I'm not sure if you still need to perform this operation since you asked it many months ago, but due to the lack of information on internet about this subject I've decided to create a tutorial and post it here to help other people who's facing the same situation .
This is what worked for me.
Basically you'll need the following:
- S3 bucket ( Where you'll upload a shell script to be executed )
- AMI EC2 ( That will execute that script above )
- A Pipeline ( That already imports DynamoDB data to a S3 bucket )
If you already got all of them, then we're good to go!
Follow these steps:
- Add an activity and name it as 'CleanTableJob'

- On CleanTableJob set settings accordingly to this: ( On Runs on -> Select New Resource and name it as CleanDynamodbTableResource)
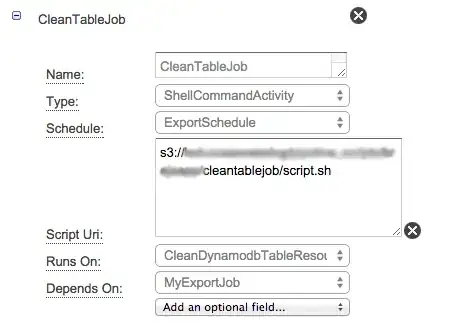
- On CleanDynamodbTableResource set settings accordingly to this:
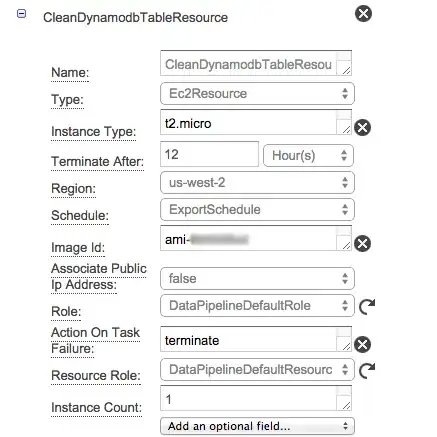
On your S3 bucket you may provide whatever that handles deleting data on DynamoDB like that:
java -jar /home/ec2-user/downloads/dynamodb_truncate_table-1.0-SNAPSHOT.jar
That's it:
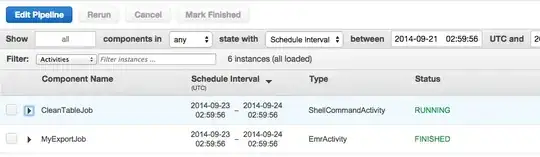
Hope it helps you guys out