My math says that's on the order of 83K events a second. That's a lot.
I'm not quite sure why you're separating RMQ and ELK, as RMQ can be a component of ELK. In fact, the very large deployments I know of definitely use either an AQMP solution like Rabbit, or something like Kafka, to provide the buffer between event generation and the parsing tier, as well as feeding multiple consumers.
The general high-scale pipeline that can handle an event-stream like you're considering:
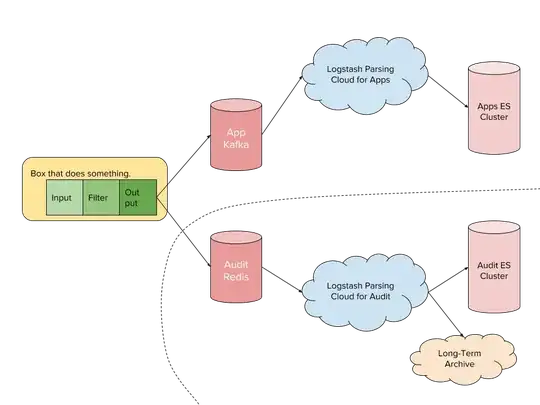
- Shippers send the logs to a central queue. Shipping can be FileBeat, Logstash itself, or something else entirely.
- The queue system, whatever it is. Could be Redis, RabbitMQ, Kafka, or something else.
- The parsing tier. A group of Logstash nodes that pulls events off the queue, massages them, and ships them on to the next stage.
- This scales horizontally. So long as your queue system can keep up, you can keep adding parsers here. In our system, with our filter rules, we can do 2K events/second per core. Yours will be different.
- If you leverage channels in your queue, you can even have multiple parsing tiers depending on how your workload splits out.
- This group is high CPU. How high RAM it is, depends on how gnarly your filters end up being.
- The Storage tier. In classic ELK, this is ElasticSearch. It doesn't have to be, though.
- An ElasticSearch cluster handling 300M events an hour is going to be big. No getting around that. How big depends on how long you want to keep the data.
- It sounds like your consumers are expecting files. This can be done too. So is sending processed events (which are just JSON) into yet another queuing system for consumption by other system.
The advantage to this architecture is that you're not putting your filtering logic on the resources that are doing production work. It also reduces the ingestion problem for ElasticSearch into mostly bulk requests coming from the Logstash parsing tier, rather than smaller ingestion batches coming from the production resources.
This also provides some security separation between your log archive (ElasticSearch) and your production resources. If one of those gets an evil person on them, having the queue buffer means they can't directly scrub ElasticSearch of their presence. That matters when you have a Security organization in your company, and at 300M events per hour you're probably large enough to have one.
Points against the Rabbit system are more around missing features. Rabbit is a queuing system, and doesn't by itself provide any way to transform the data (L in ELK) or store it for display (E and K in ELK). A log-archive system that can't display what its storing is not a good log-archive system.
