Merge algorithm
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.
Application
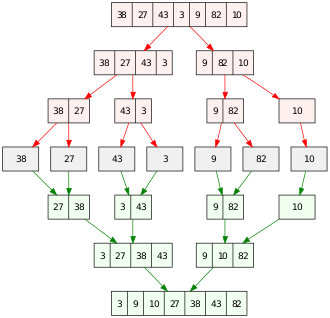
The merge algorithm plays a critical role in the merge sort algorithm, a comparison-based sorting algorithm. Conceptually, merge sort algorithm consists of two steps:
- Recursively divide the list into sublists of (roughly) equal length, until each sublist contains only one element, or in the case of iterative (bottom up) merge sort, consider a list of n elements as n sub-lists of size 1. A list containing a single element is, by definition, sorted.
- Repeatedly merge sublists to create a new sorted sublist until the single list contains all elements. The single list is the sorted list.
The merge algorithm is used repeatedly in the merge sort algorithm.
An example merge sort is given in the illustration. It starts with an unsorted array of 7 integers. The array is divided into 7 partitions; each partition contains 1 element and is sorted. The sorted partitions are then merged to produce larger, sorted, partitions, until 1 partition, the sorted array, is left.
Merging two lists
Merging two sorted lists into one can be done in linear time and linear space. The following pseudocode demonstrates an algorithm that merges input lists (either linked lists or arrays) A and B into a new list C.[1][2]:104 The function head yields the first element of a list; "dropping" an element means removing it from its list, typically by incrementing a pointer or index.
algorithm merge(A, B) is
inputs A, B : list
returns list
C := new empty list
while A is not empty and B is not empty do
if head(A) ≤ head(B) then
append head(A) to C
drop the head of A
else
append head(B) to C
drop the head of B
// By now, either A or B is empty. It remains to empty the other input list.
while A is not empty do
append head(A) to C
drop the head of A
while B is not empty do
append head(B) to C
drop the head of B
return C
When the inputs are linked lists, this algorithm can be implemented to use only a constant amount of working space; the pointers in the lists' nodes can be reused for bookkeeping and for constructing the final merged list.
In the merge sort algorithm, this subroutine is typically used to merge two sub-arrays A[lo..mid], A[mid..hi] of a single array A. This can be done by copying the sub-arrays into a temporary array, then applying the merge algorithm above.[1] The allocation of a temporary array can be avoided, but at the expense of speed and programming ease. Various in-place merge algorithms have been devised,[3] sometimes sacrificing the linear-time bound to produce an O(n log n) algorithm;[4] see Merge sort § Variants for discussion.
K-way merging
k-way merging generalizes binary merging to an arbitrary number k of sorted input lists. Applications of k-way merging arise in various sorting algorithms, including patience sorting[5] and an external sorting algorithm that divides its input into k = 1/M − 1 blocks that fit in memory, sorts these one by one, then merges these blocks.[2]:119–120
Several solutions to this problem exist. A naive solution is to do a loop over the k lists to pick off the minimum element each time, and repeat this loop until all lists are empty:
- Input: a list of k lists.
- While any of the lists is non-empty:
- Loop over the lists to find the one with the minimum first element.
- Output the minimum element and remove it from its list.
In the worst case, this algorithm performs (k−1)(n−k/2) element comparisons to perform its work if there are a total of n elements in the lists.[6] It can be improved by storing the lists in a priority queue (min-heap) keyed by their first element:
- Build a min-heap h of the k lists, using the first element as the key.
- While any of the lists is non-empty:
- Let i = find-min(h).
- Output the first element of list i and remove it from its list.
- Re-heapify h.
Searching for the next smallest element to be output (find-min) and restoring heap order can now be done in O(log k) time (more specifically, 2⌊log k⌋ comparisons[6]), and the full problem can be solved in O(n log k) time (approximately 2n⌊log k⌋ comparisons).[6][2]:119–120
A third algorithm for the problem is a divide and conquer solution that builds on the binary merge algorithm:
- If k = 1, output the single input list.
- If k = 2, perform a binary merge.
- Else, recursively merge the first ⌊k/2⌋ lists and the final ⌈k/2⌉ lists, then binary merge these.
When the input lists to this algorithm are ordered by length, shortest first, it requires fewer than n⌈log k⌉ comparisons, i.e., less than half the number used by the heap-based algorithm; in practice, it may be about as fast or slow as the heap-based algorithm.[6]
Parallel merge
A parallel version of the binary merge algorithm can serve as a building block of a parallel merge sort. The following pseudocode demonstrates this algorithm in a parallel divide-and-conquer style (adapted from Cormen et al.[7]:800). It operates on two sorted arrays A and B and writes the sorted output to array C. The notation A[i...j] denotes the part of A from index i through j, exclusive.
algorithm merge(A[i...j], B[k...ℓ], C[p...q]) is
inputs A, B, C : array
i, j, k, ℓ, p, q : indices
let m = j - i,
n = ℓ - k
if m < n then
swap A and B // ensure that A is the larger array: i, j still belong to A; k, ℓ to B
swap m and n
if m ≤ 0 then
return // base case, nothing to merge
let r = ⌊(i + j)/2⌋
let s = binary-search(A[r], B[k...ℓ])
let t = p + (r - i) + (s - k)
C[t] = A[r]
in parallel do
merge(A[i...r], B[k...s], C[p...t])
merge(A[r+1...j], B[s...ℓ], C[t+1...q])
The algorithm operates by splitting either A or B, whichever is larger, into (nearly) equal halves. It then splits the other array into a part with values smaller than the midpoint of the first, and a part with larger or equal values. (The binary search subroutine returns the index in B where A[r] would be, if it were in B; that this always a number between k and ℓ.) Finally, each pair of halves is merged recursively, and since the recursive calls are independent of each other, they can be done in parallel. Hybrid approach, where serial algorithm is used for recursion base case has been shown to perform well in practice [8]
The work performed by the algorithm for two arrays holding a total of n elements, i.e., the running time of a serial version of it, is O(n). This is optimal since n elements need to be copied into C. To calculate the span of the algorithm, it is necessary to derive a Recurrence relation. Since the two recursive calls of merge are in parallel, only the costlier of the two calls needs to be considered. In the worst case, the maximum number of elements in one of the recursive calls is at most since the array with more elements is perfectly split in half. Adding the cost of the Binary Search, we obtain this recurrence as an upper bound:



The solution is , meaning that it takes that much time on an ideal machine with an unbounded number of processors.[7]:801–802

Note: The routine is not stable: if equal items are separated by splitting A and B, they will become interleaved in C; also swapping A and B will destroy the order, if equal items are spread among both input arrays. As a result, when used for sorting, this algorithm produces a sort that is not stable.
Language support
Some computer languages provide built-in or library support for merging sorted collections.
C++
The C++'s Standard Template Library has the function std::merge, which merges two sorted ranges of iterators, and std::inplace_merge, which merges two consecutive sorted ranges in-place. In addition, the std::list (linked list) class has its own merge method which merges another list into itself. The type of the elements merged must support the less-than (<) operator, or it must be provided with a custom comparator.
C++17 allows for differing execution policies, namely sequential, parallel, and parallel-unsequenced.[9]
See also
- Merge (revision control)
- Join (relational algebra)
- Join (SQL)
- Join (Unix)
References
- Skiena, Steven (2010). The Algorithm Design Manual (2nd ed.). Springer Science+Business Media. p. 123. ISBN 1-849-96720-2.
- Kurt Mehlhorn; Peter Sanders (2008). Algorithms and Data Structures: The Basic Toolbox. Springer. ISBN 978-3-540-77978-0.
- Katajainen, Jyrki; Pasanen, Tomi; Teuhola, Jukka (1996). "Practical in-place mergesort". Nordic J. Computing. 3 (1): 27–40. CiteSeerX 10.1.1.22.8523.
- Kim, Pok-Son; Kutzner, Arne (2004). Stable Minimum Storage Merging by Symmetric Comparisons. European Symp. Algorithms. Lecture Notes in Computer Science. 3221. pp. 714–723. CiteSeerX 10.1.1.102.4612. doi:10.1007/978-3-540-30140-0_63. ISBN 978-3-540-23025-0.
- Chandramouli, Badrish; Goldstein, Jonathan (2014). Patience is a Virtue: Revisiting Merge and Sort on Modern Processors. SIGMOD/PODS.
- Greene, William A. (1993). k-way Merging and k-ary Sorts (PDF). Proc. 31-st Annual ACM Southeast Conf. pp. 127–135.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. ISBN 0-262-03384-4.
- Victor J. Duvanenko (2011), "Parallel Merge", Dr. Dobb's Journal
- "std:merge". cppreference.com. 2018-01-08. Retrieved 2018-04-28.
- https://docs.python.org/library/heapq.html#heapq.merge
Further reading
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89685-0. Pages 158–160 of section 5.2.4: Sorting by Merging. Section 5.3.2: Minimum-Comparison Merging, pp. 197–207.
External links
- High Performance Implementation of Parallel and Serial Merge in C# with source in GitHub and in C++ GitHub