I have a template from CentOS 7 (1602) that I have deployed roughly 200 VMs using it until I noticed the issue, so it would be ideal to fix these VM's rather than start from scratch.
The VM's 'randomly' fail, usually between 7PM and 11PM, sometimes two nights in a row, sometimes not for a week or two. When one VM fails, most of them also fail. They seem to loose disk access. Rebooting the VM immediately solves the issue and it does not reoocur for at least 24 hours. Even when we don't reboot them till the next day they still reboot during this time period.
Some of the VM's have nothing installed on them and still have this issue. Root partition and boot partition are hardly used. Logs show no issues.
No other VMs are affected except this particular centos template. We are using VMWare 4 (I know, I know) but we have never had any issues other than this and new images have no issue. I see no spikes in CPU or disk use in VMWare around the failure.
Here is a screenshot as it fails:
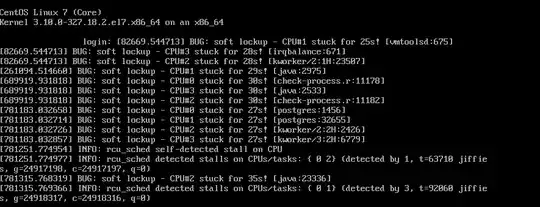
Here is a screenshot when trying to access the VM after a number of minutes has elapsed:
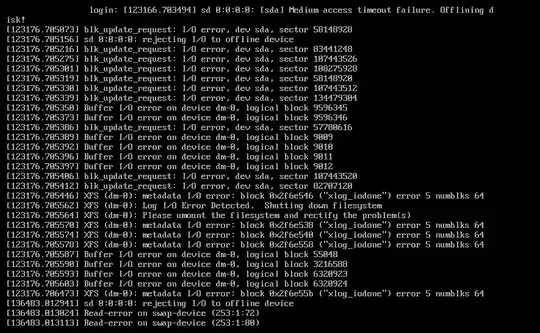
Example bootstrap script used on these servers: http://pastebin.com/gs3AzV5m
