The fingerprinting technology used by the EFF is nothing but the "normal" Javascript functions used by web sites to, well, operate properly. It is possible to report untrue information to the outside, but then you'd risk either "falling behind":
- the untrue information you would need send along changes and yours doesn't, making you unique -- and suspicious;
- the detection techniques change, and you aren't aware of it, so become unique again;
or having a really awkward navigation.
Assuming that you can use Tor or a VPN or an openshell anywhere to tunnel away your IP address, the "safest" practice in my opinion would be to fire up a virtual machine, install a stock Windows Seven on it, and use that for any privacy-sensitive operation. Do not install anything unusual on the machine, and it will truthfully report to be a stock Windows Seven machine, one among a horde of similar machines.
You have also the advantage of the machine being insulated inside your true system, and you being able to snapshot/reinstall it in a flash. Which you can do every now and then - the "you" that did all the navigation before disappears and a fresh "you" appears, with a clean history.
This can be very useful, in that you could keep a "clean" snapshot and always restore it before sensitive operations such as home banking. Some VM's also allow 'sandboxing', i.e., nothing done in the VM will actually permanently change its contents -- all system changes, malware downloaded, virus installed, keyloggers injected, disappear as soon as the virtual machine is powered down.
Any other technique would be no less intrusive, and would entail a considerable work on the browser or on some kind of anonymizing proxy designed not only to sanitize your headers and your Javascript responses (as well as the fonts!), but to do it in a believable way.
In my opinion, not only would the total amount of work be the same (or even more), but it would be a much more complicated and less stable kind of work.
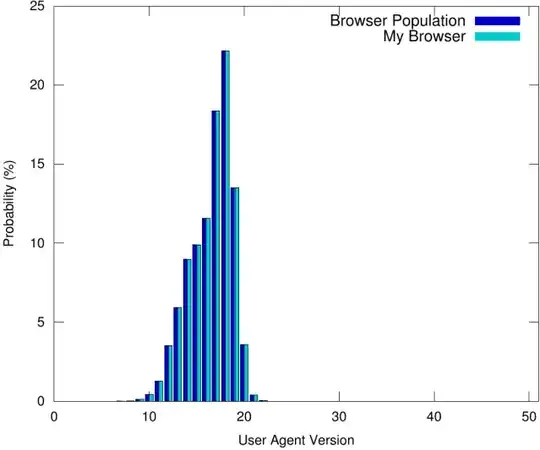
Install the most common OS, keep to the bundled browser and software, resist the temptation of pimping it, and what's to tell that machine apart from literally hundreds of thousands of similar just-installed, never-maintained, computers-are-not-my-thing machines on the Internet?
Update - browsing behaviour and side channels
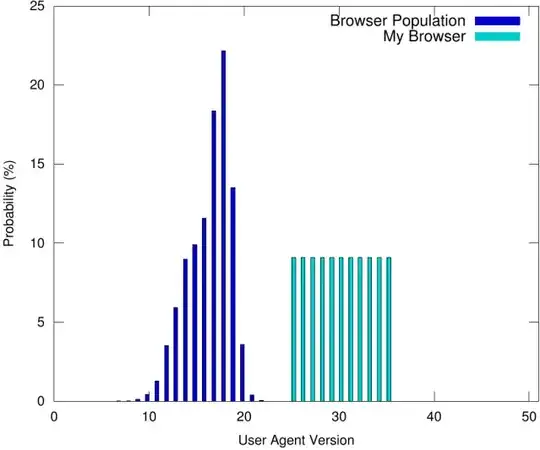
Now I have installed a virtual Windows 7 machine, even upgraded it to Windows 10 as Joe Q. Average would do. I'm not using Tor or VPN; all that an external site can see is that I'm connecting from Florence, Italy. There are thirty thousand connections exactly like mine. Even knowing my provider, that still leaves around nine thousand candidates. Is this sufficiently anonymous?
It turns out not to be the case. There might still be correlations that could be investigated, having sufficient access. For example I'm playing an online game and my typing is sent straight away (character buffered, not line buffered). It becomes possible to fingerprint digram and trigram delays, and with a sufficiently large corpus, establish that online user A is the same person as online user B (within the same online game, of course). The same problem could happen elsewhere.
When I surf the Internet, I tend to always hit the same sites in the same order. And of course I hit my "personal pages" on several sites, e.g. Stack Overflow, regularly. A bespoke distribution of images is already in my browser and is not downloaded at all or is bypassed with a HTTP If-Modified-Since or If-None-Match request. This combination of habit and browser helpfulness also constitutes a signature.
Given the wealth of tagging methods available to websites, it's not safe to assume that only cookies and passive data may have been collected. A site might for example advertise the need to install a font called Tracking-ff0a7a.otf, and the browser would download it dutifully. This file would not necessarily be deleted upon cache clearing, and on subsequent visits it not being re-downloaded would be proof that I've already visited the site. The font could not be the same for all users, but contain a unique combination of glyphs (e.g. the character "1" could contain a "d", "2" could contain an "e", "4" could contain a "d" again - or this could be done with rarely used font code points), and HTML5 can be used to draw a glyph string "12345678" on an invisible canvas and uploading the result as an image. The image would then spell the hex sequence, unique to me, 'deadbeef'. And this is, to all intents and purposes, a cookie.
To fight this, I may need to:
- completely re-snapshot the VM after each browsing session (and reset the modem when I do). Keeping always the same VM wouldn't be enough.
- use several different virtual machines, or browsers, as well as well-known proxy services or Tor (it wouldn't do for me to use a proxy that's unique to me, or for which I'm the only Florence user, for anonymity purposes).
- routinely empty and/or sanitize the browser cache and remember not to always open, say, XKCD immediately after Questionable Content.
- adopt two or more different "personas" for those services I want anonymity in, and those I don't care about, and take care to keep them separated in separated VMs - it only takes one slip, and logging to one believing it's the other, for a permanent link to possibly be established by a savvy enough external agency.
Audio Fingerprint
This is a very ingenious method of "fingerprinting" a system, basically consisting in turning off the audio system, then virtually playing a sound through HTML5 and analysing it back. The result will depend from the underlying audio system, which is tied to the hardware and not even to the browser. Of course, there are ways of fighting this by injecting random noise with a plugin, but this very act might turn out to be damning, since you might well be the only one using such a plugin (and therefore having a noisy audio channel) among the pool matching your "average" configuration.
A better way that I found working, but you'll have to experiment and verify this for yourself, is to use two different VM engines or configurations. For example I have two different fingerprints on the same Dell Precision M6800 in two different VMs using 4 and 8 GB of RAM and two different ICH7 AC97 Audio settings (I suspect that the additional RAM available makes the driver employ different sampling strategies, which in turn yield slightly different fingerprints. I discovered this totally by accident by the way). I assume that I could set up a third VM using VMware and/or maybe a fourth with sound disabled.
What I do not know, though, is whether the fingerprints I did manage to get are revealing the fact it's a VM (do all Windows 7 VirtualBoxen have 50b1f43716da3103fd74137f205420a8c0a845ec as hash of full buffer? Do all M6800's?)
All the above going to show that I'll better have a good reason to want anonymity: because achieving it reliably is going to be a royal pain in the rear end.