Se (kana)
せ, in hiragana, or セ in katakana, is one of the Japanese kana, each of which represents one mora. Both represent the sound [se], and when written with dakuten represent the sound [ze]. In the Ainu language, the katakana セ is sometimes written with a handakuten (which can be entered into a computer as either one character (セ゚) or two combined ones (セ゜) to represent the [t͡se] sound, and is interchangeable with ツェ (tse).
| Form | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal s- (さ行 sa-gyō) |
se | せ | セ |
| sei see sē |
せい せえ せー |
セイ セエ セー | |
| Addition dakuten z- (ざ行 za-gyō) |
ze | ぜ | ゼ |
| zei zee zē |
ぜい ぜえ ぜー |
ゼイ ゼエ ゼー | |
| se | ||||
|---|---|---|---|---|
| ||||
| transliteration | se | |||
| translit. with dakuten | ze | |||
| hiragana origin | 世 | |||
| katakana origin | 世 | |||
| spelling kana | 世界のセ (Sekai no "se") | |||


| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
Stroke order
 Stroke order in writing せ |
 Stroke order in writing セ |
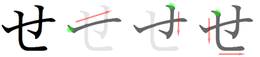
Stroke order in writing せ
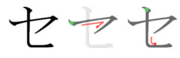
Stroke order in writing セ
Other communicative representations
| Japanese radiotelephony alphabet | Wabun code |
| 世界のセ Sekai no "Se" |
 |
|
 |
 |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-12456 Japanese Braille |
- Full Braille representation
| せ / セ in Japanese Braille | |||
|---|---|---|---|
| せ / セ se | ぜ / ゼ ze | せい / セー sē/sei | ぜい / ゼー zē/zei |
| Preview | せ | セ | セ | ㋝ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER SE | KATAKANA LETTER SE | HALFWIDTH KATAKANA LETTER SE | CIRCLED KATAKANA SE | ||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12379 | U+305B | 12475 | U+30BB | 65406 | U+FF7E | 13021 | U+32DD |
| UTF-8 | 227 129 155 | E3 81 9B | 227 130 187 | E3 82 BB | 239 189 190 | EF BD BE | 227 139 157 | E3 8B 9D |
| Numeric character reference | せ | せ | セ | セ | セ | セ | ㋝ | ㋝ |
| Shift JIS[1] | 130 185 | 82 B9 | 131 90 | 83 5A | 190 | BE | ||
| EUC-JP[2] | 164 187 | A4 BB | 165 187 | A5 BB | 142 190 | 8E BE | ||
| GB 18030[3] | 164 187 | A4 BB | 165 187 | A5 BB | 132 49 152 54 | 84 31 98 36 | ||
| EUC-KR[4] / UHC[5] | 170 187 | AA BB | 171 187 | AB BB | ||||
| Big5 (non-ETEN kana)[6] | 198 191 | C6 BF | 199 83 | C7 53 | ||||
| Big5 (ETEN / HKSCS)[7] | 199 66 | C7 42 | 199 183 | C7 B7 | ||||
| Preview | ぜ | ゼ | セ゚ | |||
|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER ZE | KATAKANA LETTER ZE | KATAKANA LETTER AINU CE[8] | |||
| Encodings | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12380 | U+305C | 12476 | U+30BC | 12475 12442 | U+30BB+309A |
| UTF-8 | 227 129 156 | E3 81 9C | 227 130 188 | E3 82 BC | 227 130 187 227 130 154 | E3 82 BB E3 82 9A |
| Numeric character reference | ぜ | ぜ | ゼ | ゼ | セ | セ |
| Shift JIS (plain)[1] | 130 186 | 82 BA | 131 91 | 83 5B | ||
| Shift JIS-2004[9] | 130 186 | 82 BA | 131 91 | 83 5B | 131 156 | 83 9C |
| EUC-JP (plain)[2] | 164 188 | A4 BC | 165 188 | A5 BC | ||
| EUC-JIS-2004[10] | 164 188 | A4 BC | 165 188 | A5 BC | 165 252 | A5 FC |
| GB 18030[3] | 164 188 | A4 BC | 165 188 | A5 BC | ||
| EUC-KR[4] / UHC[5] | 170 188 | AA BC | 171 188 | AB BC | ||
| Big5 (non-ETEN kana)[6] | 198 192 | C6 C0 | 199 84 | C7 54 | ||
| Big5 (ETEN / HKSCS)[7] | 199 67 | C7 43 | 199 184 | C7 B8 | ||
| Look up せ, ぜ, セ, or ゼ in Wiktionary, the free dictionary. |
gollark: You are, probably.
gollark: Unless it's only in ones which contain multiple users, to spite you.
gollark: * .
gollark: There's no field in them for user ID, so I doubt it'
gollark: Also, the messages are in CSV and other stuff/metadata's JSON.
References
- Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- Unicode Consortium. "Unicode Named Character Sequences". Unicode Character Database.
- Project X0213 (2009-05-03). "Shift_JIS-2004 (JIS X 0213:2004 Appendix 1) vs Unicode mapping table".
- Project X0213 (2009-05-03). "EUC-JIS-2004 (JIS X 0213:2004 Appendix 3) vs Unicode mapping table".
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.