We have a GlusterFS cluster we use for our processing function. We want to get Windows integrated into it, but are having some trouble figuring out how to avoid the single-point-of-failure that is a Samba server serving a GlusterFS volume.
Our file-flow works like this:
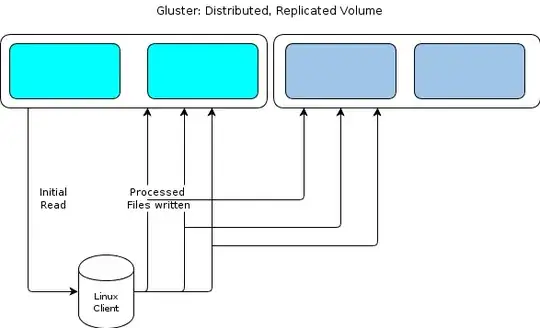
- Files are read by a Linux processing node.
- The files are processed.
- Results (can be small, can be quite large) are written back to the GlusterFS volume as they're done.
- Results can be written to a database instead, or may include several files of various sizes.
- The processing node picks up another job off of the queue and GOTO 1.
Gluster is great since it provides a distributed volume, as well as instant replication. Disaster resilience is nice! We like it.
However, as Windows doesn't have a native GlusterFS client we need some way for our Windows-based processing nodes to interact with the file store in a similarly resilient way. The GlusterFS documentation states that the way to provide Windows access is to set up a Samba server on top of a mounted GlusterFS volume. That would lead to a file flow like this:
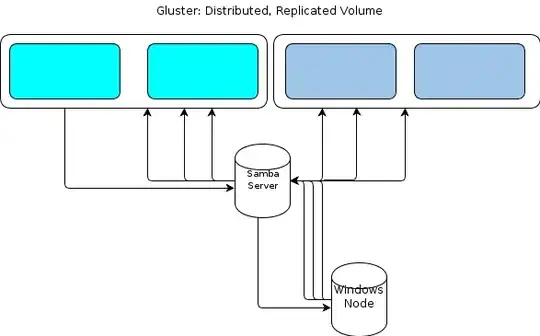
That looks like a single-point-of-failure to me.
One option is to cluster Samba, but that appears to be based on unstable code right now and thus out of the running.
So I'm looking for another method.
Some key details about the kinds of data we throw around:
- Original file-sizes can be anywhere from a few KB to tens of GB.
- Processed file-sizes can be anywhere from a few KB to a GB or two.
- Certain processes, such as digging in an archive file like .zip or .tar can cause a LOT of further writes as the contained files are imported into the file-store.
- File-counts can get into the 10's of millions.
This workload does not work with a "static workunit size" Hadoop setup. Similarly, we've evaluated S3-style object-stores, but found them lacking.
Our application is custom written in Ruby, and we do have a Cygwin environment on the Windows nodes. This may help us.
One option I'm considering is a simple HTTP service on a cluster of servers that have the GlusterFS volume mounted. Since all we're doing with Gluster is essentially GET/PUT operations, that seems easily transferable to an HTTP-based file-transfer method. Put them behind a loadbalancer pair and the Windows nodes can HTTP PUT to their little blue heart's content.
What I don't know is how GlusterFS coherency would be maintained. The HTTP-proxy layer introduces enough latency between when the processing node reports that it is done with the write and when it is actually visible on the GlusterFS volume, that I'm worried about later processing stages attempting to pick up the file won't find it. I'm pretty sure that using the direct-io-mode=enable mount-option will help, but I'm not sure if that is enough. What else should I be doing to improve coherency?
Or should I be pursuing another method entirely?
As Tom pointed out below, NFS is another option. So I ran a test. Since the above mentioned files have client-supplied names that we need to keep, and can come in any language, we do need to preserve the file-names. So I built a directory with these files:

When I mount it from a Server 2008 R2 system with the NFS Client installed, I get a directory listing like this:

Clearly, Unicode is not being preserved. So NFS isn't going to work for me.