I'm writing an application that also stores lots and lots of files although mine are bigger and I have 10 million of them that I'll be splitting across multiple directories.
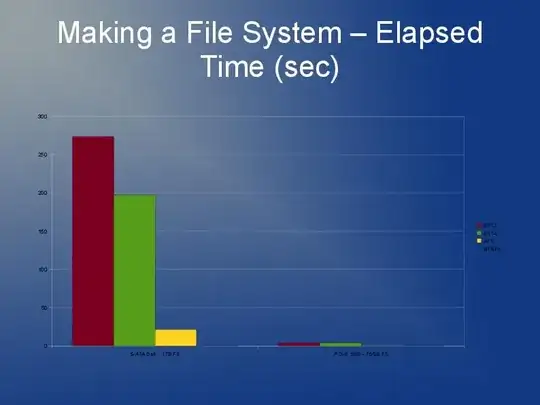
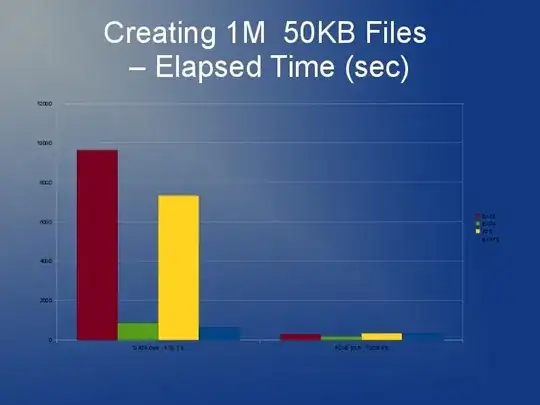
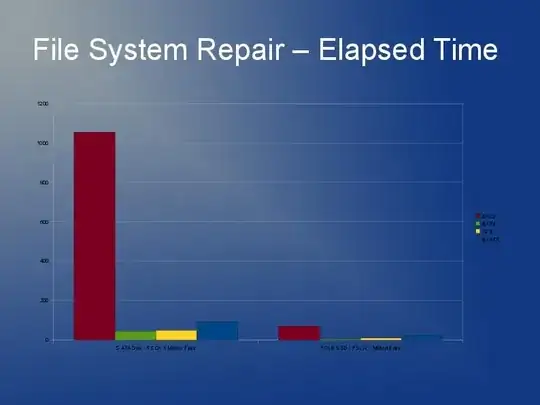
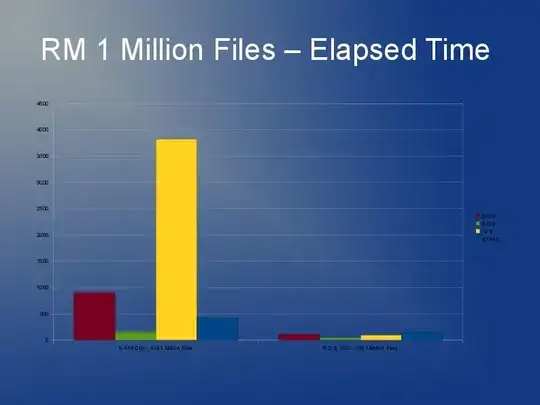
ext3 is slow mainly because of the default "linked list" implementation. So if you have lots of files in one directory, it means opening or creating another is going to get slower and slower. There is something called an htree index that is available for ext3 that reportedly improves things greatly. But, it's only available on filesystem creation. See here: http://lonesysadmin.net/2007/08/17/use-dir_index-for-your-new-ext3-filesystems/
Since you're going to have to rebuild the filesystem anyway and due to the ext3 limitations, my recommendation is that you look at using ext4 (or XFS). I think ext4 is a little faster with smaller files and has quicker rebuilds. Htree index is default on ext4 as far as I'm aware. I don't really have any experience with JFS or Reiser but I have heard people recommend that before.
In reality, I'd probably test several filesystems. Why not try ext4, xfs & jfs and see which one gives the best overall performance?
Something that a developer told me that can speed things up in the application code is not to do a "stat + open" call but rather "open + fstat". The first is significantly slower than the second. Not sure if you have any control or influence over that.
See my post here on stackoverflow.
Storing & accessing up to 10 million files in Linux
there are some very useful answers and links there.