GeoDa
GeoDa is a free software package that conducts spatial data analysis, geovisualization, spatial autocorrelation and spatial modeling.

OpenGeoDa is the cross-platform, open source version of Legacy GeoDa. While Legacy GeoDa only runs on Windows XP, OpenGeoDa runs on different versions of Windows (including XP, Vista, 7, 8 and 10), Mac OS, and Linux. The package was initially developed by the Spatial Analysis Laboratory of the University of Illinois at Urbana-Champaign under the direction of Luc Anselin. From 2016 development continues at the Center for Spatial Data Science (CSDS) at the University of Chicago. [1]
GeoDa has powerful capabilities to perform spatial analysis, multivariate exploratory data analysis, and global and local spatial autocorrelation. It also performs basic linear regression. As for spatial models, both the spatial lag model and the spatial error model, both estimated by maximum likelihood, are included.
OpenGeoDa is released under the GNU GPL version 3.0.[2]
History
GeoDa replaced what was previously called DynESDA, a module that worked under the old ArcView 3.x to perform exploratory spatial data analysis (or ESDA). Current releases of GeoDa no longer depend on the presence of ArcView or other GIS packages on a system.
Functionality
Projects in GeoDa basically consist of a shapefile that defines the lattice data, and an attribute table in a .dbf format. The attribute table can be edited inside GeoDa.
The package is specialized in exploratory data analysis and geo-visualization, where it exploits techniques for dynamic linking and brushing. This means that when the user has multiple views or windows in a project, selecting an object in one of them will highlight the same object in all other windows.
GeoDa also is capable of producing histograms, box plots, Scatter plots to conduct simple exploratory analyses of the data. The most important thing, however, is the capability of mapping and linking those statistical devices with the spatial distribution of the phenomenon that the users are studying.
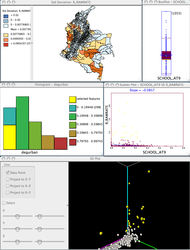
Dynamic linking and brushing in GeoDa
Dynamic linking and brushing are powerful devices as they allow users to interactively discover or confirm suspected patterns of spatial arrangement of the data or otherwise discard the existence of those. It allows users to extract information from data in spatial arrangements that may otherwise require very heavy computer routines to process the numbers and yield useful statistical results. The latter may also cost the users quite a bit in terms of expert knowledge and software capabilities.
Anselin's Moran scatter plot
- See also Indicators of spatial association
A very interesting device available in GeoDa to explore global patterns of autocorrelation in space is Anselin's Moran scatterplot. This graph depicts a standardized variable in the x-axis versus the spatial lag of that standardized variable. The spatial lag is nothing but a summary of the effects of the neighboring spatial units. That summary is obtained by means of a spatial weights matrix, which can take various forms, but a very commonly used is the contiguity matrix. The contiguity matrix is an array that has a value of one in the position (i, j) whenever the spatial unit j is contiguous to the unit i. For convenience that matrix is standardized in such a way that the rows sum to one by dividing each value by the row sum of the original matrix.
In essence, Anselin's Moran scatterplot presents the relation of the variable in the location i with respect to the values of that variable in the neighboring locations. By construction, the slope of the line in the scatter plot is equivalent to the Moran's I coefficient. The latter is a well-known statistic that accounts for the Global spatial autocorrelation. If that slope is positive it means that there is positive spatial autocorrelation: high values of the variable in location i tend to be clustered with high values of the same variable in locations that are neighbors of i, and vice versa. If the slope in the scatter plot is negative that means that we have a sort of checkerboard pattern or a sort of spatial competition in which high values in a variable in location i tend to be co-located with lower values in the neighboring locations.
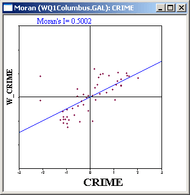
In Anselin's Moran scatter plot, the slope of the curve is calculated and displayed on top of the graph. In this case, this value is positive, which means that areas with a high rate of criminality tend to have neighbors with high rates as well, and vice versa.
Global versus Local Analyses in GeoDa
At the global level we can talk about clustering, i.e. the general trend of the map to be clustered; at the local level, we can talk about clusters i.e. we are able to pinpoint the locations of the clusters. The latter can be assessed by means of Local Indicators of Spatial Association - LISA. LISA analysis allows us to identify where are the areas high values of a variable that are surrounded by high values on the neighboring areas i.e. what is called the high-high clusters. Concomitantly, the low-low clusters are also identified from this analysis.
Another type of phenomenon that is important to analyze in this context is the existence of outliers that represent high values of the variable in a given location surrounded by low values in the neighboring locations. This functionality is available in GeoDa by means of Anselin's Moran scatter plot. Note, however, that the fact that a value is high in comparison with the values in neighboring locations does not necessarily mean that it is an outlier as we need to assess the statistical significance of that relationship. In other words, we may find areas where there seems to be clustering or where there may seem to be clusters but when the statistical procedures are conducted they turn to be non statistically significant clusters or outliers. The procedures employed to assess statistical significance consists of a Monte Carlo simulation of different arrangements of the data and the construction of an empirical distribution of simulated statistics. Afterward, the value obtained originally is compared to the distribution of simulated values and if the value exceeds the 95h percentile it is said that the relation found is significant at 5%.
Further reading
- Anselin, Luc (2005). "Exploring Spatial Data with GeoDaTM: A Workbook". Spatial Analysis Laboratory. (Workbook developed for the Legacy version of GeoDa (0.9.5i))
- Anselin, Luc, Ibnu Syabri and Youngihn Kho (2006). GeoDa: An introduction to spatial data analysis. Geographical Analysis 38, 5-22
- Anselin, Luc, Rey, Sergio J. (2014). Modern Spatial Econometrics in Practice: A Guide to GeoDa, GeoDaSpace, and PySAL. GeoDa Press LLC, Chicago, IL