Ḏāl
Ḏāl (ذ, also be transcribed as dhāl) is one of the six letters the Arabic alphabet added to the twenty-two inherited from the Phoenician alphabet (the others being ṯāʾ, ḫāʾ, ḍād, ẓāʾ, ġayn). In Modern Standard Arabic it represents /ð/. In name and shape, it is a variant of dāl (د). Its numerical value is 700 (see abjad numerals). The Arabic letter ذ is named ذال ḏāl. It is written is several ways depending in its position in the word:
| Position in word: | Isolated | Final | Medial | Initial |
|---|---|---|---|---|
| Glyph form: (Help) |
ذ | ـذ | ـذ | ذ |
| Ḏāl | |
|---|---|
| ذ | |
| Usage | |
| Writing system | Arabic script |
| Type | Abjad |
| Language of origin | Arabic language |
| Phonetic usage | ð |
| Alphabetical position | 9 |
| History | |
| Development |
|
| Other | |
The South Arabian alphabet retained a symbol for ḏ, ![]()
When representing this sound in transliteration of Arabic into Hebrew, it is written as ד׳.
This sound is found in English, as in the words "those" or "then". In English the sound is normally rendered "dh" when transliterated from foreign languages, but when it occurs in English words it is one of the pronunciations occurring for the letters "th".
Pronunciations
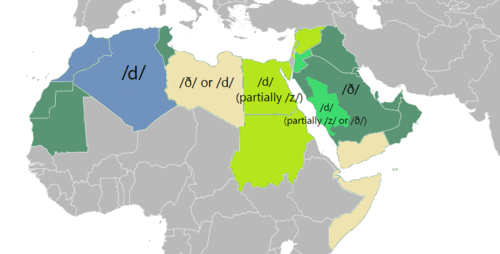
Between and within contemporary varieties of Arabic, pronunciation of the letter ḏāl differs:
- The Gulf, Iraqi, Tunisian dialects use the Classical and Modern Standard sound of [ð].
- In Maghrebi Arabic, it is consistently pronounced as the voiced dental plosive [d̪].
- In Hejazi Arabic, it merges with /d/ or /z/ depending on the word. Furthermore it keeps its classical value /ð/ in some Classical Arabic words.
- In the Mashriq (in the broad sense, including Egyptian, Sudanese and Levantine dialects), it becomes a sibilant voiced alveolar fricative [z]. Furthermore, in words fully assimilated into a Mashriq dialect, the sound has merged with /d/ (د).
Regardless of these regional differences, the pattern of the speaker's variety of Arabic frequently intrudes into otherwise Modern Standard speech; this is widely accepted, and is the norm when speaking the mesolect known alternately as lugha wusṭā ("middling/compromise language") or ʿAmmiyyat/Dārijat al-Muṯaqqafīn ("Educated/Cultured Colloquial") used in the informal speech of educated Arabs of different countries. (cf. Arabic dialect#Formal vs. vernacular speech)
See also
| Overviews | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Alphabet |
| ||||||||
| Letters | |||||||||
| Notable varieties |
| ||||||||
| Pidgins/Creoles | |||||||||
| Academic | |||||||||
| Linguistics | |||||||||
| |||||||||
| Technical |
| ||||||||
aSociolinguistically not Arabic
| |||||||||