Foundation (NSF). 29 March 2012.
- Timothy Hunter; Teodor Moldovan; Matei Zaharia; Justin Ma; Michael Franklin; Pieter Abbeel; Alexandre Bayen (October 2011). Scaling the Mobile Millennium System in the Cloud.
- David Patterson (5 December 2011). "Computer Scientists May Have What It Takes to Help Cure Cancer". The New York Times.
- "Secretary Chu Announces New Institute to Help Scientists Improve Massive Data Set Research on DOE Supercomputers". energy.gov.
- office/pressreleases/2012/2012530-governor-announces-big-data-initiative.html "Governor Patrick announces new initiative to strengthen Massachusetts' position as a World leader in Big Data" Check
|url=value (help). Commonwealth of Massachusetts. - "Big Data @ CSAIL". Bigdata.csail.mit.edu. 22 February 2013. Retrieved 5 March 2013.
- "Big Data Public Private Forum". cordis.europa.eu. 1 September 2012. Retrieved 16 March 2020.
- "Alan Turing Institute to be set up to research big data". BBC News. 19 March 2014. Retrieved 19 March 2014.
- "Inspiration day at University of Waterloo, Stratford Campus". betakit.com/. Retrieved 28 February 2014.
- Reips, Ulf-Dietrich; Matzat, Uwe (2014). "Mining "Big Data" using Big Data Services". International Journal of Internet Science. 1 (1): 1–8.
- Preis T, Moat HS, Stanley HE, Bishop SR (2012). "Quantifying the advantage of looking forward". Scientific Reports. 2: 350. Bibcode:2012NatSR...2E.350P. doi:10.1038/srep00350. PMC 3320057. PMID 22482034.
- Marks, Paul (5 April 2012). "Online searches for future linked to economic success". New Scientist. Retrieved 9 April 2012.
- Johnston, Casey (6 April 2012). "Google Trends reveals clues about the mentality of richer nations". Ars Technica. Retrieved 9 April 2012.
- Tobias Preis (24 May 2012). "Supplementary Information: The Future Orientation Index is available for download" (PDF). Retrieved 24 May 2012.
- Philip Ball (26 April 2013). "Counting Google searches predicts market movements". Nature. Retrieved 9 August 2013.
- Preis T, Moat HS, Stanley HE (2013). "Quantifying trading behavior in financial markets using Google Trends". Scientific Reports. 3: 1684. Bibcode:2013NatSR...3E1684P. doi:10.1038/srep01684. PMC 3635219. PMID 23619126.
- Nick Bilton (26 April 2013). "Google Search Terms Can Predict Stock Market, Study Finds". The New York Times. Retrieved 9 August 2013.
- Christopher Matthews (26 April 2013). "Trouble With Your Investment Portfolio? Google It!". TIME Magazine. Retrieved 9 August 2013.
- Philip Ball (26 April 2013). "Counting Google searches predicts market movements". Nature. Retrieved 9 August 2013.
- Bernhard Warner (25 April 2013). "'Big Data' Researchers Turn to Google to Beat the Markets". Bloomberg Businessweek. Retrieved 9 August 2013.
- Hamish McRae (28 April 2013). "Hamish McRae: Need a valuable handle on investor sentiment? Google it". The Independent. London. Retrieved 9 August 2013.
- Richard Waters (25 April 2013). "Google search proves to be new word in stock market prediction". Financial Times. Retrieved 9 August 2013.
- Jason Palmer (25 April 2013). "Google searches predict market moves". BBC. Retrieved 9 August 2013.
- E. Sejdić, "Adapt current tools for use with big data," Nature, vol. 507, no. 7492, pp. 306, Mar. 2014.
- Stanford. "MMDS. Workshop on Algorithms for Modern Massive Data Sets".
- Deepan Palguna; Vikas Joshi; Venkatesan Chakravarthy; Ravi Kothari & L. V. Subramaniam (2015). Analysis of Sampling Algorithms for Twitter. International Joint Conference on Artificial Intelligence.
- Kimble, C.; Milolidakis, G. (2015). "Big Data and Business Intelligence: Debunking the Myths". Global Business and Organizational Excellence. 35 (1): 23–34. arXiv:1511.03085. Bibcode:2015arXiv151103085K. doi:10.1002/joe.21642.
- Chris Anderson (23 June 2008). "The End of Theory: The Data Deluge Makes the Scientific Method Obsolete". WIRED.
- Graham M. (9 March 2012). "Big data and the end of theory?". The Guardian. London.
- "Good Data Won't Guarantee Good Decisions. Harvard Business Review". Shah, Shvetank; Horne, Andrew; Capellá, Jaime;. HBR.org. April 2012. Retrieved 8 September 2012.CS1 maint: extra punctuation (link)
- Big Data requires Big Visions for Big Change., Hilbert, M. (2014). London: TEDx UCL, x=independently organized TED talks
- Alemany Oliver, Mathieu; Vayre, Jean-Sebastien (2015). "Big Data and the Future of Knowledge Production in Marketing Research: Ethics, Digital Traces, and Abductive Reasoning". Journal of Marketing Analytics. 3 (1): 5–13. doi:10.1057/jma.2015.1. S2CID 111360835.
- Jonathan Rauch (1 April 2002). "Seeing Around Corners". The Atlantic.
- Epstein, J. M., & Axtell, R. L. (1996). Growing Artificial Societies: Social Science from the Bottom Up. A Bradford Book.
- "Delort P., Big data in Biosciences, Big Data Paris, 2012" (PDF). Bigdataparis.com. Retrieved 8 October 2017.
- "Next-generation genomics: an integrative approach" (PDF). nature. July 2010. Retrieved 18 October 2016.
- "BIG DATA IN BIOSCIENCES". ResearchGate. October 2015. Retrieved 18 October 2016.
- "Big data: are we making a big mistake?". Financial Times. 28 March 2014. Retrieved 20 October 2016.
- Ohm, Paul (23 August 2012). "Don't Build a Database of Ruin". Harvard Business Review.
- Darwin Bond-Graham, Iron Cagebook – The Logical End of Facebook's Patents, Counterpunch.org, 2013.12.03
- Darwin Bond-Graham, Inside the Tech industry's Startup Conference, Counterpunch.org, 2013.09.11
- Darwin Bond-Graham, The Perspective on Big Data, ThePerspective.com, 2018
- Al-Rodhan, Nayef (16 September 2014). "The Social Contract 2.0: Big Data and the Need to Guarantee Privacy and Civil Liberties – Harvard International Review". Harvard International Review. Archived from the original on 13 April 2017. Retrieved 3 April 2017.
- Barocas, Solon; Nissenbaum, Helen; Lane, Julia; Stodden, Victoria; Bender, Stefan; Nissenbaum, Helen (June 2014). Big Data's End Run around Anonymity and Consent. Cambridge University Press. pp. 44–75. doi:10.1017/cbo9781107590205.004. ISBN 9781107067356. S2CID 152939392.
- Lugmayr, Artur; Stockleben, Bjoern; Scheib, Christoph; Mailaparampil, Mathew; Mesia, Noora; Ranta, Hannu; Lab, Emmi (1 June 2016). "A COMPREHENSIVE SURVEY ON BIG-DATA RESEARCH AND ITS IMPLICATIONS – WHAT IS REALLY 'NEW' IN BIG DATA? – IT'S COGNITIVE BIG DATA!". Cite journal requires
|journal=(help) - danah boyd (29 April 2010). "Privacy and Publicity in the Context of Big Data". WWW 2010 conference. Retrieved 18 April 2011.
- Jones, MB; Schildhauer, MP; Reichman, OJ; Bowers, S (2006). "The New Bioinformatics: Integrating Ecological Data from the Gene to the Biosphere" (PDF). Annual Review of Ecology, Evolution, and Systematics. 37 (1): 519–544. doi:10.1146/annurev.ecolsys.37.091305.110031.
- Boyd, D.; Crawford, K. (2012). "Critical Questions for Big Data". Information, Communication & Society. 15 (5): 662–679. doi:10.1080/1369118X.2012.678878.
- Failure to Launch: From Big Data to Big Decisions Archived 6 December 2016 at the Wayback Machine, Forte Wares.
- "15 Insane Things That Correlate with Each Other".
- Random structures & algorithms
- Cristian S. Calude, Giuseppe Longo, (2016), The Deluge of Spurious Correlations in Big Data, Foundations of Science
- Gregory Piatetsky (12 August 2014). "Interview: Michael Berthold, KNIME Founder, on Research, Creativity, Big Data, and Privacy, Part 2". KDnuggets. Retrieved 13 August 2014.
- Pelt, Mason (26 October 2015). ""Big Data" is an over used buzzword and this Twitter bot proves it". siliconangle.com. SiliconANGLE. Retrieved 4 November 2015.
- Harford, Tim (28 March 2014). "Big data: are we making a big mistake?". Financial Times. Retrieved 7 April 2014.
- Ioannidis JP (August 2005). "Why most published research findings are false". PLOS Medicine. 2 (8): e124. doi:10.1371/journal.pmed.0020124. PMC 1182327. PMID 16060722.
- Lohr, Steve; Singer, Natasha (10 November 2016). "How Data Failed Us in Calling an Election". The New York Times. ISSN 0362-4331. Retrieved 27 November 2016.
- "How data-driven policing threatens human freedom". The Economist. 4 June 2018. ISSN 0013-0613. Retrieved 27 October 2019.
- Brayne, Sarah (29 August 2017). "Big Data Surveillance: The Case of Policing". American Sociological Review. 82 (5): 977–1008. doi:10.1177/0003122417725865. S2CID 3609838.
Further reading
| Library resources about Big data |
- Peter Kinnaird; Inbal Talgam-Cohen, eds. (2012). "Big Data". ACM Crossroads student magazine. XRDS: Crossroads, The ACM Magazine for Students. Vol. 19 no. 1. Association for Computing Machinery. ISSN 1528-4980. OCLC 779657714.
- Jure Leskovec; Anand Rajaraman; Jeffrey D. Ullman (2014). Mining of massive datasets. Cambridge University Press. ISBN 9781107077232. OCLC 888463433.
- Viktor Mayer-Schönberger; Kenneth Cukier (2013). Big Data: A Revolution that Will Transform how We Live, Work, and Think. Houghton Mifflin Harcourt. ISBN 9781299903029. OCLC 828620988.
- Press, Gil (9 May 2013). "A Very Short History of Big Data". forbes.com. Jersey City, NJ: Forbes Magazine. Retrieved 17 September 2016.
- "Big Data: The Management Revolution". hbr.org. Harvard Business Review. October 2012.
- O'Neil, Cathy (2017). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Broadway Books. ISBN 978-0553418835.
External links
| Authority control |
|
|---|