I'm trying to optimize the daily backup of a LVM snapshot of a large MySQL database. It works quite ok when I just cp the files (local RAID to other local RAID), with an average speed of ~100MB/s. But since the database files (600GB, most of it in two files of 350GB and 250GB) do not change very much over the course of one day, I thought it would be more efficient to only copy the changed blocks.
I'm using
rsync --safe-links --inplace -crptogx -B 8388608 /source/ /destination/
It did work, was slower than the simple copy, and I did not see any read activity on the target disk. My thought was that rsync would read (8MB) blocks from the source and the destination, compare their checksums and only copy the source block into the target file if it was changed. Am I being mistaken here? Why am I not seeing rsync read from the target in order to determine if the blocks have changed?
Here are some graphs:
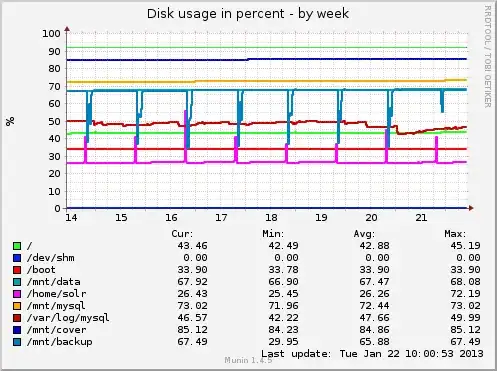
Disk usage: you see that rsync --inplace (only done for the bigger file on the last day) reduced the "dent" in the disk usage of /mnt/backup, meaning that it did indeed update the existing file in place.
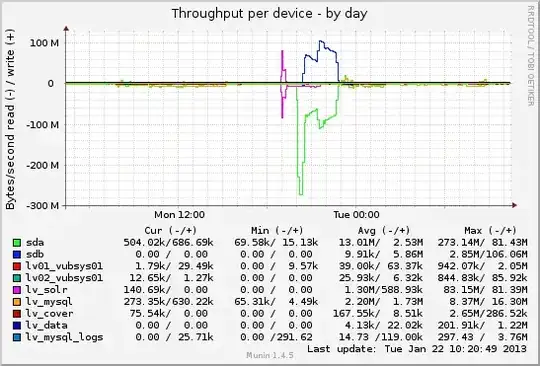
IO stats: the backup is made from sda to sdb. Somehow there is a huge peak in reads from the source, followed by the "normal" read(source)+write(target) activity. I was expecting simultaneous reads from both devices with little write activity on the target.