I'm building a proof-of-concept loadbalancer with CentOS 7 and keepalived.
I took Red Hat's load balancer administration guide as a reference and implemented a NAT'ed loadbalancer with 2 nodes which carries traffic between a public and a private network. To that effect, the loadbalancer has 2 VIPs: one for client traffic, on the public network; and one for ensuring failover for response traffic, on the private network.
The 2 loadbalancers (lb1 and lb2) are sending traffic to 2 hosts running apache (fe1 and fe2) on the internal network. lb1 is master, lb2 is backup.
Diagram is as follows:
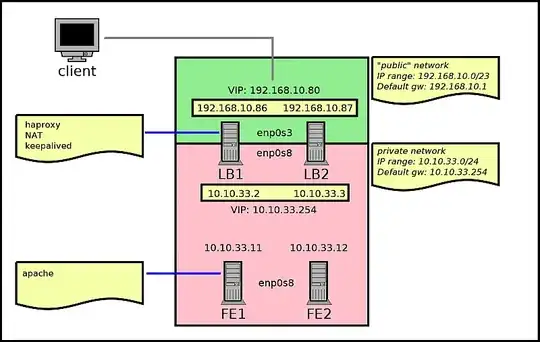
The loadbalancer works, and fails over as expected when one of the directors goes down.
What is bugging me is that the incoming traffic on the real servers isn't coming from the internal VIP (10.10.33.254), but from the loadbalancer hosts' real addresses (10.10.33.2 and 10.10.33.3). Ping from the real servers is also going through real IP addresses, and not the internal VIP, despite it being set as the default gateway for them.
Traceroute (lb1 as active):
[root@rsfe2 ~]# tracepath www.google.com
1: rsfe2 0.081ms pmtu 1500
1: 10.10.33.2 0.385ms
1: 10.10.33.2 0.385ms
2: no reply
3: 192.168.1.1 1.552ms
(lb1 down, lb2 as active):
[root@rsfe2 ~]# tracepath www.google.com
1: rsfe2 0.065ms pmtu 1500
1: 10.10.33.3 0.463ms
1: 10.10.33.3 0.462ms
2: no reply
3: 192.168.1.1 2.394ms
Routing table:
[root@rsfe2 ~]# ip route
default via 10.10.33.254 dev enp0s8 proto static metric 1024
10.10.33.0/24 dev enp0s8 proto kernel scope link src 10.10.33.12
Despite this apparent anomaly, failover from one loadbalancer to the other works as expected from the clients' standpoint, seemingly due to the gratuitous ARPs from the surviving loadbalancer.
It seems that the internal VIP is not used for anything except ARP announcements, in the end (there is no traffic to or from it).
Should I be concerned about this, or is it working as expected?
My keepalived.conf contents:
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
router_id LVS_DEVEL
}
vrrp_sync_group VG1 {
group {
RH_EXT
RH_INT
}
}
vrrp_script check_haproxy {
script "/bin/pkill -0 -F /var/run/haproxy.pid"
interval 1
fall 1
rise 5
}
vrrp_instance RH_EXT {
state MASTER
interface enp0s3
virtual_router_id 50
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass password123
}
virtual_ipaddress {
192.168.10.80
}
track_script {
check_haproxy
}
track_interface {
enp0s3
}
}
vrrp_instance RH_INT {
state MASTER
interface enp0s8
virtual_router_id 2
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass password123
}
virtual_ipaddress {
10.10.33.254
}
track_script {
check_haproxy
}
track_interface {
enp0s8
}
}
virtual_server 192.168.10.80 80 {
lb_algo rr
lb_kind NAT
real_server 10.10.33.11 80 {
HTTP_GET {
url {
path /check.html
}
}
}
real_server 10.10.33.12 80 {
HTTP_GET {
url {
path /check.html
}
}
}
}