Considering the fact that many server-class systems are equipped with ECC RAM, is it necessary or useful to burn-in the memory DIMMs prior to their deployment?
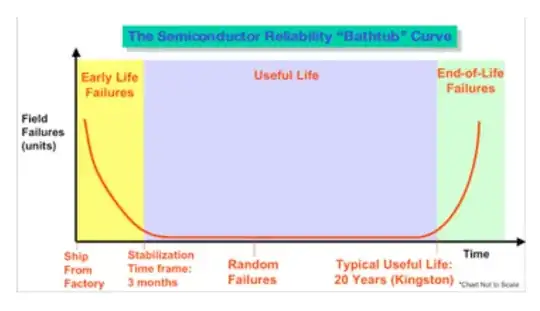
I've encountered an environment where all server RAM is placed through a lengthy burn-in/stress-tesing process. This has delayed system deployments on occasion and impacts hardware lead-time.
The server hardware is primarily Supermicro, so the RAM is sourced from a variety of vendors; not directly from the manufacturer like a Dell Poweredge or HP ProLiant.
Is this a useful exercise? In my past experience, I simply used vendor RAM out of the box. Shouldn't the POST memory tests catch DOA memory? I've responded to ECC errors long before a DIMM actually failed, as the ECC thresholds were usually the trigger for warranty placement.
- Do you burn-in your RAM?
- If so, what method(s) do you use to perform the tests?
- Has it identified any problems ahead of deployment?
- Has the burn-in process resulted in any additional platform stability versus not performing that step?
- What do you do when adding RAM to an existing running server?