This is my graph of HDD avgqu-sz from different app machines: 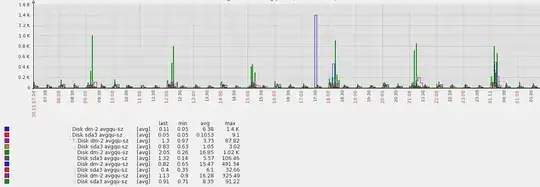 App caches data in memory and every n minutes are data flushed to filesystem + every m minutes are data (re)loaded from filesystem in memory. That's the reason of the spikes. Block devices utilization during these spikes is 80-95%.
App caches data in memory and every n minutes are data flushed to filesystem + every m minutes are data (re)loaded from filesystem in memory. That's the reason of the spikes. Block devices utilization during these spikes is 80-95%.
{kind=link}
Q: Do I need to worry about my disks performance? How to interpret this graph - is OK or not OK? Do I need to optimize something?
- Yes, I have pretty high spikes ~1k, but then queue size is ~1 => one day avg is ~16 - I don't know If I can be happy with this avg value
- Yes, I know what metric avgqu-sz means
- Yes, I've optimized my filesystems for high IOps (noatime, nodirtime)