I'm having a serious issue with MySQL 5.5 replication performance between two machines, mostly myISAM tables with statement based replication. The binary logs and mysql data directory are both located on the same Fusion ioDrive.
The problem was a big issue recently when we needed to pause replication for approx. 3 hours. It took about 10 hours to catch up again with no other load.
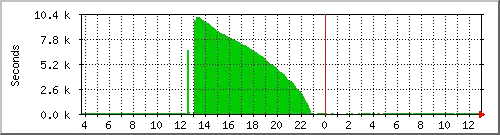
How can I increase the performance of the replication? Machine B is basically idle (little, IO, 2 maxed out cores out of 16, lots of free RAM), as only 1 mySQL thread was writing data. Here are some ideas I had:
- Switch to row-based replication. In tests this only yielded a 10-20% performance boost
- Upgrade to mySQL 5.6 with multi-threaded replication. We could easily split our data into separate databases, and benchmarks seems to indicate this would help, but the code doesn't seem production ready.
- Some configuration variables that will help speed up replication
The primary issue is that if it takes 10h to catch up after pausing for 3h, this means that replication is writing 13h of data in 10h, or is able to write at 130% of the speed of data coming in. I'm looking to at least double writes on the Master machine in the near future, so desperately need a way to improve replication performance.
Machine A:
- Master
- 24GB Ram
- 1.2TB Fusion ioDrive2
- 2x E5620
- Gigabit interconnect
my.cnf:
[mysqld]
server-id=71
datadir=/data_fio/mysqldata
socket=/var/lib/mysql/mysql.sock
tmpdir=/data_fio/mysqltmp
log-error = /data/logs/mysql/error.log
log-slow-queries = /data/logs/mysql/stats03-slowquery.log
long_query_time = 2
port=3306
log-bin=/data_fio/mysqlbinlog/mysql-bin.log
binlog-format=STATEMENT
replicate-ignore-db=mysql
log-slave-updates = true
# Performance Tuning
max_allowed_packet=16M
max_connections=500
table_open_cache = 2048
max_connect_errors=1000
open-files-limit=5000
# mem = key_buffer + ( sort_buffer_size + read_buffer_size ) * max_connections
key_buffer=4G
max_heap_table_size = 1G
tmp_table_size = 4G
myisam_sort_buffer_size = 256M
sort_buffer_size=4M
read_buffer_size=2M
query_cache_size=16M
query_cache_type=2
thread_concurrency=32
user=mysql
symbolic-links=0
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[mysql]
socket=/var/lib/mysql/mysql.sock
[client]
socket=/var/lib/mysql/mysql.sock
Machine B:
- Slave
- 36GB Ram
- 1.2TB Fusion ioDrive2
- 2x E5620
- Gigabit interconnect
my.cnf:
[mysqld]
server-id=72
datadir=/data_fio/mysqldata
socket=/var/lib/mysql/mysql.sock
tmpdir=/data_fio/mysqltmp
log-error = /data/logs/mysql/error.log
log-slow-queries = /data/logs/mysql/stats03-slowquery.log
long_query_time = 2
port=3306
# Performance Tuning
max_allowed_packet=16M
max_connections=500
table_open_cache = 2048
max_connect_errors=1000
open-files-limit=5000
# mem = key_buffer + ( sort_buffer_size + read_buffer_size ) * max_connections
key_buffer=4G
max_heap_table_size = 1G
tmp_table_size = 4G
myisam_sort_buffer_size = 256M
sort_buffer_size=4M
read_buffer_size=2M
query_cache_size=16M
query_cache_type=2
thread_concurrency=32
user=mysql
symbolic-links=0
plugin-load=archive=ha_archive.so;blackhole=ha_blackhole.so
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[mysql]
socket=/var/lib/mysql/mysql.sock
[client]
socket=/var/lib/mysql/mysql.sock